
文章目录
- 什么是流
- [何时使用 RabbitMQ Stream?](#何时使用 RabbitMQ Stream?)
- [在 RabbitMQ 中使用流的其他方式](#在 RabbitMQ 中使用流的其他方式)
- 基本使用
- [Stream 插件](#Stream 插件)
- 示例应用程序
- [RabbitMQ 流 Java API](#RabbitMQ 流 Java API)
-
- 概述
- 环境
-
- 创建具有所有默认值的环境
- [使用 URI 创建环境](#使用 URI 创建环境)
- [创建具有多个 URI 的环境](#创建具有多个 URI 的环境)
- [启用 TLS](#启用 TLS)
-
- 什么是TLS
- [创建使用 TLS 的环境](#创建使用 TLS 的环境)
- [创建信任所有服务器证书进行开发的 TLS 环境](#创建信任所有服务器证书进行开发的 TLS 环境)
- 负载均衡
- 管理流
- 服务端的偏移量跟踪
- Kafka简单对比
什么是流
附官方文档:https://www.rabbitmq.com/docs/streams#overview
RabbitMQ Streams 是一种持久复制的数据结构,可以完成与队列相同的任务:它们缓冲来自生产者的消息,供消费者读取。 但是,流在两个重要方面与队列不同:消息的存储和使用方式。
流对消息的仅追加日志进行建模,这些消息可以重复读取,直到它们过期。 流始终是持久和复制的。对这种流行为的更技术性的描述是"非破坏性消费者语义"。
要从 RabbitMQ 中的流中读取消息,一个或多个使用者订阅该流并根据需要多次读取相同的消息。
流中的数据可以通过 RabbitMQ 客户端库或专用二进制协议插件和关联的客户端使用。 强烈建议使用后一种选项,因为它提供对所有特定于流的功能的访问,并提供最佳吞吐量(性能)。
对于流队列的描述是:高性能、可持久化、可复制、非破坏性消费、只追加写入的日志
何时使用 RabbitMQ Stream?
RabbitMQ Stream被开发用于满足以下消息传递使用情况:
- 大规模广播(Large fan-outs):当多个消费者应用程序需要读取相同的消息时。
- 回放/时光旅行(Replay / Time-traveling):当消费者应用程序需要读取整个数据历史记录或从流中的特定点开始时。
- 吞吐量性能(Throughput performance):当需要比其他协议(AMQP、STOMP、MQTT)更高的吞吐量时。
- 大型日志(Large logs):当需要存储大量数据,并且内存开销最小化时。
在 RabbitMQ 中使用流的其他方式
使用AMQP 0-9-1协议,可以在RabbitMQ中使用流抽象。与使用流协议从流中消费不同,使用AMQP 0-9-1协议时,可以从"流驱动"的队列中进行消费。所谓的"流驱动"队列是一种特殊类型的队列,它由流基础架构层支持,并经过调整以提供流语义(主要是非破坏性读取)。
使用这样的队列具有以下优点:可以利用流抽象固有的特性(仅追加结构,非破坏性读取),并与任何AMQP 0-9-1客户端库一起使用。考虑到AMQP 0-9-1客户端库的成熟度以及AMQP 0-9-1周围的生态系统,这显然是很有趣的。
但是,通过使用它,无法获得流协议的性能优势,因为流协议是专为性能而设计的,而AMQP 0-9-1是一种更通用的协议。
使用"流驱动"队列无法与流Java客户端一起使用,您需要使用AMQP 0-9-1客户端库。
基本使用
生产消息:
js
import pika
from pika import BasicProperties
from pika.adapters.blocking_connection import BlockingChannel
from pika.spec import Basic
STREAM_QUEUE = "stream_queue"
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost", 5672, "/"))
channel = connection.channel()
//创建了一个到 RabbitMQ 代理的连接,然后创建了一个通道,并声明了一个持久化的流队列(stream queue),该队列名为 "stream_queue",参数为 {"x-queue-type": "stream"}。
channel.queue_declare(queue=STREAM_QUEUE, durable=True, arguments={"x-queue-type": "stream"})
//在循环中,将数字 500 到 599 发布到 "stream_queue" 队列中。
for i in range(500, 600):
msg = f"{i}".encode()
channel.basic_publish("", STREAM_QUEUE, msg)
channel.close()
connection.close()消费消息:
js
import pika
from pika import BasicProperties
from pika.adapters.blocking_connection import BlockingChannel
from pika.spec import Basic
//channel:通道对象,用于确认消息
//method:Basic.Deliver 对象,包含有关传递消息的元数据。
//properties:BasicProperties 对象,包含消息的属性。
//body:消息的内容,以字节形式表示。
def msg_handler(channel: BlockingChannel, method: Basic.Deliver, properties: BasicProperties, body: bytes):
