一、引言
Prometheus Adapter的背景与重要性
在现代的云原生架构中,微服务和容器化技术得到了广泛的应用。这些技术带来了系统灵活性和扩展性的提升,但同时也增加了系统监控和管理的复杂度。Prometheus作为一款开源的监控系统,因其强大的指标收集和查询能力,成为了许多企业和开发者的首选。然而,随着应用场景的多样化和规模的不断扩大,单纯依赖Prometheus内置的功能已经不能满足所有需求。Prometheus Adapter应运而生,作为Prometheus生态系统的重要组成部分,提供了强大的自定义指标扩展和灵活的指标查询能力。
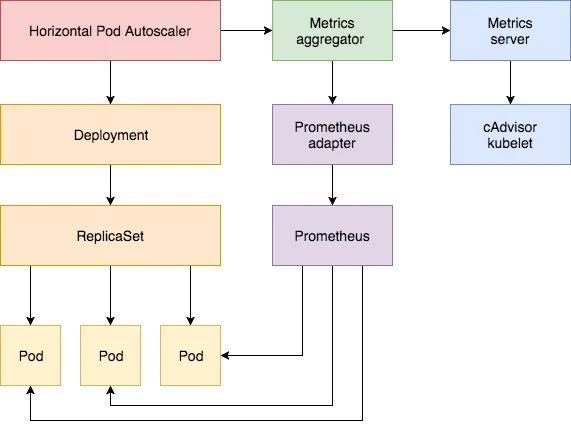
Prometheus Adapter的核心功能是将Prometheus中的监控数据转换为Kubernetes可识别的自定义指标,这对于实现基于自定义指标的自动扩展(Horizontal Pod Autoscaler,HPA)至关重要。在复杂的微服务架构和大规模集群管理中,通过Prometheus Adapter,用户可以自定义监控指标,进行精细化的资源管理和自动化运维,从而提升系统的可靠性和性能。
适用场景与应用需求
Prometheus Adapter主要应用于以下几种场景:
-
自定义指标的自动扩展:在Kubernetes中,HPA主要依赖于CPU和内存等基础资源的使用情况进行自动扩展。但在实际应用中,用户往往需要基于业务指标(如请求响应时间、队列长度等)进行扩展。Prometheus Adapter允许用户定义和使用自定义的Prometheus查询,将这些业务指标转化为HPA可识别的指标,从而实现更精细的扩展策略。
-
多集群环境下的统一监控:在多集群环境中,管理和监控各个集群的资源和应用是一项复杂的任务。通过Prometheus Adapter,用户可以将不同集群的Prometheus数据统一处理和展示,实现跨集群的集中监控和管理,提高运维效率。
-
复杂业务场景下的灵活监控:在一些复杂业务场景中,用户需要对特定的应用或服务进行深入监控。例如,在电商网站中,用户可能需要监控每秒订单数、支付成功率等业务指标。通过Prometheus Adapter,用户可以自定义监控这些特定业务指标,结合Prometheus强大的查询功能,进行灵活多样的监控和分析。
Prometheus Adapter的功能与优势
Prometheus Adapter具备以下几项关键功能和优势:
-
灵活的自定义指标定义:用户可以通过简单的配置文件,定义复杂的Prometheus查询,将结果转化为Kubernetes自定义指标。这使得用户可以根据具体的业务需求,灵活定义和使用各种自定义指标。
-
高效的数据查询与转换:Prometheus Adapter通过高效的查询和数据转换机制,能够快速处理大量监控数据,并将其转换为Kubernetes可识别的格式。这对于大规模集群和高并发场景尤为重要,能够确保监控系统的实时性和可靠性。
-
与Kubernetes的无缝集成:作为Prometheus生态系统的一部分,Prometheus Adapter与Kubernetes有着紧密的集成。用户可以方便地在Kubernetes中部署和管理Prometheus Adapter,实现与现有监控系统的无缝对接,简化运维操作。
-
社区支持与扩展性:Prometheus Adapter作为一个开源项目,有着活跃的社区支持。用户可以通过参与社区贡献,获取最新的功能更新和技术支持。此外,Prometheus Adapter还具备良好的扩展性,用户可以根据自身需求进行二次开发和定制。
二、Prometheus Adapter的基本概念
什么是Prometheus Adapter
Prometheus Adapter是一个开源工具,用于将Prometheus中的监控数据转换为Kubernetes自定义指标。这一转换过程使得Kubernetes可以基于这些自定义指标进行自动扩展(Horizontal Pod Autoscaler,HPA)和其他自定义操作。通过Prometheus Adapter,用户可以将复杂的业务指标引入到Kubernetes的监控和管理体系中,从而实现更灵活、更细致的资源管理。
Prometheus Adapter的出现源于对监控灵活性和扩展性的需求。在传统的监控体系中,监控指标通常固定在CPU、内存等基础资源上。然而,实际的业务需求往往更加复杂多样。例如,在电商网站中,监控订单处理时间、用户请求数等业务指标往往比单纯的资源指标更为重要。Prometheus Adapter通过将Prometheus的强大查询功能与Kubernetes的自定义指标相结合,提供了一个解决这一需求的有效方案。
Prometheus Adapter的架构与工作原理
