文章目录
- 引言:
- 数据清洗的具体步骤
- 数据清洗的具体方法和示例
-
- [1. 处理缺失值](#1. 处理缺失值)
- [2. 去除重复数据](#2. 去除重复数据)
- [3. 修正数据格式](#3. 修正数据格式)
- [4. 处理异常值](#4. 处理异常值)
- [5. 标准化和归一化](#5. 标准化和归一化)
- [6. 处理不一致的数据](#6. 处理不一致的数据)
- [7. 转换数据类型](#7. 转换数据类型)
- [8. 数据集成](#8. 数据集成)
- 总结
引言:
数据清洗是数据处理和分析的关键步骤,旨在确保数据的准确性、一致性和完整性。数据清洗包括处理缺失值、去除重复数据、修正数据格式、处理异常值等步骤。以下是数据清洗的具体方法和举例说明。
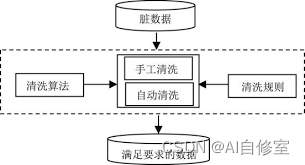
数据清洗的具体步骤
- 处理缺失值
- 去除重复数据
- 修正数据格式
- 处理异常值
- 标准化和归一化
- 处理不一致的数据
- 转换数据类型
- 数据集成
数据清洗的具体方法和示例
1. 处理缺失值
方法:
- 删除缺失值:适用于缺失值较少且随机分布的情况。
- 填补缺失值:使用均值、中位数、众数填补,或使用插值、回归等方法填补。
- 标记缺失值:用特定值(如 -1 或 "Unknown")标记缺失数据。
示例 :
假设我们有一个包含员工信息的数据集,其中有些记录的年龄缺失。
python
import pandas as pd
import numpy as np
# 创建示例数据集
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, np.nan, 30, np.nan, 22],
'Department': ['HR', 'Finance', 'IT', 'Marketing', 'IT']
}
df = pd.DataFrame(data)
# 填补缺失值 - 使用均值填补
df['Age'].fillna(df['Age'].mean(), inplace=True)
print(df)2. 去除重复数据
方法:
- 去除完全重复的行:删除所有列值都相同的重复行。
- 去除部分重复的行:根据特定列(如ID或名称)去除重复行。
示例 :
假设我们有一个包含订单信息的数据集,其中有重复的订单记录。
python
# 创建示例数据集
data = {
'OrderID': [1, 2, 2, 3, 4],
'Product': ['A', 'B', 'B', 'C', 'D'],
'Quantity': [1, 2, 2, 1, 3]
}
df = pd.DataFrame(data)
# 去除重复行
df.drop_duplicates(inplace=True)
print(df)3. 修正数据格式
方法:
- 转换数据格式:将日期、时间、货币等字段转换为统一格式。
- 去除空白和特殊字符:清理字符串中的多余空格和特殊字符。
示例 :
假设我们有一个包含日期信息的数据集,其中日期格式不统一。
python
# 创建示例数据集
data = {
'Date': ['2021-01-01', '01/02/2021', '2021.03.03', '2021-04-04']
}
df = pd.DataFrame(data)
# 统一日期格式
df['Date'] = pd.to_datetime(df['Date'])
print(df)4. 处理异常值
方法:
- 去除异常值:删除明显的异常数据。
- 替换异常值:使用合理的数值替换异常值。
- 标记异常值:标记异常数据以便进一步分析。
示例 :
假设我们有一个包含销售数据的数据集,其中有些记录的销售量异常。
python
# 创建示例数据集
data = {
'Product': ['A', 'B', 'C', 'D', 'E'],
'Sales': [100, 200, 3000, 400, 500] # 3000 是异常值
}
df = pd.DataFrame(data)
# 去除异常值 - 使用四分位数法去除异常值
Q1 = df['Sales'].quantile(0.25)
Q3 = df['Sales'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df = df[(df['Sales'] >= lower_bound) & (df['Sales'] <= upper_bound)]
print(df)5. 标准化和归一化
方法:
- 标准化:将数据转换为均值为0、标准差为1的标准正态分布。
- 归一化:将数据缩放到特定范围(如0到1)。
示例 :
假设我们有一个包含不同量纲的特征的数据集。
python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 创建示例数据集
data = {
'Feature1': [10, 20, 30, 40, 50],
'Feature2': [1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
# 标准化
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
# 归一化
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print("Standardized Data:")
print(df_standardized)
print("\nNormalized Data:")
print(df_normalized)6. 处理不一致的数据
方法:
- 统一数据格式和标准:统一度量单位、编码方式等。
- 合并相同类别:将表示同一类别的不同标签合并。
示例 :
假设我们有一个包含部门信息的数据集,其中部门名称不一致。
python
# 创建示例数据集
data = {
'Employee': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Department': ['HR', 'Finance', 'IT', 'marketing', 'it']
}
df = pd.DataFrame(data)
# 统一部门名称
df['Department'] = df['Department'].str.lower().replace({'marketing': 'it'})
print(df)7. 转换数据类型
方法:
- 转换数据类型:将数值型字符串转换为数值类型,日期字符串转换为日期类型等。
示例 :
假设我们有一个包含数值数据的数据集,但数据类型是字符串。
python
# 创建示例数据集
data = {
'Value': ['1', '2', '3', '4', '5']
}
df = pd.DataFrame(data)
# 转换数据类型
df['Value'] = df['Value'].astype(int)
print(df)8. 数据集成
方法:
- 合并数据集:将多个数据源整合成一个完整的数据集。
- 连接数据表:根据主键或外键进行表连接。
示例 :
假设我们有两个数据集,一个包含员工信息,另一个包含部门信息。
python
# 创建示例数据集
data1 = {
'EmployeeID': [1, 2, 3],
'Name': ['Alice', 'Bob', 'Charlie'],
'DepartmentID': [101, 102, 101]
}
data2 = {
'DepartmentID': [101, 102],
'DepartmentName': ['HR', 'Finance']
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 合并数据集
df_merged = pd.merge(df1, df2, on='DepartmentID')
print(df_merged)总结
数据清洗是数据处理和分析中的重要步骤,旨在确保数据的准确性、一致性和完整性。通过处理缺失值、去除重复数据、修正数据格式、处理异常值、标准化和归一化、处理不一致的数据、转换数据类型和数据集成,可以大大提高数据的质量,为后续的数据分析和建模提供坚实的基础。