msg = f"获取消息:{body.decode()}"
print(msg)
channel.basic_ack(method.delivery_tag)
STREAM_QUEUE = "stream_queue"
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost", 5672, "/"))
channel = connection.channel()
channel.queue_declare(queue=STREAM_QUEUE, durable=True, arguments={"x-queue-type": "stream"})
//创建了一个到 RabbitMQ 代理的连接,然后创建了一个通道,并声明了一个持久化的流队列(stream queue),该队列名为 "stream_queue",参数为 {"x-queue-type": "stream"}。
channel.basic_qos(prefetch_count=50)
//设置了消费者的 QoS(Quality of Service),限制了每次从队列中获取的消息数量为 50 条。
channel.basic_consume(STREAM_QUEUE, on_message_callback=msg_handler, arguments={"x-stream-offset": 290})
//订阅了 "stream_queue" 队列,并指定了消息处理函数 msg_handler,同时设置了消费者的流偏移量为 290。
channel.start_consuming()
//开始消费消息
channel.close()
connection.close()
//关闭了通道和连接。Offset参数
附官网地址:https://www.rabbitmq.com/blog/2021/09/13/rabbitmq-streams-offset-tracking
偏移量是描述某种位置或相对位置的数值
绝对偏移量没有任何实际意义,只是一种技术概念。因此,当应用程序首次连接到流时,它不太可能使用偏移量,而更倾向于使用高级概念,如流的开头或结尾,甚至流中的某个时间点。
RabbitMQ Streams 支持除绝对偏移量之外的不同偏移量规范:.first、.last、.next、.next 和 timestamp。
对于流的"结尾",有两种偏移量规范:.next 表示下一个将被写入的偏移量。如果消费者在 .next 处连接到流,而且没有人发布消息,那么消费者将不会接收到任何消息。只有当新消息到来时,消费者才会开始接收消息。
.last 表示"从最后一批消息开始"。,因为出于性能考虑,消息是批量处理的。
下图显示了流中的偏移量规范。
可以通过x-stream-offset来控制读取消息的位置
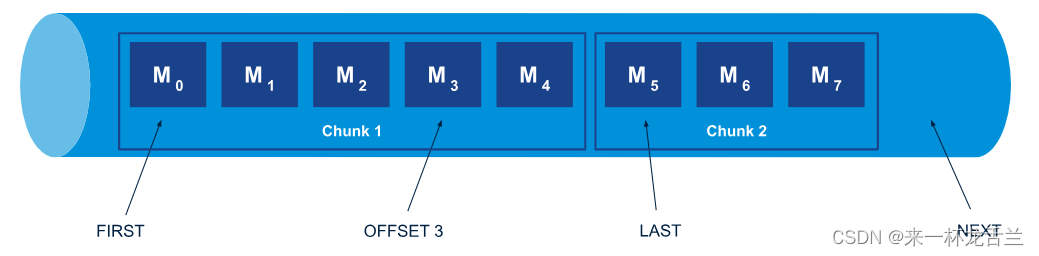
chunk
chunk就是stream队列中用于存储和传输消息的单元,一个chunk包含几条到几千条不等的消息。
Stream 插件
以上只是对Stream类型队列的简单使用,API和普通队列没有差异。若要体验完整的Stream队列特性,如:服务端消息偏移量追踪,需要启用stream插件,不启用和启用流插件功能特性对比
可参考: Stream Core vs Stream Plugin。
服务端消息偏移量追踪
Stream提供了服务端消息偏移量追踪,客户端断开重连后可以从上次消费的下一个位置开始消费消息。
示例
使用docker启动一个rabbitmq服务并启用stream插件:
js
docker run \
-d --name rabbitmq \
--hostname=node1 \
--env=RABBITMQ_NODENAME=r1 \
--env=RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS='-rabbitmq_stream advertised_host localhost' \
--volume=rabbit_erl:/var/lib/rabbitmq \
-p 15672:15672 -p 5672:5672 -p 5552:5552 \
rabbitmq:3-management
docker exec rabbitmq rabbitmq-plugins enable rabbitmq_stream这里使用rstream客户端来收发消息:
js
import asyncio
from rstream import (
Producer
)
STREAM_QUEUE = "stream_queue"
CONSUMER_NAME = "py"
async def pub():
async with Producer("localhost", 5552, username="guest", password="guest") as producer:
await producer.create_stream(STREAM_QUEUE)
for i in range(100, 300):
await producer.send(STREAM_QUEUE, f"{i}".encode())
if __name__ == "__main__":
asyncio.run(pub())消费消息:
js
import asyncio
from rstream import (
AMQPMessage,
Consumer,
ConsumerOffsetSpecification,
MessageContext,
OffsetType, OffsetNotFound
)
STREAM_QUEUE = "stream_queue"
CONSUMER_NAME = "py"
async def msg_handler(msg: AMQPMessage, context: MessageContext):
print(msg)
await context.consumer.store_offset(STREAM_QUEUE, CONSUMER_NAME, context.offset)
async def sub():
consumer = Consumer("localhost", 5552, username="guest", password="guest")
await consumer.start()
try:
offset = await consumer.query_offset(STREAM_QUEUE, CONSUMER_NAME)
except OffsetNotFound:
offset = 1
await consumer.subscribe(STREAM_QUEUE, msg_handler,
offset_specification=ConsumerOffsetSpecification(OffsetType.OFFSET, offset),
subscriber_name=CONSUMER_NAME)
await consumer.run()
if __name__ == "__main__":
asyncio.run(sub())示例应用程序
发布一些消息,然后注册 消费者对它们进行一些计算
创建环境
java
System.out.println("Connecting...");
//用于创建环境Environment#builder
Environment environment = Environment.builder().build();
String stream = UUID.randomUUID().toString();
//创建流
environment.streamCreator().stream(stream).create(); 发布消息
java
System.out.println("Starting publishing...");
int messageCount = 10000;
CountDownLatch publishConfirmLatch = new CountDownLatch(messageCount);
//创建ProducerEnvironment#producerBuilder
Producer producer = environment.producerBuilder()
.stream(stream)
.build();
IntStream.range(0, messageCount)
.forEach(i -> producer.send( //发送消息Producer#send(Message, ConfirmationHandler)
producer.messageBuilder()
.addData(String.valueOf(i).getBytes())
.build(),
confirmationStatus -> publishConfirmLatch.countDown() // 消息发布确认倒计时
));
publishConfirmLatch.await(10, TimeUnit.SECONDS); //等待所有发布确认到达
producer.close(); // 关闭生产者
System.out.printf("Published %,d messages%n", messageCount);消费消息
java
System.out.println("Starting consuming...");
AtomicLong sum = new AtomicLong(0);
CountDownLatch consumeLatch = new CountDownLatch(messageCount);
//创建ConsumerEnvironment#consumerBuilder
Consumer consumer = environment.consumerBuilder()
.stream(stream)
.offset(OffsetSpecification.first()) //从流的开头开始消费
.messageHandler((offset, message) -> { //设置处理消息的逻辑
//将消息正文中的值添加到总和
sum.addAndGet(Long.parseLong(new String(message.getBodyAsBinary())));
//每条消息倒计时
consumeLatch.countDown();
})
.build();
//等待所有消息到达
consumeLatch.await(10, TimeUnit.SECONDS);
System.out.println("Sum: " + sum.get());
//关闭消费者
consumer.close();删除流并关闭环境
java
environment.deleteStream(stream); //删除流
environment.close(); //关闭环境RabbitMQ 流 Java API
概述
RabbitMQ Stream 插件、发布消息和 使用消息。有 3 个主要接口:
- com.rabbitmq.stream.Environment用于连接到节点,并可选择管理流。
- com.rabbitmq.stream.Producer以发布消息。
- com.rabbitmq.stream.Consumer以使用消息。
环境
创建具有所有默认值的环境
java
Environment environment = Environment.builder().build(); //创建将连接到 localhost:5552 的环境
// ...
environment.close(); //使用后关闭环境使用 URI 创建环境
java
Environment environment = Environment.builder()
.uri("rabbitmq-stream://guest:guest@localhost:5552/%2f")
.build();// 使用该方法指定要连接到的 URIuri创建具有多个 URI 的环境
java
Environment environment = Environment.builder()
.uris(Arrays.asList(
"rabbitmq-stream://host1:5552",
"rabbitmq-stream://host2:5552",
"rabbitmq-stream://host3:5552")
)
.build();// 使用该方法指定多个 URIuris启用 TLS
什么是TLS
TLS的主要功能包括:
- 加密(Encryption):TLS使用加密算法对传输的数据进行加密,使其在传输过程中不易被窃听或解读。常见的加密算法包括对称加密算法(如AES)和非对称加密算法(如RSA)。
- 身份验证(Authentication):TLS通过数字证书验证通信双方的身份,确保与对方建立安全连接的是预期的实体,而不是攻击者。
- 完整性保护(IntegrityProtection):TLS使用消息摘要算法(如HMAC)对传输的数据进行签名,以确保数据在传输过程中未被篡改或损坏。
创建使用 TLS 的环境
java
X509Certificate certificate;
try (FileInputStream inputStream =
new FileInputStream("/path/to/ca_certificate.pem")) {
CertificateFactory fact = CertificateFactory.getInstance("X.509");
certificate = (X509Certificate) fact.generateCertificate(inputStream);
//这部分代码加载了一个X.509格式的CA证书文件(/path/to/ca_certificate.pem),这通常是由可信的证书颁发机构(CA)签发的。CA证书用于验证服务器的身份,并建立信任关系。
}
SslContext sslContext = SslContextBuilder
.forClient()
.trustManager(certificate) // 将 Netty 配置为信任 CA 证书SslContext
.build();
//在这里,我们使用加载的CA证书构建了一个SSL上下文(SslContext),该上下文用于客户端的SSL/TLS通信。我们将加载的CA证书作为信任管理器传递给SslContextBuilder,以便客户端能够验证服务器证书的有效性。
Environment environment = Environment.builder()
.uri("rabbitmq-stream+tls://guest:guest@localhost:5551/%2f") //在环境 URI 中使用 TLS 方案
.tls().sslContext(sslContext) // 在环境配置中设置SslContext
.environmentBuilder()
.build();
//在这里,我们创建了RabbitMQ Stream的环境配置。通过URI指定了连接地址和凭据信息。通过.tls().sslContext(sslContext)配置了TLS环境,将之前创建的SSL上下文应用于RabbitMQ Stream连接,确保了安全的通信。创建信任所有服务器证书进行开发的 TLS 环境
java
Environment environment = Environment.builder()
.uri("rabbitmq-stream+tls://guest:guest@localhost:5551/%2f")
.tls().trustEverything() //信任所有服务器证书
.environmentBuilder()
.build();负载均衡
使用自定义地址解析程序始终使用负载均衡器
java
Address entryPoint = new Address("my-load-balancer", 5552); //设置负载均衡器地址
Environment environment = Environment.builder()
.host(entryPoint.host()) //使用负载均衡器地址进行初始连接
.port(entryPoint.port()) //使用负载均衡器地址进行初始连接
.addressResolver(address -> entryPoint) //略元数据提示,始终使用负载均衡器
.build();管理流
创建流
java
environment.streamCreator().stream("my-stream").create();删除流
java
environment.deleteStream("my-stream");创建流时设置保留策略
java
environment.streamCreator()
.stream("my-stream")
.maxLengthBytes(ByteCapacity.GB(10)) //将最大大小设置为 10 GB
.maxSegmentSizeBytes(ByteCapacity.MB(500)) //将段大小设置为 500 MB
.create();创建流时设置基于时间的保留策略
java
environment.streamCreator()
.stream("my-stream")
.maxAge(Duration.ofHours(6)) //将最长期限设置为 6 小时
.maxSegmentSizeBytes(ByteCapacity.MB(500)) //将段大小设置为 500 MB
.create();服务端的偏移量跟踪
RabbitMQ Stream 提供了服务器端的偏移量跟踪功能。这意味着消费者可以跟踪它在流中所达到的偏移量。它允许消费者的新实例在其离开的地方重新开始消费。所有这些操作都不需要额外的数据存储,因为代理服务器存储了偏移量跟踪信息。
偏移量跟踪分为两个步骤:
- 消费者必须具有名称。名称是通过 ConsumerBuilder#name(String)方法设置的。名称可以是任意值(长度不超过256个字符),并且应该是唯一的(从应用程序的角度来看)。需要注意的是,无论是客户端库还是代理服务器都不强制名称的唯一性:如果两个
Java 实例共享相同的名称,它们的偏移量跟踪可能会交错,这通常不符合应用程序的预期。- 消费者必须定期存储其到目前为止已达到的偏移量。偏移量存储的方式取决于跟踪策略:自动或手动
自动跟踪
自动跟踪策略具有以下可用设置:
- 存储前的消息计数:客户端将在指定数量的消息之后存储偏移量,即在消息处理程序执行之后。默认值是每10,000条消息存储一次。
- 刷新间隔:客户端将确保在指定的间隔内存储最后接收到的偏移量。这可以避免在空闲时存在未存储的待处理偏移量。默认值为5秒。
使用默认值的自动跟踪策略
java
Consumer consumer =
environment.consumerBuilder()
.stream("my-stream")
.name("application-1") //设置使用者名称
.autoTrackingStrategy() //使用默认值的自动跟踪策略
.builder()
.messageHandler((context, message) -> {
// message handling code...
})
.build();配置自动跟踪策略
java
Consumer consumer =
environment.consumerBuilder()
.stream("my-stream")
.name("application-1") //设置使用者名称
.autoTrackingStrategy() //使用自动跟踪策略
.messageCountBeforeStorage(50_000) //存储每 50,000 条消息
.flushInterval(Duration.ofSeconds(10)) //确保至少每 10 秒存储一次偏移量
.builder()
.messageHandler((context, message) -> {
// message handling code...
})
.build();手动跟踪
配置手动跟踪策略
java
Consumer consumer =
environment.consumerBuilder()
.stream("my-stream")
.name("application-1") //设置使用者名称
.manualTrackingStrategy() //使用默认值的手动跟踪
.checkInterval(Duration.ofSeconds(10)) //每 10 秒检查一次上次请求的偏移量
.builder()
.messageHandler((context, message) -> {
// message handling code...
if (conditionToStore()) {
context.storeOffset(); //在某种条件下存储电流偏移
}
})
.build();Kafka简单对比
| rabbitmq | kafka | |
|---|---|---|
| 生产/消费者 | queue | topic |
| 底层消息存储 | chunk | partition |