Prometheus Adapter的架构设计旨在高效、可靠地实现监控数据的转换和传输。其核心组件包括配置解析器、数据查询模块和指标转发模块。以下是对这些组件的详细解析:
-
配置解析器:配置解析器负责读取和解析用户定义的配置文件。这些配置文件中定义了Prometheus查询规则、自定义指标名称和转换逻辑。配置解析器将这些配置转化为内部数据结构,供后续模块使用。
-
数据查询模块:数据查询模块负责与Prometheus实例通信,执行配置文件中定义的查询操作。通过使用Prometheus的HTTP API,数据查询模块可以获取实时的监控数据。数据查询模块需要具备高效的数据处理能力,以应对大规模集群和高并发环境下的查询需求。
-
指标转发模块:指标转发模块负责将查询到的数据转换为Kubernetes可识别的自定义指标格式,并将这些指标推送到Kubernetes API服务器。通过与Kubernetes的Metric API集成,指标转发模块确保这些自定义指标可以被Kubernetes中的其他组件(如HPA)识别和使用。
Prometheus Adapter与Prometheus的关系与区别
Prometheus Adapter与Prometheus之间存在紧密的关系,但两者的功能定位和使用场景有所不同:
-
功能定位:Prometheus是一个强大的监控系统,负责数据的采集、存储和查询。它通过抓取各类监控目标的数据,提供丰富的查询和告警功能。Prometheus Adapter则是一个数据转换工具,负责将Prometheus中的监控数据转换为Kubernetes自定义指标。其核心功能是将Prometheus强大的查询能力引入到Kubernetes的监控和管理体系中。
-
使用场景:Prometheus主要用于各类系统和应用的监控,其使用场景包括基础设施监控、应用性能监控和业务指标监控等。Prometheus Adapter则主要用于Kubernetes环境中,特别是在需要基于自定义指标进行自动扩展和其他自定义操作的场景中。通过Prometheus Adapter,用户可以将复杂的业务指标引入到Kubernetes的自动化管理流程中。
-
技术实现:Prometheus通过抓取各类监控目标的HTTP端点,收集和存储时序数据。它的架构设计强调高效的数据采集和查询能力。Prometheus Adapter则通过调用Prometheus的HTTP API,执行预定义的查询操作,并将结果转换为Kubernetes自定义指标。两者在技术实现上有明显的区别,但通过API接口实现了紧密的集成。
三、部署与安装
环境要求
在部署Prometheus Adapter之前,需要确保以下环境和软件组件已经正确安装和配置:
- Kubernetes集群:
-
版本要求:Kubernetes 1.14及以上
-
集群内应至少包含一个主节点和若干工作节点
-
已正确配置kubectl命令行工具,并能够正常访问集群
- Prometheus实例:
-
版本要求:Prometheus 2.0及以上
-
Prometheus应已经部署并在集群中运行,确保能够采集和存储监控数据
-
确保Prometheus的HTTP API可用,并且集群内的组件能够访问该API
- Helm(可选):
-
版本要求:Helm 3.0及以上
-
Helm用于简化Prometheus Adapter的安装和管理,但也可以通过手动部署YAML文件进行安装
安装步骤
Prometheus Adapter的安装过程可以通过两种方式完成:使用Helm Chart进行安装或手动部署YAML文件。以下将详细介绍这两种安装方式。
使用Helm Chart进行安装
-
添加Prometheus Adapter的Helm仓库:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update -
安装Prometheus Adapter:
helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace monitoring
-
验证安装:安装完成后,检查Prometheus Adapter的Pod是否成功启动:
kubectl get pods -n monitoring -l app=prometheus-adapter
手动部署YAML文件
- 下载Prometheus Adapter的部署文件:
可以从Prometheus Adapter的GitHub仓库获取最新的部署文件:
git clone https://github.com/kubernetes-sigs/prometheus-adapter.git
cd prometheus-adapter/deploy/manifests-
部署Prometheus Adapter:
kubectl apply -f .
