摘 要 : 本文整理自俞航翔、陈婧敏、黄鹏程老师所撰写的大状态作业调优实践指南。由于内容丰富,本文分享终篇状态报错与启停慢篇,主要分为以下四个部分:
-
检查点和快照超时的诊断与调优
-
作业快速启动和扩缩容方案
-
总结
-
阿里云企业级存储后端Gemini 特点补充介绍
前篇:Flink⼤状态作业调优实践指南:Datastream 作业篇
中篇:Flink⼤状态作业调优实践指南:Flink SQL 作业篇
Tips: 点击**「阅读原文」** 跳转阿里云实时计算 Flink~
检查点和快照超时的诊断与调优
6.1 运行原理
Flink 的状态管理核心机制依赖于 Chandy-Lamport 算法,以确保数据的一致性和可靠性。在此框架下,检查点和快照的执行过程可以概括为两个主要阶段:
(1)同步阶段:此阶段的关键在于 Barrier 的对齐和同步资源的维护。Barrier 作为一种特殊的数据记录,在算子之间传递时,其对齐的时间与数据记录的延迟成正相关关系。
(2)异步阶段:在这一阶段,算子将本地状态信息上传至远程的持久化存储系统。上传时间的长短与状态数据的大小直接相关。
当 Flink 作业面临反压问题时,同步阶段的执行可能会变得缓慢,从而导致检查点和快照超时。因此,在遇到检查点和快照超时问题,并且监测到作业存在反压时,首先应当参考 Flink 的"运行时性能调优策略",优先解决反压问题,以提高作业的整体效率和稳定性。
6.2 问题诊断方法
在解决反压问题后,若检查点与快照仍出现超时现象,首先应分析同步阶段的对齐时间是否过长,随后考虑是否由庞大的状态数据引起。
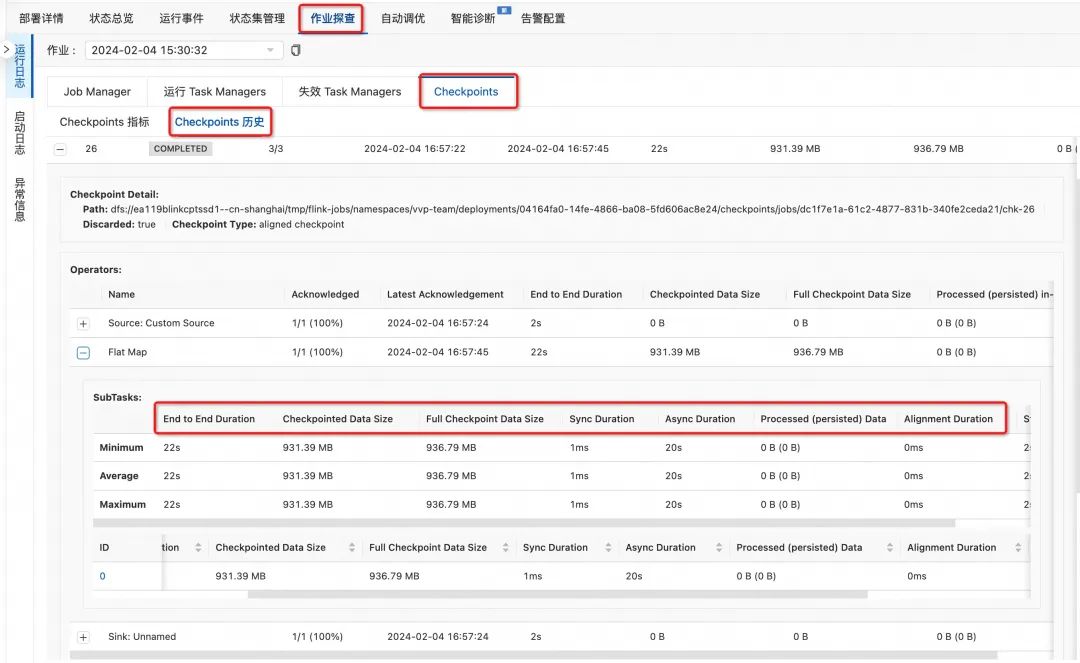
■ Checkpoint UI
通过这个UI,用户可以详细分析检查点和快照超时原因,具体操作如下:
在 "作业探查 - Checkpoints - Checkpoints 历史" 页面,可以在不同级别(作业、算子、单并发)观察 Checkpoint 指标,我们着重观察超时的 Checkpoint 的异常算子或正在进行的 Checkpoint 的算子:
(1)其 "Sync Duration" 和 "Alignment Duration" 是否较长,如是,则基本判定有瓶颈在同步阶段上,需要优先解决同步阶段问题
(2)其 "Async Duration" 是否较长,以及其 "Checkpointed Data Size" 是否较大,如是,则可基本判定其瓶颈在异步阶段状态上传上
■ Checkpoint 指标
用户通过查看监控指标中 lastCheckpointDuration 和 lastCheckpointSize 来粗粒度分析历史 Checkpoint 的耗时和大小。
6.2 调优方法
在进行性能调优之前,首先要确保运行时性能达到预期。如果当前性能水平不足,应优先根据"运行时性能优化指南"进行调整。在满足基本性能要求后,为了进一步提高检查点和快照的效率,可以考虑以下三种策略:
(1)使用 Unaligned Checkpoint 和 Buffer Debloating:这一方法可以有效解决因等待数据对齐而导致的超时问题,适用于各种规模的作业,这里仅作简要介绍)
(2)增加运行时的并发资源:通过增加并发资源,可以减少单个并发任务的状态量,从而加速异步快照的处理流程。
(3)使用原生快照:相比标准快照,原生快照生成速度更快,存储占用更小。
|------------|---------------------------------------------|------------------------------------|----------------|
| 使用场景 | 方案 | 实践方式 | 注意事项 |
