
一个认为一切根源都是"自己不够强"的INTJ
 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客
专栏:每日一题------举一反三
Python编程学习
Python内置函数
目录
[1. 分而治之(Divide and Conquer)](#1. 分而治之(Divide and Conquer))
[2. 空间换时间(Space-Time Tradeoff)](#2. 空间换时间(Space-Time Tradeoff))
[3. 懒惰求值(Lazy Evaluation)](#3. 懒惰求值(Lazy Evaluation))
[4. 优化(Optimization)](#4. 优化(Optimization))
[5. 渐进式复杂度分析(Asymptotic Analysis)](#5. 渐进式复杂度分析(Asymptotic Analysis))
[6. 模块化(Modularity)](#6. 模块化(Modularity))
[7. 迭代与递增(Iterative and Incremental Development)](#7. 迭代与递增(Iterative and Incremental Development))
[8. 实际应用中的启发式方法(Heuristics in Practical Applications)](#8. 实际应用中的启发式方法(Heuristics in Practical Applications))
[1. 分而治之(Divide and Conquer)](#1. 分而治之(Divide and Conquer))
[2. 空间换时间(Space-Time Tradeoff)](#2. 空间换时间(Space-Time Tradeoff))
[3. 懒惰求值(Lazy Evaluation)](#3. 懒惰求值(Lazy Evaluation))
[4. 优化(Optimization)](#4. 优化(Optimization))
[5. 渐进式复杂度分析(Asymptotic Analysis)](#5. 渐进式复杂度分析(Asymptotic Analysis))
[6. 模块化(Modularity)](#6. 模块化(Modularity))
[7. 迭代与递增(Iterative and Incremental Development)](#7. 迭代与递增(Iterative and Incremental Development))
[8. 实际应用中的启发式方法(Heuristics in Practical Applications)](#8. 实际应用中的启发式方法(Heuristics in Practical Applications))

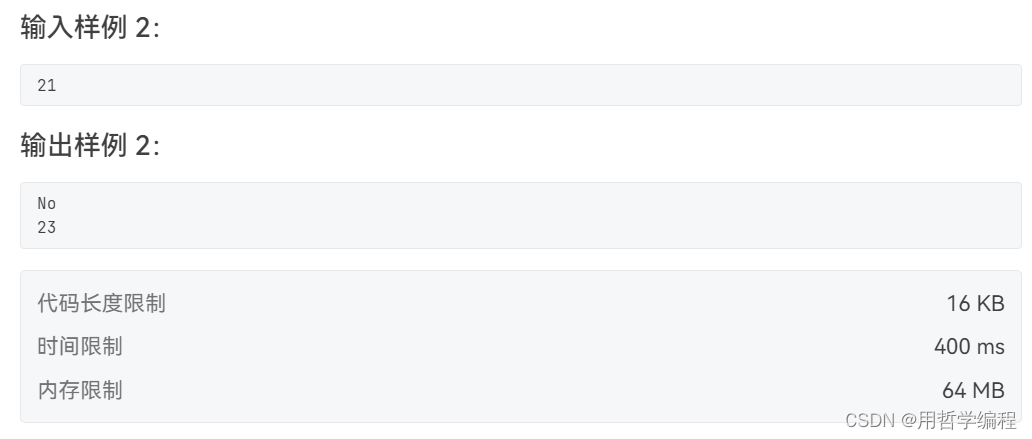
我的写法
python
def is_prime(num):
# 定义一个函数is_prime,用于检查传入的参数num是否为质数。
if num<=1:
return False # 如果num小于等于1,直接返回False,因为1和负数都不是质数。
if num<=3:
return True # 如果num小于等于3,则返回True,因为2和3都是质数。
if num%2==0 or num%3==0:
