存储引擎
存储引擎是一个数据库的核心,主要负责内存、磁盘里数据的管理和维护。
MongoBD的优势,在于其数据模型定义的灵活性、以及可拓展性。但不要忽略,其存储引擎也是插件式的存在,支持不同类型的存储引擎,使用不同的引擎可以解决不同场景的问题,也支持用户去自定义实现存储引擎。
在设计之初,为了实现server与物理存储的解耦,引入存储引擎作为中间插件,类似于MySQL的:基于B+Tree的InnoDB引擎和基于LSM树的RocketsDB引擎,还有快速写入和读取的MyISAM引擎。
目前MongoDB主要有俩种引擎
- WiredTiger 存储引擎:默认的存储引擎为 WiredTiger 存储引擎,非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩等功能。
- In-Memory 存储引擎:In-Memory 存储引擎在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
此外,MongoDB 3.0 提供了 可插拔的存储引擎 API ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
WiredTiger
目前世面上主流的存储引擎大多是基于B+Tree或者LSM Tree实现,类似LevelDB、RocketsDB,都是基于的LSM树。
但WiredTiger引擎与InnoDB一样,使用了B+树作为索引存储结构。
此外,WiredTiger 还支持 LSM(Log Structured Merge) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
MongoDB在3.2之前是B树,之后默认WiredTiger引擎后,便一直是B+树
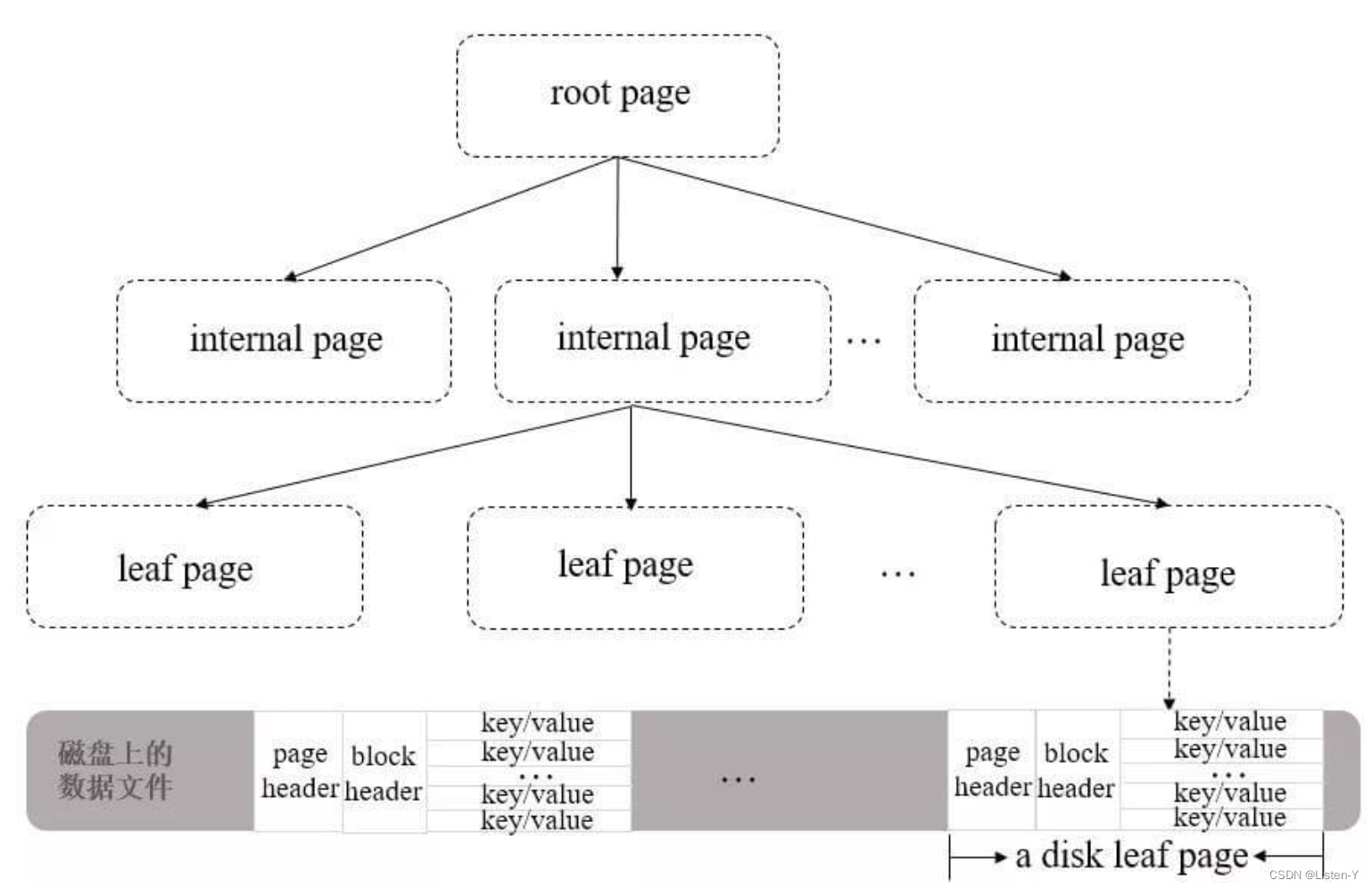
使用 B+ 树时,WiredTiger 以 page 为基本单位往磁盘读写数据。
B+ 树的每个节点为一个 page,共有三种类型的 page:
- root page(根节点):B+ 树的根节点。
- internal page(内部节点):不实际存储数据的中间索引节点。
- leaf page(叶子节点):真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
借助 WiredTiger,MongoDB 支持所有集合和索引的压缩。压缩可以最大限度地减少存储使用,但需要额外的 CPU。
In-Memory
从 MongoDB Enterprise 版本 3.2.6 开始,内存存储引擎是 64 位版本中通用可用性 (GA) 的一部分。除了一些元数据和诊断数据外,内存存储引擎不维护任何磁盘数据,包括配置数据、索引、用户凭据等。
内存存储引擎是非持久性的,不会将数据写入持久性存储。非持久性数据包括应用程序数据和系统数据,例如用户、权限、索引、副本集配置、分片集群配置等。
因此,日志或等待数据 持久化的概念不适用于内存存储引擎。
所以一般不会使用该引擎,其丢数据风险比较高。内存存储引擎在进程关闭后不会保留数据。
但通过避免磁盘 I/O,内存存储引擎可以实现更可预测的数据库操作延迟。
要选择内存存储引擎,请指定:
-
inMemory对于--storageEngine选项,或者 storage.engine如果使用配置文件则进行设置。
-
--dbpath,或者storage.dbPath使用配置文件。虽然内存存储引擎不会将数据写入文件系统,但它会维护--dbpath小型元数据文件和诊断数据以及用于构建大型索引的临时文件。
mongod --storageEngine inMemory --dbpath