| 检查点或快照同步超时 | 使用 Unaligned Checkpoint 和 Buffer Debloating | 运行参数中配置参数,可参考8 | |
| 检查点或快照异步超时 | 增加并发 | 在资源配置或细粒度资源配置中增加并发7 | |
| 快照异步超时 | 使用原生快照 | 对运行中的作业,选择 "创建快照" - "原生格式" 即可9 | 原生快照无法保证跨大版本兼容 |
Unaligned Checkpoint 和 Buffer Debloating的使用和介绍可以参考以下帖子
Flink Aligned Checkpoint和Unaligned Checkpoint原理详解-CSDN博客
一文搞懂 Flink 网络流控与反压机制_flink kafka 反压-CSDN博客
作业快速启动和扩缩容方案
7.1 运行原理
在进行作业恢复时,从检查点或快照中恢复相较于无状态启动,关键在于高效地从远程持久存储中下载状态文件并重建状态引擎。这一步骤需要执行大量的输入输出操作,容易成为恢复过程中的效率瓶颈,可能会造成作业的长时间停滞。
7.2 问题诊断方法
在作业启动或进行扩容操作期间,若发现作业长时间停留在初始化阶段,应首先诊断是否存在初始化瓶颈。以下是推荐的诊断与优化步骤:
(1)使用诊断工具分析算子状态:利用"线程转储"、"线程动态分析"和"火焰图"等工具,检查初始化阶段的算子线程栈。重点关注线程栈是否长时间处于等待状态,尤其是在Gemini等状态存储系统上的操作。
(2)识别状态算子的初始化问题:如果发现某个算子长时间处于初始化状态,且该算子涉及状态处理,那么可以推断问题可能出在状态的下载或重建过程中。
一旦确定作业初始化的瓶颈与大状态处理有关,接下来应参考后续章节提供的优化策略进行针对性调整。通过这些方法,可以有效地识别并解决作业初始化过程中的瓶颈问题,从而提高作业的运行效率和稳定性。
7.3 调优方法
为了优化作业启动和扩容效率,我们提供了两种高效策略:
(1)Local Recovery:本地恢复技术,通过在本地同时存储快照,减少恢复过程中的数据下载需求。在本地磁盘空间充裕的情况下,这是首选方案。
(2)Gemini 智能懒加载和延迟剪裁:作为平台核心技术Gemini,即使面对大规模状态的作业,也能仅通过下载必要的元数据快速启动,实现对用户数据的即时处理。随后,系统将通过异步下载和智能裁剪技术,有效处理远程检查点文件,显著降低作业中断时间,提升效率超过90%。
| 方案 | 实践方式 | 注意事项 |
|---|---|---|
| Local Recovery:本地备份快照加速恢复 | 运行参数中配置:state.backend.local-recovery: true 10 | 适用于作业 Failover 或者动态参数更新的场景,手动停止重启无法生效会多占用部分本地磁盘资源 |
| Gemini 智能懒加载和延迟剪裁:异步状态恢复方案 | 运行参数中配置:state.backend.gemini.file.cache.download.type: LazyDownloadOnRestore | 作业刚启动后的一小段时间内,会异步下载状态文件,作业性能逐步恢复,因此一开始性能会稍微低一些 |
总结
在上中下篇章中,我们深入探讨了Apache Flink中的状态管理机制,以及当一个作业持有大状态时在阿里云实时计算Flink版中的如何进行问题诊断和优化。Flink的状态管理是一个复杂而关键的领域,涉及到作业的性能、稳定性和资源利用等多个方面。通过对这些机制分析和优化策略的深入理解和正确应用,结合阿里云Flink提供的产品能力,希望用户可以有效地优化Flink作业,应对大规模状态作业带来的挑战,实现更高效、更可靠的实时数据处理。
