🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
**💫个人格言: "如无必要,勿增实体"**

文章目录
- [XGBoost: 强化学习与梯度提升的杰作](#XGBoost: 强化学习与梯度提升的杰作)
-
- 引言
- [1. XGBoost概览](#1. XGBoost概览)
-
- [1.1 什么是XGBoost?](#1.1 什么是XGBoost?)
- [1.2 XGBoost的发展背景](#1.2 XGBoost的发展背景)
- [2. 核心原理与算法机制](#2. 核心原理与算法机制)
-
- [2.1 梯度提升回顾](#2.1 梯度提升回顾)
- [2.2 XGBoost的独特之处](#2.2 XGBoost的独特之处)
- [3. 实践应用指南](#3. 实践应用指南)
-
- [3.1 参数调优](#3.1 参数调优)
- [3.2 特征重要性与模型解释](#3.2 特征重要性与模型解释)
- [3.3 应用案例](#3.3 应用案例)
- [4. 高级话题与挑战](#4. 高级话题与挑战)
-
- [4.1 过拟合与正则化策略](#4.1 过拟合与正则化策略)
- [4.2 大规模数据处理与优化](#4.2 大规模数据处理与优化)
- [4.3 模型融合与集成](#4.3 模型融合与集成)
- 结语
XGBoost: 强化学习与梯度提升的杰作
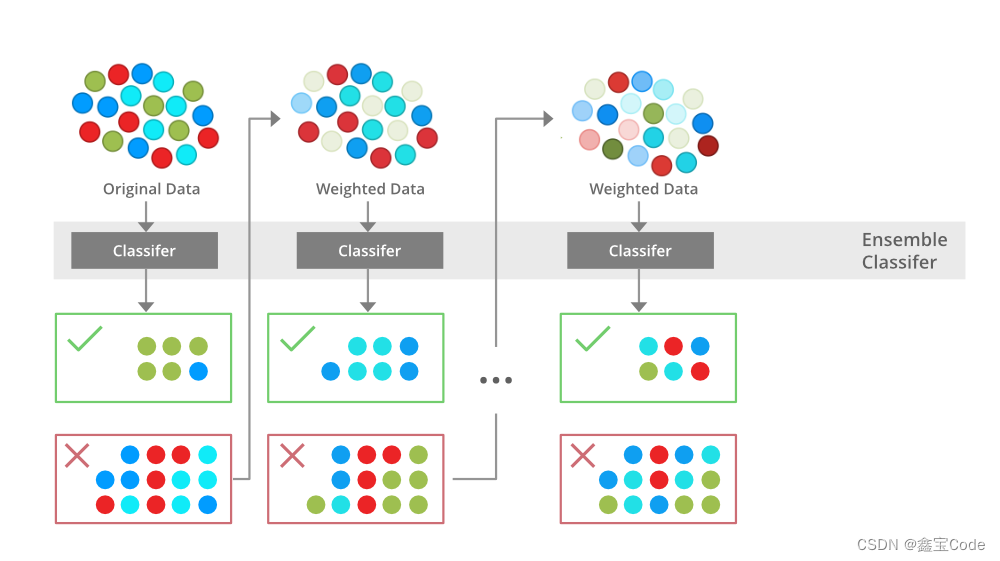
引言
在机器学习的广阔领域中,集成学习方法因其卓越的预测性能和泛化能力而备受瞩目。其中,XGBoost(Extreme Gradient Boosting)作为梯度提升决策树算法的杰出代表,自其诞生以来,便迅速成为数据科学竞赛和工业界应用中的明星算法。本文旨在深入浅出地介绍XGBoost的核心原理、技术优势、实践应用,并探讨其在模型调优与解释性方面的考量,为读者提供一个全面且深入的理解框架。
1. XGBoost概览
1.1 什么是XGBoost?