-
验证安装:
同样,检查Prometheus Adapter的Pod是否成功启动:
kubectl get pods -n custom-metrics配置详解
安装完成后,需要对Prometheus Adapter进行详细的配置,以确保其能够正确地与Prometheus和Kubernetes集成。配置主要通过一个YAML文件进行定义,其中包括Prometheus的地址、自定义查询规则、以及Kubernetes API服务器的相关设置。
配置文件结构
Prometheus Adapter的配置文件通常包含以下几个部分:
- MetricMappings:
定义Prometheus查询规则和Kubernetes自定义指标的映射关系。
- Rules:
定义自定义的Prometheus查询规则,包括指标名称、查询语法等。
- ResourceRules:
定义与Kubernetes资源相关的查询规则,如节点、Pod等。
- MetricsRelabelings:
定义如何从Prometheus查询结果中提取和转换指标。
以下是一个示例配置文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: custom-metrics-config
namespace: custom-metrics
data:
config.yaml: |
rules:
default: false
seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'如何定义自定义的指标
在配置文件中,可以通过rules部分定义自定义的Prometheus查询规则。以下是一个详细的示例:
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'-
seriesQuery:定义需要查询的Prometheus指标。
-
resources:定义如何将Prometheus指标中的标签映射到Kubernetes资源。
-
name:定义转换后的自定义指标名称。
-
metricsQuery:定义具体的Prometheus查询语法,用于计算自定义指标的值。
不同数据源的适配
除了Prometheus,Prometheus Adapter还可以适配其他数据源,如Thanos、VictoriaMetrics等。通过在配置文件中定义不同的数据源地址和查询规则,可以实现多数据源的灵活适配。例如:
prometheus:
url: http://thanos-query:9090/
path: /api/v1/query常见问题与解决方案
在部署和配置Prometheus Adapter的过程中,可能会遇到一些常见问题。以下是几种典型问题及其解决方案:
无法连接到Prometheus实例
解决方案:
-
检查Prometheus的服务地址和端口,确保Prometheus Adapter的配置文件中地址正确无误。
-
使用curl或wget命令测试Prometheus API的可访问性。
自定义指标无法被Kubernetes识别
解决方案:
-
确保自定义查询规则符合Prometheus Adapter的配置规范,并且Prometheus中确实存在相应的指标数据。
-
使用Prometheus的表达式浏览器(Expression Browser)验证查询语法,确保查询结果正确。
查询结果为空
解决方案:
-
检查Prometheus中的原始数据,确保数据确实存在并且符合查询条件。
-
调整查询窗口或查询条件,确保能够匹配到预期的数据。
查询语法错误
解决方案:
-
使用Prometheus的表达式浏览器验证查询语法,确保语法正确。
-
检查配置文件中的查询规则,确保没有语法错误或拼写错误。
curl http://prometheus-server:9090/api/v1/query?query=sum(rate(http_requests_total[5m])) by (namespace, pod)
验证配置
完成配置后,可以通过以下步骤验证Prometheus Adapter的工作情况:
-
检查Prometheus Adapter的日志:
kubectl logs -n custom-metrics
-
验证自定义指标:
使用kubectl命令查看自定义指标是否成功导入Kubernetes API服务器:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .- 测试HPA配置:
创建一个基于自定义指标的HPA资源,验证其是否能够正常工作:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: custom-metrics-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 100通过以上步骤,可以验证Prometheus Adapter的安装和配置是否正确,以及自定义指标是否能够被Kubernetes正常识别和使用。
四、Prometheus Adapter的配置
配置文件详解
Prometheus Adapter的配置文件主要用于定义如何将Prometheus中的监控数据转换为Kubernetes可识别的自定义指标。配置文件通常使用YAML格式,包含多个部分,每一部分都负责特定的配置任务。
核心配置组件
- metricsRelabelings:
-
用于重新标记和筛选Prometheus中的原始指标。
-
例子:
metricsRelabelings:
- sourceLabels: [name]
separator: ;
regex: '(.*)'
targetLabel: metric_name
replacement: '${1}'
action: replace
- rules:
-
定义如何从Prometheus查询中生成自定义指标。
-
例子:
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'
- resourceRules:
-
用于定义与Kubernetes资源相关的查询规则,例如节点和Pod的指标。
-
例子:
resourceRules:
cpu:
name:
matches: "^(.*)_cpu_usage"
as: "custom_cpu_usage"
metricsQuery: 'sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)'
如何定义自定义的指标
自定义指标的定义过程涉及编写Prometheus查询,并将其转换为Kubernetes自定义指标。以下是详细步骤:
步骤1:编写Prometheus查询
首先,在Prometheus中编写查询以获取所需的数据。例如,要获取每秒HTTP请求数,可以使用以下查询:
sum(rate(http_requests_total[5m])) by (namespace, pod)步骤2:定义配置规则