附录1:阿里云企业级存储后端Gemini 特点补充介绍
GeminiStateBackend是一款面向流计算场景的KV存储引擎,作为实时计算Flink版产品的默认状态存储后端(StateBackend)。其针对流计算场景进行了全新的架构和数据结构设计,Gemini 在大状态作业下也有良好的表现,其具备如下优势特点:
性能卓越:在 Nexmark 测试中,Gemini 所有用例的性能都比 RocksDB 更优,其中约一半用例的性能领先 RocksDB 70%以上。目前在阿里巴巴集团内部的实时计算平台和公有云的实时计算Flink服务中,共计超 50WCU 的有状态作业使用 Gemini 存储引擎,其中也包含了数十 TB ~ 上百 TB 的大状态作业,助力实时计算用户高效完成业务目标。
自适应 KV 分离,极大优化大状态下双流/多流 Join 性能:Stateful Join 算子利用状态存储明细数据,因此是大状态作业的常客。基于大量场景 Join 成功率较低、或者状态数据Value较长的特点,Gemini 推出了 KV 分离的能力从而极大优化这些场景下的性能。在 Nexmark 双流 Join 的测试中,作业吞吐能力可以提升50% ~ 70% 以上,且该功能可以完全自适应调整,不需要用户额外配置调优。
轻量级 Snapshot,显著加速大状态作业检查点和快照完成:Gemini 通过支持更细粒度的 Snapshot,同时解耦检查点与 LSM 的 Compaction 机制,让检查点和快照变得更加稳定快速。此外,Gemini 通过支持 Native Incremental Savepoint,结合实时计算产品提供了原生快照,让其性能趋近检查点,极大提高了快照可用性。
三篇综合参考文献
1 深入分析 Flink SQL 工作机制:
https://developer.aliyun.com/article/765311
2 在使用 EvenTimeTemporalJoin 时不会产生 ChangelogNormalize,详见 FLINK-29849:
https://issues.apache.org/jira/browse/FLINK-29849
3 Flink SQL Secrets: Mastering the Art of Changelog Event Out-of-Orderness:
4 如何消除流查询的不确定性影响:
5 高性能 FlinkSQL 优化技巧:
https://help.aliyun.com/zh/flink/user-guide/optimize-flink-sql?spm=a2c4g.11186623.0.0.2790ff53sQpyuy
6 taskmanager.memory.managed.fraction 配置说明:
7 作业资源配置方式:
https://help.aliyun.com/zh/flink/user-guide/configure-deployment-resources
8 Unaligned Checkpoint 和 Buffer Debloating 使用方式:
https://nightlies.apache.org/flink/flink-docs-
master/docs/ops/state/checkpointingunderbackpressure
9 原生快照使用方式:
https://nightlies.apache.org/flink/flink-docs-master/docs/ops/state/checkpointingunderbackpressure
10 Local Recovery 配置说明:
11 状态相关介绍: