
链表是一种数据结构,它包含一系列存储在内存中随机位置的节点,从而实现高效的内存管理。链表中的每个节点包含两个主要组成部分:数据部分和对序列中下一个节点的引用。
链表种类:
单项链表
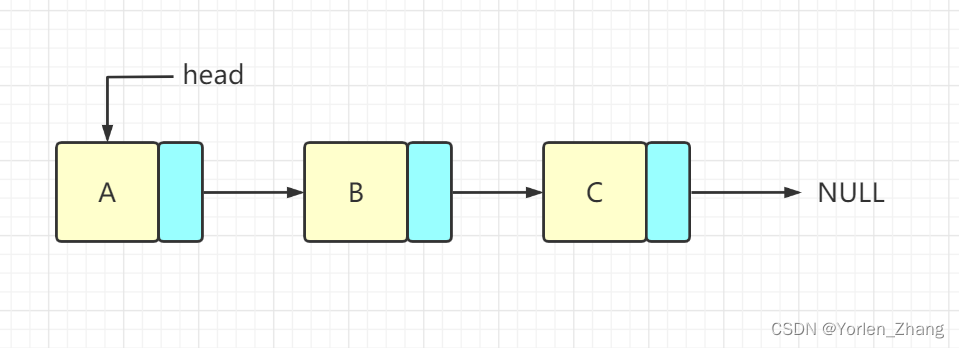
单链表是最简单的链表类型,其中每个节点包含一些数据和对序列中下一个节点的引用。它们只能以单一方向遍历 - 从头(第一个节点)到尾部(最后一个节点)。
单链表中的每个节点通常由两部分组成:
-
数据:节点中存储的实际信息。
-
下一个指针:对下一个节点的引用。最后一个节点的下一个指针通常设置为空。
由于这些数据结构只能单向遍历,因此通过值或索引访问特定元素需要从头部开始,依次遍历节点,直到找到所需的节点。此操作的时间复杂度为 O(n),对于大型列表来说效率较低。
在单链表的开头插入和删除节点效率很高,时间复杂度为 O(1)。然而,在中间或末尾插入和删除需要遍历列表直到该点,导致时间复杂度为 O(n)。
单链表的设计使它们成为执行列表开头发生的操作时有用的数据结构。
定义节点类
python
class Node:
'''
data: 节点保存的数据
_next: 保存下一个节点对象
'''
def __init__(self, data, pnext=None):
self.data = data
self._next = pnext链表中的基本要素
① 结点(也可以叫节点或元素),每一个结点有两个域;
- 左边部份叫值域,用于存放用户数据
- 右边叫指针域,一般是存储着到下一个元素的指针
② head结点:head是一个特殊的结节,head结点永远指向第一个结点
③ tail结点:tail结点也是一个特殊的结点,tail结点永远指向最后一个节点
④ None:链表中最后一个结点指针域的指针指向None值,因也叫接地点,所以有些资料上用电气上的接地符号代表None
代码展示
python
# 定义三个节点
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
# 将这三个节点彼此相连
node1.next = node2
node2.next = node3单向循环链表
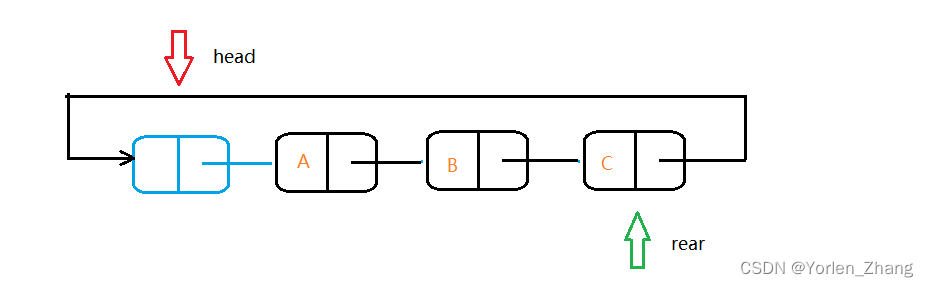
循环链表是链表的一种特殊形式,其中最后一个节点指向第一个节点,从而创建循环结构。这意味着,与我们迄今为止看到的单链表和双向链表不同,循环链表不会结束;相反,它会循环。
循环链表的循环性质使其非常适合需要连续循环的场景,例如从最后一个玩家循环回到第一个玩家的棋盘游戏,或者循环调度等计算算法。
双向链表

单链表的一个缺点是我们只能在一个方向上遍历它们,并且在需要时无法迭代回前一个节点。这种限制限制了我们执行需要双向导航的操作的能力。
双链表通过在每个节点中合并一个额外的指针来解决这个问题,确保可以在两个方向上遍历该列表。双向链表中的每个节点包含三个元素:数据、指向下一个节点的指针和指向前一个节点的指针。
双向循环链表
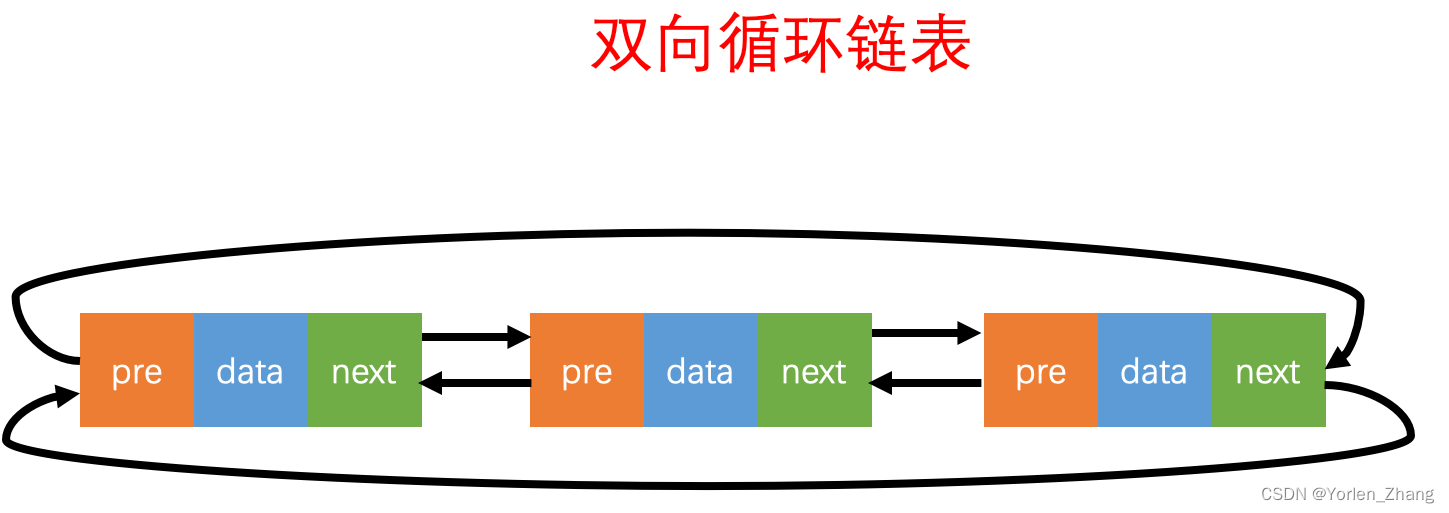
特点:
双向链表每个节点有两个指针,可以向前或向后遍历。
可以从任意节点开始向前或向后遍历整个链表。
插入和删除节点的操作相对容易,只需要调整节点的前驱和后继指针即可。
对于双向链表,可以更轻松地实现双向循环链表,即首尾节点相连。
常见操作:
遍历链表:可以从头节点开始,按照后继指针依次访问每个节点。或者从尾节点开始,按照前驱指针依次访问每个节点。
插入节点:在给定位置之前或之后插入一个新节点,只需要调整前后节点的指针即可。
删除节点:删除给定位置上的节点,同样通过调整前后节点的指针来实现。
查找节点:可以通过遍历链表来查找特定值或者特定位置上的节点。
为什么要使用链表?
使用链表是为了克服与在常规列表和数组中存储数据相关的各种缺点,在列表中,在除末尾以外的任何位置插入或删除元素都需要将所有后续项移动到不同的位置。此过程的时间复杂度为 O(n),并且会显着降低性能,尤其是随着列表大小的增长。
然而,链接列表的操作方式不同。它们将元素存储在各种不连续的内存位置,并通过指向后续节点的指针将它们连接起来。这种结构允许链表在任何位置添加或删除元素,只需修改链接以包含新元素或绕过已删除的元素即可。
一旦确定了元素的位置并且可以直接访问插入或删除点,则可以在 O(1) 时间内实现添加或删除节点。
动态尺寸
Python 列表是动态数组,这意味着它们提供了修改大小的灵活性。但这个过程涉及一系列复杂的操作,包括将数组重新分配到新的、更大的内存块。这种重新分配效率低下,因为元素被复制到新块,可能会分配比立即需要的空间更多的空间。
相反,链表可以动态增长和收缩,而不需要重新分配或调整大小。这使它们成为需要高度灵活性的任务的更好选择。
内存效率
列表为其连续块中的所有元素分配内存。如果列表需要增长超过其初始大小,则必须分配一个新的、更大的连续内存块,然后将所有现有元素复制到这个新块。这个过程既耗时又低效,尤其是对于大型列表。另一方面,如果列表的初始大小被高估,则未使用的内存就会被浪费。
相反,链表为每个元素单独分配内存。这种结构可以提高内存利用率,因为可以在添加新元素时为其分配内存。
什么时候应该使用链接列表?
虽然链表比常规列表和数组具有某些优势,例如动态大小和内存效率,但它们也有其局限性。由于必须存储每个元素的指针以引用下一个节点,因此使用链表时每个元素的内存使用量会更高。此外,该数据结构不允许直接访问数据。访问一个元素需要从列表的开头开始顺序遍历,导致搜索时间复杂度为 O(n)。
使用链表还是数组的选择取决于应用程序的具体需求。链接列表在以下情况下最有用:
-
需要频繁插入和删除很多元素
-
数据大小不可预测或可能频繁变化
-
不需要直接访问元素
-
数据集包含大型元素或结构