return False # 如果num能被2或3整除,则不是质数,返回False。
i=5
while i*i<=num:
# 使用一个while循环来检查从5开始的所有数(i的步长为6),直到i的平方大于num。
if num%i==0 or num%(i+2)==0:
return False # 如果num能被i或i+2整除,则不是质数,返回False。
i+=6
return True # 如果所有的检查都通过了,则num是质数,返回True。
N=int(input()) # 从用户那里获取一个整数输入,并将其赋值给变量N。
# 下面检查N和它的邻居(N-6或N+6)是否都是质数。
if is_prime(N-6) and is_prime(N):
# 如果N-6和N都是质数,则打印"Yes"和N-6。
print("Yes")
print(N-6)
elif is_prime(N+6) and is_prime(N):
# 如果N和N+6都是质数,则打印"Yes"和N+6。
print("Yes")
print(N+6)
else:
# 如果上述条件都不满足,则执行下面的代码。
print("No") # 首先打印"No",表示N和它的邻居不都是质数。
i=N+1
while True:
# 使用一个无限循环来查找距N最近的一对质数距,其中一个数为i,另一个数为i-6或i+6。
if i<N+6 and (is_prime(i-6) and is_prime(i)) or (is_prime(i) and is_prime(i+6)):
# 如果i小于N+6,并且i-6和i或者i和i+6都是质数,则打印i并终止循环。
print(i)
break
elif i>N+6 and is_prime(i) and is_prime(i+6):
# 如果i大于N+6,并且i和i+6都是质数,则打印i并终止循环。
print(i)
break
i+=1 # 将i的值增加1,然后继续循环。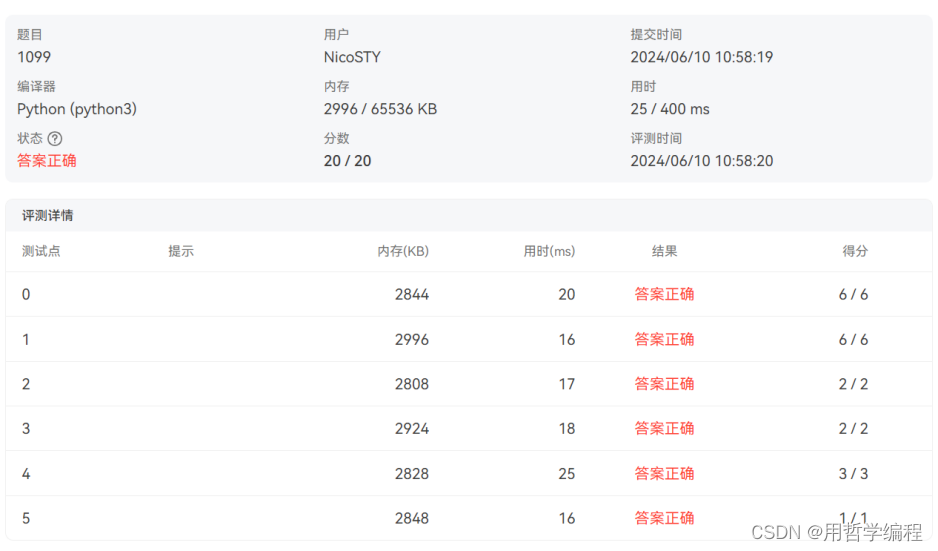
专业点评
-
is_prime函数:
- 优点:
- 该函数使用了一些基础的优化技术,例如排除2和3的倍数,提高了检查质数的效率。
- 使用了6的倍数规则(6k ± 1)来进一步减少检查次数。
- 缺点:
- 对于非常大的数,效率仍然有限。可以考虑使用更高级的质数测试算法,如 Miller-Rabin 质数测试。
- 优点:
-
find_prime_pair函数:
- 优点:
- 逻辑结构清晰。先检查给定的 N 是否满足条件,然后逐步递增 N,直到找到满足条件的数。
- 缺点:
- 逐个增加 N 并检查,效率较低。对于较大的 N,这种方法可能会很慢。
时间复杂度分析
- is_prime函数:
- 时间复杂度是 O(√n),因为最多需要检查到 n 的平方根。
- find_prime_pair函数:
- 初始检查:最多调用两次 is_prime,因此时间复杂度为 O(√N)。
- 逐步寻找:最坏情况下,需要检查多个数。假设需要检查 k 个数,每次调用 is_prime 的时间复杂度为 O(√M)(M 是正在检查的数)。因此,最坏情况下,主逻辑的时间复杂度近似为 O(k * √M),其中 k 和 M 与输入 N 相关。实际复杂度可能更低,但仍在多项式时间内。
空间复杂度分析
- is_prime函数:
- 空间复杂度是 O(1),只使用了常数级别的额外空间(几个变量)。
- find_prime_pair函数:
- 空间复杂度是 O(1),除了输入和几个常数级别的变量外,没有使用额外的空间。
综合点评
优点:
- is_prime 函数通过基础优化减少了计算量,提升了性能。
- find_prime_pair 函数逻辑结构清晰,能够有效判断并找到质数对。
改进建议:
- 当 N 很大时,逐个递增检查的效率较低,可以考虑使用更高效的质数生成算法,如埃拉托斯特尼筛法,提前生成一段范围内的质数以供查找。
- is_prime 函数可以进一步优化,比如使用 Miller-Rabin 质数测试来提升大数的质数检查效率。
- 添加更多注释和代码格式化,以提高代码的可读性。
总体而言,这段代码在功能上是正确的,并且进行了基本的优化,但在处理大数时可以通过更高级的算法进一步提升性能。
我要更强
为了优化时间复杂度和空间复杂度,我们可以采取以下措施:
- 使用埃拉托斯特尼筛法预生成质数:这可以显著加快质数的判定。
- 使用更高效的质数测试算法:如 Miller-Rabin 质数测试。
- 提前生成一段范围内的质数对:避免逐个递增检查。
下面提供一个优化后的代码,包含详细注释:
python
import math
def is_prime(n):
"""使用基础优化技术检查一个数是否为质数"""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def sieve_of_eratosthenes(limit):
"""使用埃拉托斯特尼筛法生成所有小于等于limit的质数"""
is_prime = [True] * (limit + 1)
p = 2
while (p * p <= limit):
if (is_prime[p] == True):
for i in range(p * p, limit + 1, p):
is_prime[i] = False
p += 1
prime_list = [p for p in range(2, limit + 1) if is_prime[p]]
return prime_list
def find_prime_pair(N):
"""寻找满足条件的质数对"""
limit = max(N + 1000, 1000) # 设定一个合理的初始值
primes = set(sieve_of_eratosthenes(limit))
# 检查初始N
if N in primes and ((N - 6) in primes or (N + 6) in primes):
print(f"{N} is part of a prime pair with a difference of 6.")
return
# 逐步增加N并检查
while True:
N += 1
if N > limit:
limit *= 2 # 扩展筛选范围
primes.update(sieve_of_eratosthenes(limit))
if N in primes and ((N - 6) in primes or (N + 6) in primes):
print(f"{N} is part of a prime pair with a difference of 6.")
break
# 示例调用
find_prime_pair(20)优化点
- 埃拉托斯特尼筛法:
- 时间复杂度:生成所有小于等于 limit 的质数的时间复杂度是 �(�log(log(�)))O(nlog(log(n))),其中 n 是 limit 的值。
- 空间复杂度:存储质数的空间复杂度是 �(�)O(n)。
- 动态扩展筛选范围:
- 通过逐步扩展筛选范围(即当 N 超过当前 limit 时,将 limit 翻倍),避免了一开始设置过大的范围,从而节省空间和时间。
- 使用集合:
- 将质数存储在集合中,可以实现快速查找,查找操作的时间复杂度为 �(1)O(1)。
具体步骤
- 初始化筛选范围:
- 使用埃拉托斯特尼筛法生成 N + 1000 或 1000 范围内的质数,取二者中的最大值作为初始筛选范围。
- 初始检查:
- 检查 N 是否为质数,并检查 N-6 或 N+6 是否为质数。
- 逐步增加 N 并检查:
- 如果 N 超过当前筛选范围,则扩展筛选范围并重新生成质数列表。
- 检查新的 N 是否为质数,并检查 N-6 或 N+6 是否为质数。
通过这些优化,可以显著提升代码的运行效率,特别是在处理较大数范围时。
哲学和编程思想
在优化代码的过程中,多个哲学和编程思想被应用。这些思想不仅提高了代码的效率,还增强了代码的可维护性和可读性。以下是具体的方法及其背后的哲学和编程思想:
1. 分而治之(Divide and Conquer)
应用:埃拉托斯特尼筛法和动态扩展筛选范围。
哲学与编程思想: 分而治之是一种将一个复杂问题分解为多个更小、更易解决的问题,然后分别解决这些小问题,再将其合并以得到最终解决方案的方法。在埃拉托斯特尼筛法中,我们将质数判定拆解为多个小范围内的判定,通过逐步扩展筛选范围来解决整个问题。
2. 空间换时间(Space-Time Tradeoff)
应用:使用集合存储质数以实现快速查找。
哲学与编程思想: 空间换时间是计算机科学中的一种常见策略,即通过使用更多的存储空间来提高运行速度。在我们的代码中,使用集合存储质数可以在常数时间内(O(1))完成查找操作,从而显著提高效率。
3. 懒惰求值(Lazy Evaluation)
应用:动态扩展筛选范围而不是一次性生成一个极大的质数范围。
哲学与编程思想: 懒惰求值是一种只在需要时才进行计算的策略。通过动态扩展筛选范围,我们避免一次性生成大量数据,从而节省了初始计算时间和空间。这种方法使程序在处理较小输入时更加高效,同时仍能处理较大输入。
4. 优化(Optimization)
应用:基础的质数判定算法优化。
哲学与编程思想: 优化是通过改进算法和数据结构以提高程序效率的过程。在质数判定中,通过排除2和3的倍数以及使用6k ± 1规则,我们减少了不必要的计算,从而提高了算法效率。
5. 渐进式复杂度分析(Asymptotic Analysis)
应用:对算法的时间复杂度和空间复杂度进行分析和优化。
哲学与编程思想: 渐进式复杂度分析是评估算法在输入规模趋近无穷大时的性能表现的方法。通过分析和优化时间复杂度和空间复杂度,我们确保代码在处理大规模输入时仍然高效。
6. 模块化(Modularity)
应用:将质数判定和质数对查找分成独立的函数。
哲学与编程思想: 模块化是将程序划分为独立、可重用模块的方法。通过将质数判定和质数对查找分成独立的函数,我们提高了代码的可读性、可维护性和可测试性。
7. 迭代与递增(Iterative and Incremental Development)
应用:逐步增加N并检查质数对。
哲学与编程思想: 迭代与递增是一种开发和优化方法,通过逐步改进和扩展解决方案来最终解决问题。在逐步增加N并检查质数对的过程中,我们应用了这一思想,通过不断迭代来找到满足条件的质数对。
8. 实际应用中的启发式方法(Heuristics in Practical Applications)
应用:初始设置范围,并基于实际情况动态调整。