在Prometheus Adapter的配置文件中,定义对应的查询规则和指标转换逻辑。例如:
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'上述配置中:
-
seriesQuery:指定Prometheus中的原始指标。 -
resources:定义如何将Prometheus指标中的标签映射到Kubernetes资源。 -
name:指定自定义指标的命名规则。 -
metricsQuery:定义Prometheus查询语法,计算自定义指标的值。
步骤3:部署配置文件
将配置文件部署到Kubernetes中:
kubectl apply -f custom-metrics-config.yaml不同数据源的适配
Prometheus Adapter不仅可以与Prometheus集成,还可以适配其他数据源,例如Thanos和VictoriaMetrics。配置方法类似,通过定义不同的数据源地址和查询规则,实现灵活的多数据源适配。
适配Thanos
Thanos是一个用于Prometheus高可用性、长时间存储和多集群聚合的解决方案。可以通过以下配置适配Thanos:
prometheus:
url: http://thanos-query:9090/
path: /api/v1/query在这种配置中,url指向Thanos查询服务的地址,path指定查询API路径。
适配VictoriaMetrics
VictoriaMetrics是一个高性能的开源时间序列数据库,兼容Prometheus。适配VictoriaMetrics的配置示例如下:
prometheus:
url: http://victoriametrics:8428/
path: /api/v1/query高级配置技巧
动态标签处理
Prometheus Adapter支持动态标签处理,通过metricsRelabelings和rules部分的配置,可以灵活处理Prometheus指标中的标签。例如:
metricsRelabelings:
- sourceLabels: [__name__]
separator: ;
regex: '(.*)'
targetLabel: metric_name
replacement: '${1}'
action: replace分片与聚合
在大规模集群中,可以通过分片和聚合策略,提升查询性能和数据处理效率。例如:
rules:
- seriesQuery: 'container_cpu_usage_seconds_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_cpu_usage_seconds_total"
as: "${1}_cpu_usage"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'上述配置通过sum(rate(...))实现数据的聚合处理,适用于大规模数据场景。
常见问题与解决方案
在配置和使用Prometheus Adapter时,可能会遇到一些常见问题。以下是几种典型问题及其解决方案:
自定义指标查询失败
问题描述:配置的自定义指标无法在Kubernetes中查询到。
解决方案:
-
检查Prometheus查询语法,确保其在Prometheus表达式浏览器中能够返回预期结果。
-
确认Prometheus Adapter配置文件的语法和内容正确。
-
查看Prometheus Adapter的日志,排查错误信息。
kubectl logs -n custom-metrics
连接Prometheus失败
问题描述:Prometheus Adapter无法连接到Prometheus实例。
解决方案:
-
确认Prometheus实例的地址和端口正确无误。
-
检查网络连接,确保Prometheus Adapter所在Pod能够访问Prometheus实例。
指标名称冲突
问题描述:配置的自定义指标名称与现有指标名称冲突。
解决方案:
-
在定义自定义指标时,使用独特的命名规则,避免与现有指标名称重复。
-
通过
name配置部分,灵活调整自定义指标名称。name:
matches: "^(.*)_total"
as: "${1}_custom_per_second"
验证配置
完成配置后,可以通过以下步骤验证Prometheus Adapter的工作情况:
-
检查Prometheus Adapter的日志:
kubectl logs -n custom-metrics
-
验证自定义指标:使用kubectl命令查看自定义指标是否成功导入Kubernetes API服务器:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
-
测试HPA配置:创建一个基于自定义指标的HPA资源,验证其是否能够正常工作:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: custom-metrics-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
metrics:- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 100
- type: Pods
通过以上步骤,可以验证Prometheus Adapter的配置是否正确,自定义指标是否能够被Kubernetes正常识别和使用。
五、Prometheus Adapter实践案例
在这一部分,我们将通过实际案例展示Prometheus Adapter的应用,帮助用户理解如何在不同场景中配置和使用Prometheus Adapter,以满足复杂的监控需求。以下是三个详细的实践案例。
案例一:Kubernetes集成Prometheus Adapter
背景
在Kubernetes集群中,水平自动扩展(HPA)主要依赖于CPU和内存的使用情况。然而,在实际应用中,许多业务场景需要基于其他指标(如请求数、响应时间等)进行扩展。通过Prometheus Adapter,可以将自定义的Prometheus指标引入到Kubernetes HPA中,实现更精细的扩展策略。
目标
通过Prometheus Adapter,将HTTP请求数这一业务指标引入到Kubernetes HPA中,实现基于请求数的自动扩展。
步骤
-
配置Prometheus Adapter
首先,编写Prometheus Adapter的配置文件,定义从Prometheus中获取HTTP请求数的查询规则。
apiVersion: v1
kind: ConfigMap
metadata:
name: custom-metrics-config
namespace: custom-metrics
data:
config.yaml: |
