前言
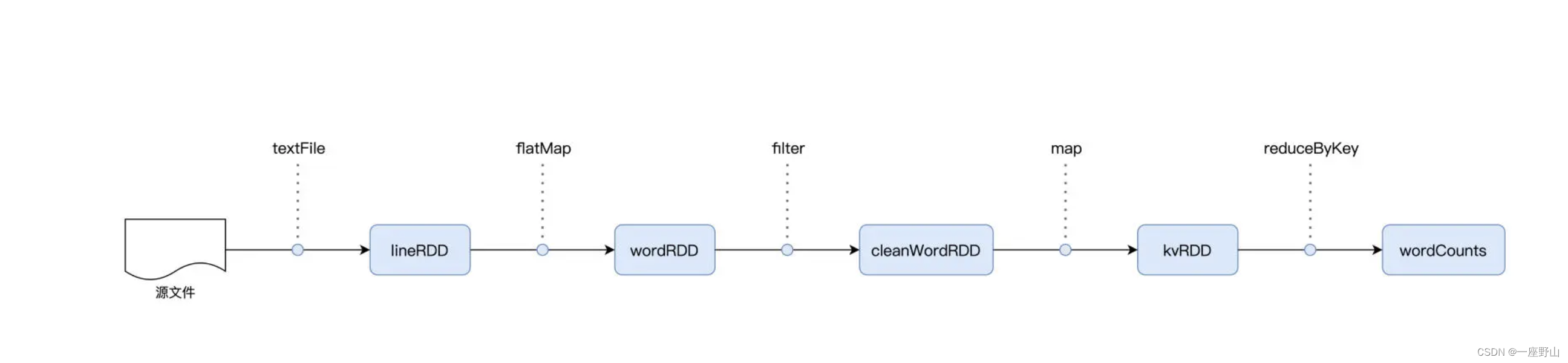
RDD 是 Spark 对于分布式数据集的抽象,每一个 RDD 都代表着一种分布式数据形态。比如 lineRDD,它表示数据在集群中以行(Line)的形式存在;而 wordRDD 则意味着数据的形态是单词,分布在计算集群中。

参数
参数是函数、或者返回值是函数的函数,我们把这类函数统称为"高阶函数"(Higher-order Functions)。换句话说,这 4 个算子,都是高阶函数。

import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
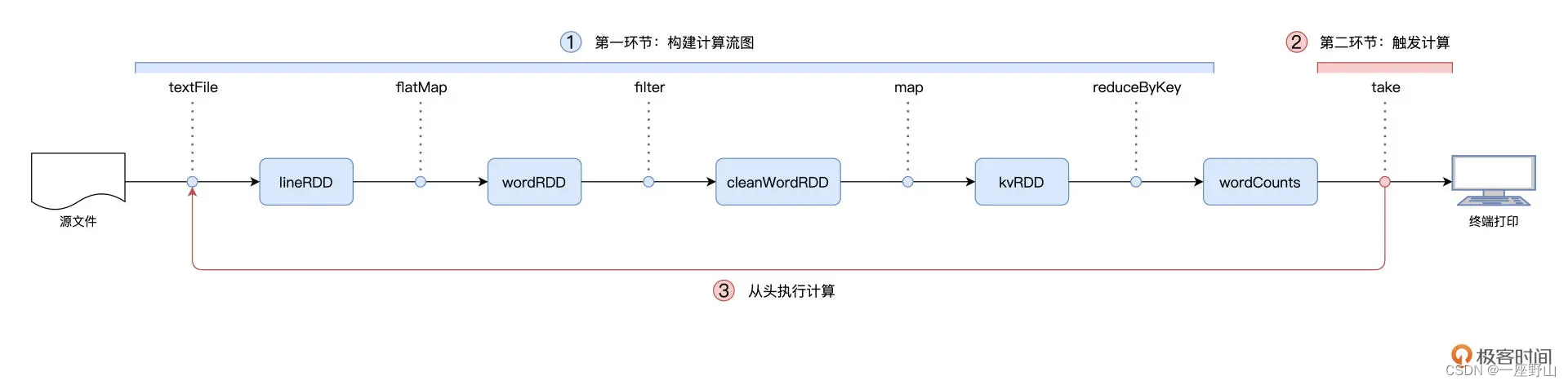
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。开发者需要使用 Transformations 类算子,定义并描述数据形态的转换过程,然后调用 Actions 类算子,将计算结果收集起来、或是物化到磁盘。
换句话说,开发者调用的各类 Transformations 算子,并不立即执行计算,当且仅当开发者调用 Actions 算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作"延迟计算"(Lazy Evaluation)。延迟计算很好地解释了本讲开头的问题:为什么 Word Count 在执行的过程中,只有最后一行代码会花费很长时间,而前面的代码都是瞬间执行完毕的呢?