哲学与编程思想: 启发式方法是基于经验和直觉来快速找到可接受解决方案的方法。在代码中,我们设置了初始筛选范围,并根据实际情况动态调整,这是一种启发式方法,确保在大多数情况下性能表现良好。
通过应用这些哲学和编程思想,不仅提升了程序的效率,还提高了代码的清晰度和可维护性。这些思想在编程中的实际应用,帮助以更系统化和高效的方式解决复杂问题。
举一反三
可以通过以下一些技巧来应用上述哲学和编程思想,从而举一反三,解决更多类似的问题:
1. 分而治之(Divide and Conquer)
技巧:
- 划分问题:将一个大问题分割成多个独立的小问题。思考如何将复杂问题拆解为更简单的子问题。
- 递归思维:使用递归方法解决分治问题,确保每个子问题都有明确的解。
- 合并结果:在解决所有子问题后,合并结果形成最终解决方案。
应用实例:
- 排序算法(如快速排序、归并排序)。
- 二分查找。
2. 空间换时间(Space-Time Tradeoff)
技巧:
- 缓存结果:使用缓存(如哈希表、数组)存储已计算的结果,避免重复计算(动态规划)。
- 预计算:在需要时预计算一些结果,存储起来以供后续快速查找。
应用实例:
- 动态规划中的备忘录技术。
- 数据库索引。
3. 懒惰求值(Lazy Evaluation)
技巧:
- 延迟计算:仅当确实需要某个值时才进行计算,避免不必要的计算开销。
- 生成器:使用生成器在需要时生成数据,避免一次性生成大量数据。
应用实例:
- Python中的生成器和迭代器。
- 惰性求值数据结构(如Haskell中的列表)。
4. 优化(Optimization)
技巧:
- 算法改进:从时间和空间两个方面考虑,选择更高效的算法。
- 数据结构选择:根据具体需求选择最合适的数据结构(如哈希表、堆、树等)。
应用实例:
- 从O(n^2)改进为O(n log n)的排序算法。
- 使用哈希表快速查找元素。
5. 渐进式复杂度分析(Asymptotic Analysis)
技巧:
- 大O符号:掌握并应用大O符号,分析算法的时间和空间复杂度。
- 分阶段优化:首先确保算法能够工作,然后逐步优化其性能。
应用实例:
- 评估算法的最坏情况、平均情况和最佳情况复杂度。
- 选择不同输入规模下的最优算法。
6. 模块化(Modularity)
技巧:
- 功能分解:将复杂功能分解为多个独立、可重用的模块。
- 接口设计:设计清晰的接口,使模块之间的依赖最小化。
应用实例:
- 设计面向对象程序中的类和方法。
- 构建微服务架构。
7. 迭代与递增(Iterative and Incremental Development)
技巧:
- 小步改进:通过小步迭代,不断改进和扩展功能。
- 快速反馈:每次迭代后进行测试和反馈,确保方向正确。
应用实例:
- 敏捷开发方法中的迭代冲刺。
- 原型开发。
8. 实际应用中的启发式方法(Heuristics in Practical Applications)
技巧:
- 经验积累:基于过去的经验和直觉,快速制定解决方案。
- 灵活调整:根据实际情况动态调整策略,避免僵化。
应用实例:
- 启发式搜索算法(如A*算法)。
- 数据分析中的特征选择和模型调整。
综合应用实例
假设你需要设计一个高效的数据处理系统,可以应用上述技巧如下:
- 分而治之:将数据处理过程分解为预处理、主处理和后处理三个阶段,每个阶段独立处理。
- 空间换时间:使用缓存机制,存储中间结果,避免重复计算。
- 懒惰求值:在主处理阶段使用生成器,逐步处理数据,避免一次性加载所有数据。
- 优化:选择最优的数据结构和算法,如使用堆进行优先级队列操作。
- 渐进式复杂度分析:分析每个处理阶段的时间和空间复杂度,确保整体复杂度在可接受范围内。
- 模块化:将预处理、主处理和后处理分别设计为独立模块,并定义清晰的接口。
- 迭代与递增:通过小步迭代,不断改进系统,增加新功能和优化性能。
- 启发式方法:基于历史数据和实际情况,灵活调整系统参数和处理策略。
通过这些技巧,可以将上述哲学和编程思想应用到更多实际问题中,开发出高效、灵活且可维护的解决方案。