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'
部署配置文件:
kubectl apply -f custom-metrics-config.yaml- 部署Prometheus Adapter
使用Helm或YAML文件部署Prometheus Adapter。
helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace custom-metrics- 验证自定义指标
确认Prometheus Adapter已经成功导入自定义指标:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .- 配置HPA
创建一个HPA资源,基于自定义的HTTP请求数指标进行扩展:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: http-requests-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 100部署HPA配置文件:
kubectl apply -f http-requests-hpa.yaml效果
通过上述步骤,Kubernetes集群中的应用将基于HTTP请求数的变化进行自动扩展,从而确保在高负载时有足够的资源来处理请求,同时在低负载时释放资源,优化资源利用率。
案例二:结合自定义指标进行业务监控
背景
在实际业务场景中,某电商平台需要监控每秒订单数,以确保在高峰期能够及时扩展资源,避免系统过载。
目标
通过Prometheus Adapter,将订单数这一业务指标引入到Kubernetes HPA中,实现基于订单数的自动扩展。
步骤
- 配置Prometheus Adapter
编写Prometheus Adapter的配置文件,定义从Prometheus中获取订单数的查询规则。
apiVersion: v1
kind: ConfigMap
metadata:
name: order-metrics-config
namespace: custom-metrics
data:
config.yaml: |
rules:
- seriesQuery: 'orders_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'部署配置文件:
kubectl apply -f order-metrics-config.yaml- 部署Prometheus Adapter
使用Helm或YAML文件部署Prometheus Adapter。
helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace custom-metrics- 验证自定义指标
确认Prometheus Adapter已经成功导入自定义指标:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .- 配置HPA
创建一个HPA资源,基于自定义的订单数指标进行扩展:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: orders-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-service
minReplicas: 2
maxReplicas: 20
metrics:
- type: Pods
pods:
metric:
name: orders_per_second
target:
type: AverageValue
averageValue: 50部署HPA配置文件:
kubectl apply -f orders-hpa.yaml效果
通过上述步骤,电商平台的订单处理服务将基于每秒订单数的变化进行自动扩展,确保在订单高峰期能够及时扩展资源,保证服务的可用性和响应速度。
案例三:多集群环境下的Prometheus Adapter应用
背景
在多集群环境中,需要统一监控和管理不同集群的资源和应用。通过Prometheus Adapter,可以实现跨集群的统一监控和管理。
目标
通过Prometheus Adapter,实现多个Kubernetes集群的统一监控和管理。
步骤
- 配置多集群环境
假设已有两个Kubernetes集群:Cluster A和Cluster B,分别部署了Prometheus实例。
- 在每个集群中部署Prometheus Adapter
在Cluster A中:
helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace custom-metrics在Cluster B中:
helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace custom-metrics- 配置跨集群Prometheus查询
在每个集群的Prometheus Adapter配置文件中,分别定义从对方集群获取数据的查询规则。例如,在Cluster A的配置文件中:
prometheus:
url: http://prometheus-cluster-b:9090/
path: /api/v1/query在Cluster B的配置文件中:
prometheus:
url: http://prometheus-cluster-a:9090/
path: /api/v1/query- 定义跨集群自定义指标
在Cluster A的Prometheus Adapter配置文件中,定义从Cluster B获取的指标查询规则:
rules:
- seriesQuery: 'cluster_b_http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'在Cluster B的Prometheus Adapter配置文件中,定义从Cluster A获取的指标查询规则:
rules:
- seriesQuery: 'cluster_a_http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>[5m])) by (<<.GroupBy>>)'- 验证配置
在两个集群中,分别验证Prometheus Adapter是否成功导入跨集群自定义指标:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .效果
通过上述配置,两个集群中的Prometheus Adapter能够互相获取对方的监控数据,实现跨集群的统一监控和管理。在多集群环境中,用户可以通过自定义指标,实现对不同集群资源的灵活管理和自动扩展,提高系统的整体监控效率和响应能力。
文章转载自: ++techlead_krischang++