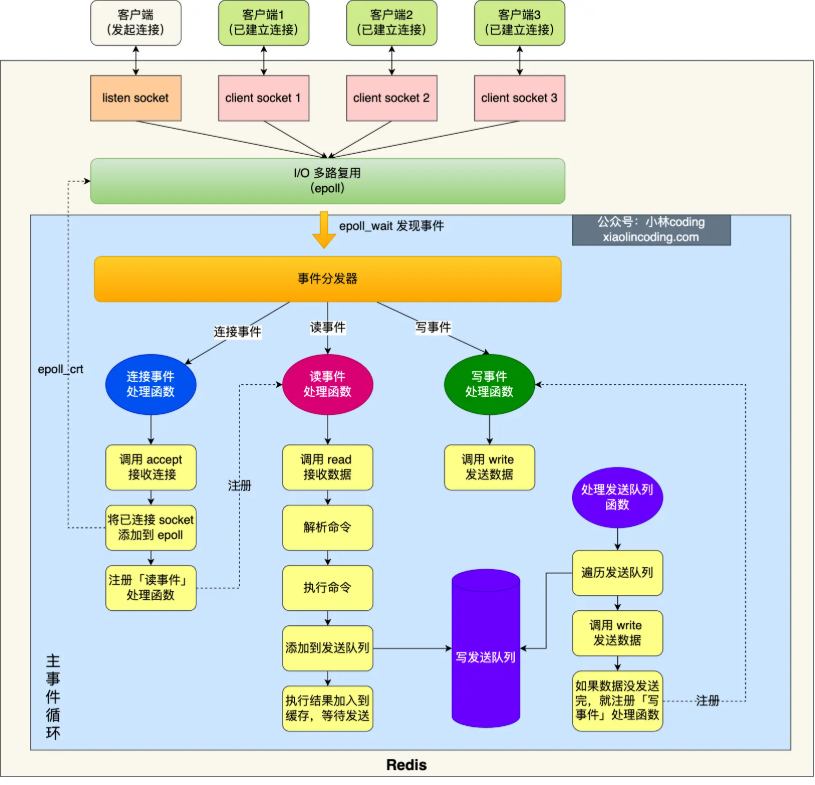
6.0之前单线程处理流程
- 客户端调用GET命令
- 服务端经过IO多路复用,事件处理器
- 服务端调用读事件处理函数,读到客户端传来的命令
- 服务端命令解析
- 服务端执行命令拿到redis在内存中的数据结果,将数据结果放入缓冲区
- 服务端将客户端对象放入写发送队列
- 过一段时间后服务端处理发送队列函数批量处理写发送队列,将客户端对象以及对应结果返回给各个客户端
6.0之前单线程为什么也很快
- 网络不发达时,时间成本主要在网络传输,而不是Redis处理
- Redis读的是内存不是磁盘
- 单个命令执行起来非常快,多线程下加锁等反而添加开销,单线程没有了这些开销反而性能更好
- Redis采用IO多路复用来处理大量客户端Socket请求,即一个线程处理多个IO流
IO多路复用机制
1. 传统逻辑的死结:阻塞(Blocking)
在传统的网络处理逻辑中,如果你要从一个客户端读数据,逻辑是这样的:
- 发出指令:程序告诉内核"我要读这台电脑发来的数据"。
- 原地挂起 :如果数据还没到,程序就会卡在这里,什么也干不了(这叫阻塞)。
- 串行处理:如果你有 1000 个客户端,你就得开 1000 个线程去分别"死等"。
逻辑痛点:线程是昂贵的资源,大部分线程都在睡觉(等待数据),浪费了大量的内存和 CPU 调度。
2. 改进逻辑:轮询(Polling)
为了不"死等",程序可以变成这样:
- 询问:程序挨个问 1000 个客户端:"你数据到了吗?"
- 反馈:没到就问下一个,到了就赶紧处理。
- 循环:疯狂地轮询这 1000 个连接。
逻辑痛点:程序会陷入无意义的忙碌。如果 1000 个连接里只有 1 个有数据,程序也要白白询问另外 999 次,CPU 占用率直接飙升到 100%,却没干正事。
3. 多路复用逻辑:委托与通知(The Multiplexing Logic)
这就是 Redis 采用的逻辑。它引入了一个"中介"(在 Linux 里就是内核的 epoll),把主动询问变成了被动接收通知。
逻辑闭环如下:
- 第一步:委托(Subscription)
Redis 告诉内核:"我要监听这 1000 个客户端的 Socket,它们谁有'读'或者'写'的动作,你帮我记在一张单子上。" - 第二步:休眠(Waiting)
Redis 主线程执行完手头的活儿,就调用一个指令(如epoll_wait)直接睡着了。它不再去挨个问客户端,也不再空转 CPU。 - 第三步:唤醒(Notification)
当其中有 3 个客户端发来了数据,内核会自动把这 3 个 Socket 挑出来,放到一个"就绪名单"里,然后叫醒 Redis 主线程:"喂,这 3 个人有动静了!" - 第四步:精准打击(Processing)
Redis 醒来后,只处理名单里的这 3 个请求。处理完之后,它又回去写委托单,然后继续睡觉。
多路:指的是成千上万个客户端连接(即 Socket 描述符)。
复用:指的是只用一个线程就能处理所有这些连接。
6.0之后采用的多线程模型
网络带宽上去后,网络开销变小了,这时瓶颈有可能在Redis命令处理上。因此需要加快处理速度
在 Redis 6.0 的多线程模型中,"IO 多路复用"和"事件分发"其实依然是单线程的。真正的并行发生在"搬运数据"的环节。
1. Redis 6.0 多线程任务拆解
| 环节 | 运行状态 | 责任人 | 物理逻辑 |
|---|---|---|---|
| IO 多路复用 | 单线程 | 主线程 | 只有主线程去调用 epoll_wait。因为"听铃声"很快,没必要多个人一起听。 |
| 任务分发 | 单线程 | 主线程 | 主线程把就绪的 Socket 分配给各个 IO 线程。 |
| 读取与命令解析 | 多线程并行 | IO 线程 | 多个线程同时从各自的 Socket 读数据,并解析成 Redis 命令。 |
| 命令具体执行 | 单线程串行 | 主线程 | 核心逻辑: 所有的增删改查都在主线程排队执行,确保原子性。 |
| 结果写回 | 多线程并行 | IO 线程 | 多个线程同时把处理结果发回给对应的客户端。 |
2. 为什么执行部分必须保持"单线程"?
这是 Redis 的底线。
- 无锁化:如果执行命令变多线程,Redis 内部的全局哈希表(dict)就必须加锁。
- 一致性 :单线程保证了命令的先后顺序,也保证了像
INCR这种操作在并发下绝对不会出错。