XGBoost是一种基于梯度提升框架的优化工具,它通过迭代地添加决策树以逐步降低预测误差。相较于传统的梯度提升机(GBM),XGBoost在计算效率、并行处理能力和模型灵活性上进行了显著的优化,从而在分类和回归任务中展现出更强大的性能。
1.2 XGBoost的发展背景
XGBoost的发展源自梯度提升算法的持续演进,特别是Friedman的梯度提升框架。它解决了原有实现中的几个关键问题,如内存消耗、训练速度慢和并行计算能力不足,成为当时最高效的梯度提升实现之一。
2. 核心原理与算法机制
2.1 梯度提升回顾
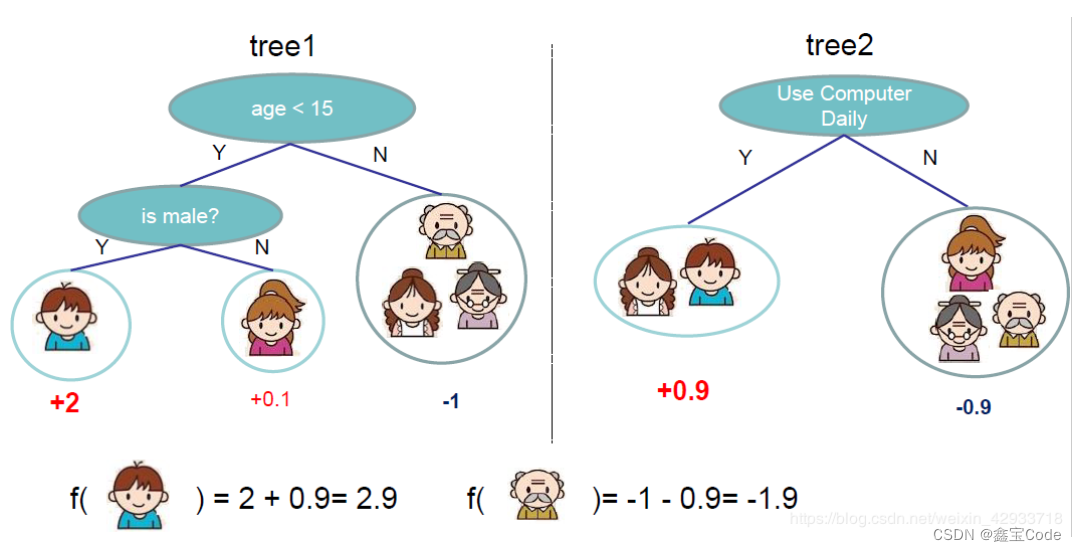
梯度提升的基本思想是通过构建一系列弱预测模型(通常是决策树),并以损失函数的负梯度作为残差进行拟合,逐步叠加这些模型来减少预测误差。每一棵树都是对前一棵树预测结果的修正。
2.2 XGBoost的独特之处
-
目标函数优化:XGBoost不仅关注于降低训练误差,还通过引入正则化项来控制模型复杂度,防止过拟合。其目标函数为:
L ( θ ) = ∑ i = 1 n l ( y i , y ^ i ( t ) ) + Ω ( f ) L(\theta) = \sum_{i=1}^{n}l(y_i, \hat{y}_i^{(t)}) + \Omega(f) L(θ)=i=1∑nl(yi,y^i(t))+Ω(f)
其中, l l l 是损失函数, Ω \Omega Ω 是正则项,用于惩罚模型复杂度。
-
列块最小化:为了提高计算效率,XGBoost采用了列块最小化技术,它在每个迭代过程中只遍历特征的一部分,大大减少了计算量。
-
并行与分布式计算:通过将数据分割成多个块进行并行处理,XGBoost能够高效利用多核CPU和分布式系统资源。
-
缺失值处理与稀疏感知:XGBoost能够自动处理缺失值,并针对稀疏数据结构优化算法,使其在处理高维度稀疏数据时更为高效。
3. 实践应用指南
3.1 参数调优
XGBoost提供了丰富的超参数供用户调整,包括学习率(eta)、最大深度(max_depth)、最小分裂损失(gamma)等。有效的参数调优对于达到最佳性能至关重要。
3.2 特征重要性与模型解释
XGBoost能够输出特征重要性,帮助理解模型背后的决策逻辑。这不仅有助于特征选择,也提升了模型的可解释性。
3.3 应用案例
XGBoost广泛应用于推荐系统、信用评分、疾病预测等多个领域。通过实例分析,我们可以直观感受到其在实际问题解决中的强大威力。
下面是一个使用Python实现的简单XGBoost分类任务示例,包括数据预处理、模型训练、评估和预测的基本步骤。此示例使用了著名的鸢尾花(Iris)数据集,该数据集可以直接从sklearn库获取。代码仅供参考~🐶
python
# 导入所需库
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# 转换为DMatrix格式,XGBoost的原生数据结构,可以提高效率
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 设置XGBoost参数
param = {
'eta': 0.3,
'max_depth': 3,
'objective': 'multi:softmax', # 多分类问题
'num_class': 3, # 类别数
'eval_metric': 'mlogloss' # 多分类的评价指标
}
# 训练模型
bst = xgb.train(param, dtrain, num_boost_round=10)
# 预测
preds = bst.predict(dtest)
pred_labels = preds.argmax(axis=1) # 获取概率最大的类别作为预测类别
# 计算准确率
accuracy = accuracy_score(y_test, pred_labels)
print("Accuracy: %.2f%%" % (accuracy * 100.0))4. 高级话题与挑战
4.1 过拟合与正则化策略
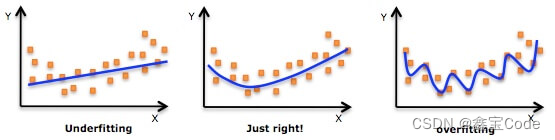
虽然XGBoost通过内置的正则化项有效缓解了过拟合问题,但在面对极端复杂的数据集时,合理设置正则化参数仍然是一项挑战。
4.2 大规模数据处理与优化
随着数据量的增加,如何高效地在大规模数据上应用XGBoost,特别是在有限的计算资源下,成为了研究者和工程师们关注的焦点。
4.3 模型融合与集成
将XGBoost与其他模型(如神经网络)结合,构建更强大的集成模型,是进一步提升预测准确性的探索方向。
结语
XGBoost凭借其高效、灵活和强大的预测能力,在机器学习领域占据了一席之地。随着算法的不断优化和应用场景的拓展,掌握XGBoost的原理与应用,无疑将为数据科学家和工程师们提供更强大的工具箱。未来,XGBoost及其后续发展将继续推动着机器学习技术的进步,为解决复杂现实问题提供更多可能。
本文尝试以简洁明了的方式概述了XGBoost的核心概念、技术特点、实战技巧以及面临的挑战,希望能够为读者提供一个全面且易于理解的参考框架。在实际应用中,不断探索和实验将是深入掌握XGBoost精髓的关键。