刚刚看到《AI高考作文出圈,网友票选天工AI居首》,没想到在Huggingface中发现了Skywork大模型。天工大模型由昆仑万维自研,是国内首个对标ChatGPT的双千亿级大语言模型,天工大模型通过自然语言与用户进行问答式交互,AI生成能力可满足文案创作、知识问答、代码编程、逻辑推演、数理推算等多元化需求。2023年11月3日,天工大模型通过备案,面向全社会开放服务。
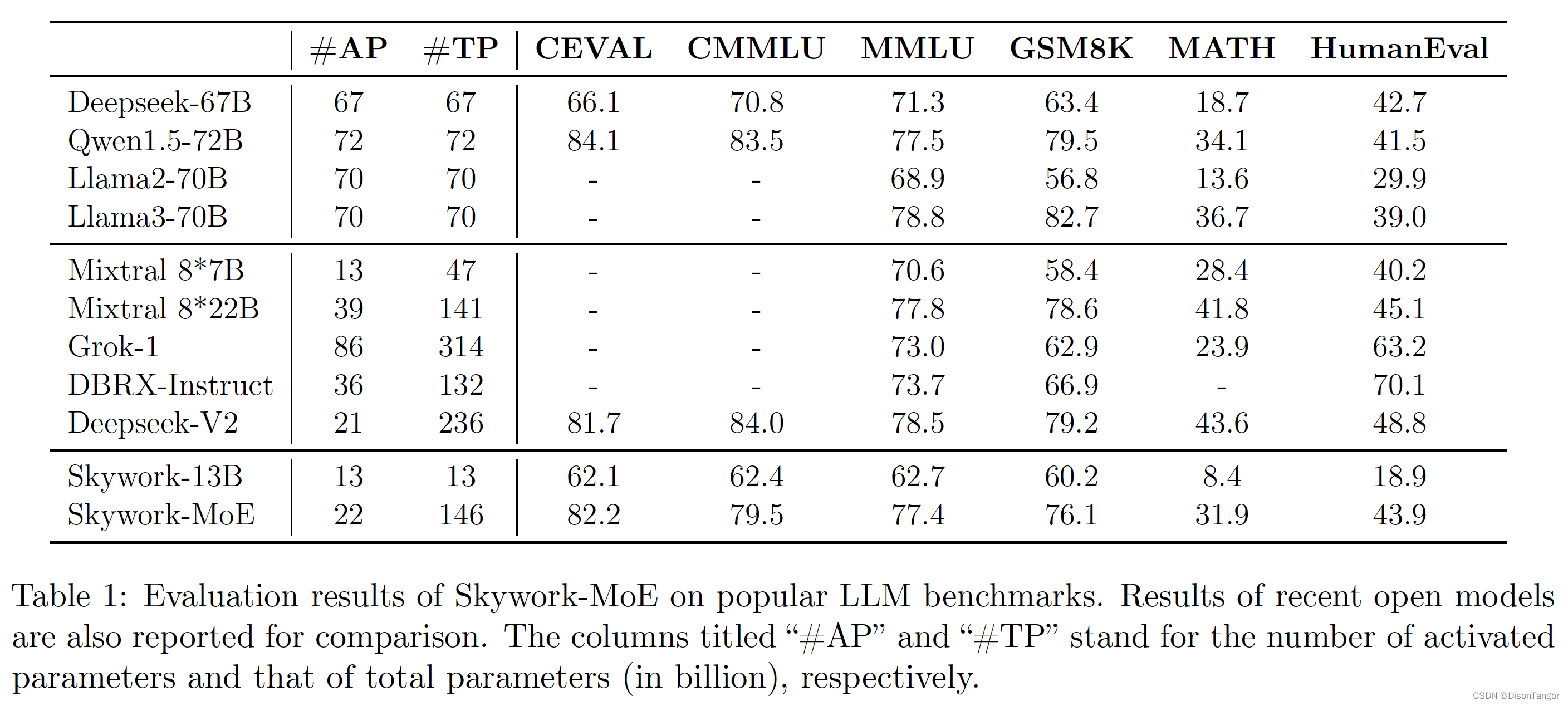
Skywork-MoE 是一个高性能专家混合(MoE)模型,拥有 1460 亿个参数、16 个专家和 220 亿个激活参数。该模型由 Skywork-13B 模型预先存在的密集检查点初始化而成。
引入了两项创新技术:门控对数归一化(Gating Logit Normalization)可增强专家的多样化,自适应辅助损失系数(Adaptive Auxiliary Loss Coefficients)可对辅助损失系数进行特定层调整。
Skywork-MoE 与参数更多或激活参数更多的模型(如 Grok-1、DBRX、Mistral 8*22 和 Deepseek-V2)相比,性能相当或更优。
代码
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Skywork/Skywork-MoE-Base", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("Skywork/Skywork-MoE-Base", trust_remote_code=True)
inputs = tokenizer('陕西的省会是西安', return_tensors='pt').to(model.device)
response = model.generate(inputs.input_ids, max_length=128)
print(tokenizer.decode(response.cpu()[0], skip_special_tokens=True))
"""
陕西的省会是西安。
西安,古称长安、镐京,是陕西省会、副省级市、关中平原城市群核心城市、丝绸之路起点城市、"一带一路"核心区、中国西部地区重要的中心城市,国家重要的科研、教育、工业基地。
西安是中国四大古都之一,联合国科教文组织于1981年确定的"世界历史名城",美媒评选的世界十大古都之一。地处关中平原中部,北濒渭河,南依秦岭,八水润长安。下辖11区2县并代管西
"""
inputs = tokenizer('陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州', return_tensors='pt').to(model.device)
response = model.generate(inputs.input_ids, max_length=128)
print(tokenizer.decode(response.cpu()[0], skip_special_tokens=True))
"""
陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州,湖北的省会是武汉,湖南的省会是长沙,安徽的省会是合肥,江西的省会是南昌,江苏的省会是南京,浙江的省会是杭州,福建的省会是福州,广东的省会是广州,广西的省会是南宁,四川的省会是成都,贵州的省会是贵阳,云南的省会是昆明,山西的省会是太原,山东的省会是济南,河北的省会是石家庄,辽宁的省会是沈阳,吉林的省会是长春,黑龙江的
"""vLLM
安装依赖
pip3 install xformers vllm-flash-attn 安装vllm
$ git clone https://github.com/SkyworkAI/vllm.git
$ cd vllm
$ MAX_JOBS=8 python3 setup.py install文本生成
from vllm import LLM, SamplingParams
model_path = 'Skywork/Skywork-MoE-Base'
prompts = [
"The president of the United States is",
"The capital of France is",
]
sampling_params = SamplingParams(temperature=0.3, max_tokens=256)
llm = LLM(
model=model_path,
kv_cache_dtype='auto',
tensor_parallel_size=8,
gpu_memory_utilization=0.95,
enforce_eager=True,
trust_remote_code=True,
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")