vector是一个类模版,是一个顺序容器,底层思维就是顺序表,而顺序表的本质就是一个可以改变size的数组。本篇基于string的学习基础,我们对vector进行一个大致的了解和学习
1.基本介绍
- vector 是表示可变大小数组的序列容器,几乎所有类型都可以成为vector的元素,因此vector也可以进行嵌套,如:vector<vector<int>>
- 就像数组一样, vector 也采用的连续存储空间来存储元素。也就是意味着可以采用下标对 vector 的元素 进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自 动处理。
- 与其他动态容器的使用区别: 与其它动态序列容器相比( deque, list and forward_list ), vector 在访问元素的时候更加高效,在末 尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起 list 和 forward_list 统一的迭代器和引用更好
- 时间和空间的使用:
vector 使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小 ,为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector 并不会每次都重新分配大小。
vector 分配空间策略: vector 会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存 储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是 对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
2.vector基础操作
2.1构造函数
正如上文所说,vector是类模版,类模版的本质是写给编译器用的,以实现泛型编程。
函数传对象,模版传类型,后者是在编译的时候传的,编译器会根据你传入的类型通过模版自动生成一个相应的vector

vector的数组是所有类型的数组。
对于string和vector<char>的区别,前者是基于"串"而存在的概念,后者是基于"单个字符"而存在的概念。所以vector没有append和+=的概念。
string是专门针对char的数组设计的,vector是针对所有类型的数组设计的。


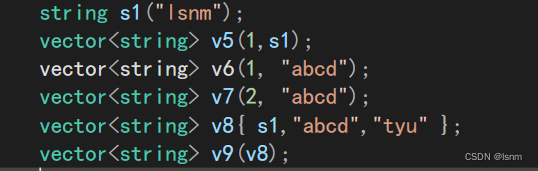
无参构造和拷贝构造是重点。也可以通过中括号里加参数给vector赋值。也就是:
vector<char>{'a','b'};
对于第一个无参构造,第一个参数(value_type)类型对应底层是一个什么类型的数组,第二个参数(allocator_type)有缺省值,allocator是空间配置器,也就是内存池,通过该空间配置器会给vector开空间。
对于第二个赋值构造,我们也可以使用如下:
(最后两排是其他用法)
对于参数的缺省值value_type()和allocator_type(),就像int()一样,表示创建一个匿名对象。在C++中有默认的构造函数的,int()就是0,char()就是\0,而如果是自定义类型就会调用默认构造。


2.2 遍历vector
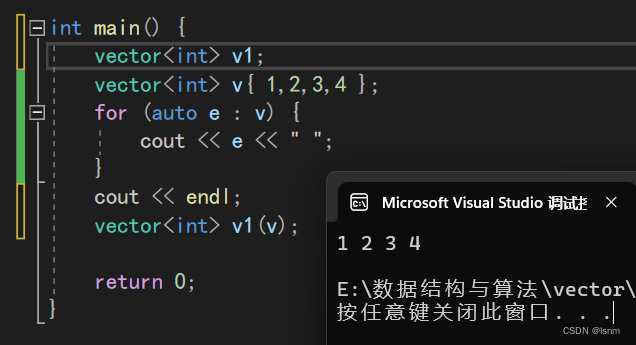
如何遍历?正如上文,vector不仅支持基于迭代器的范围for,还可以下标访问。
vector支持下标访问:

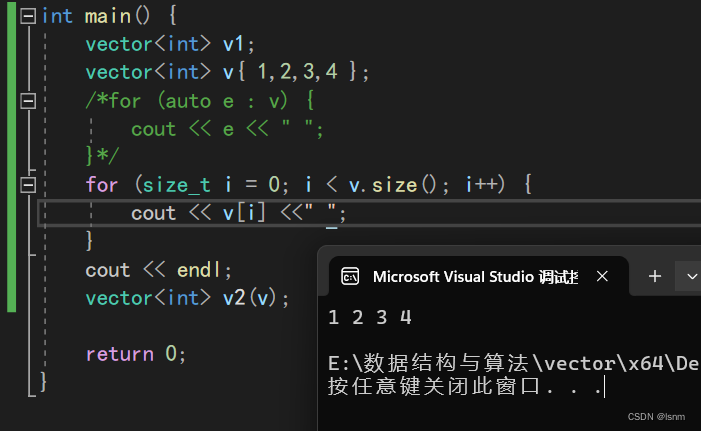
访问方法2:
迭代器:
cpp
vector<int>::iterator it1 = v.begin();
while (it1 != v.end()) {
cout << *it1 << " ";
++it1;
}++虽然vector还是更多喜欢下标访问,但是迭代器可以便于实现范围for和提高接口的通用性。++
2.3 push_back和pop_back的使用
我们以一个string为元素的vector来举例(类似于一个二维char数组)
string类型的vector**就可以用到匿名对象(第二个push_back)**来便于创建: 
也可以直接传常量字符串来构造:

我们简单来看下push_back的参数。因为对于push_back:

push_back的参数必须是const string& s,因为涉及传常量字符串和单参数构造函数隐式类型转换,需要改小push_back处参数的权限。
当string作为vector的元素时,就可以对vector的元素进行+= , 因为strng是可以+=的。 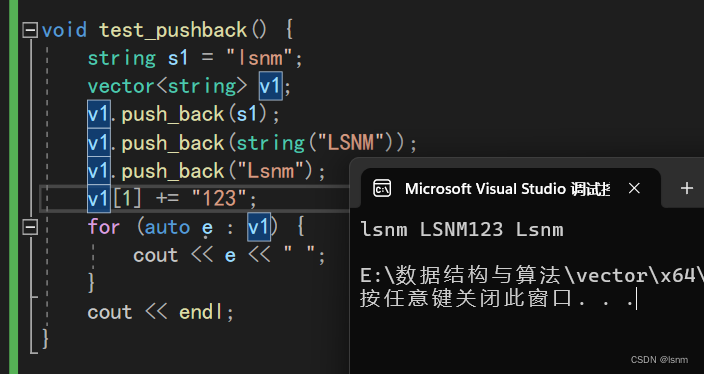
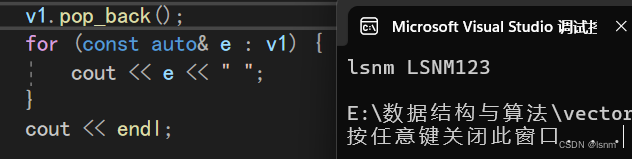
pop_back:
2.4对于需要深拷贝的传值优化
不过此时遍历的范围for写的有缺陷,因为e是传值传参,所以每个string都需要深拷贝。但是如果底层的拷贝用的是写时拷贝,在效率方面就优化了太多。
但是当我们不知道底层是不是写时拷贝时,就可以用以下的传引用方法,来降低拷贝的成本。
cpp
for (const auto& e : v1) {
cout << e << " ";
}2.5 insert和erase等
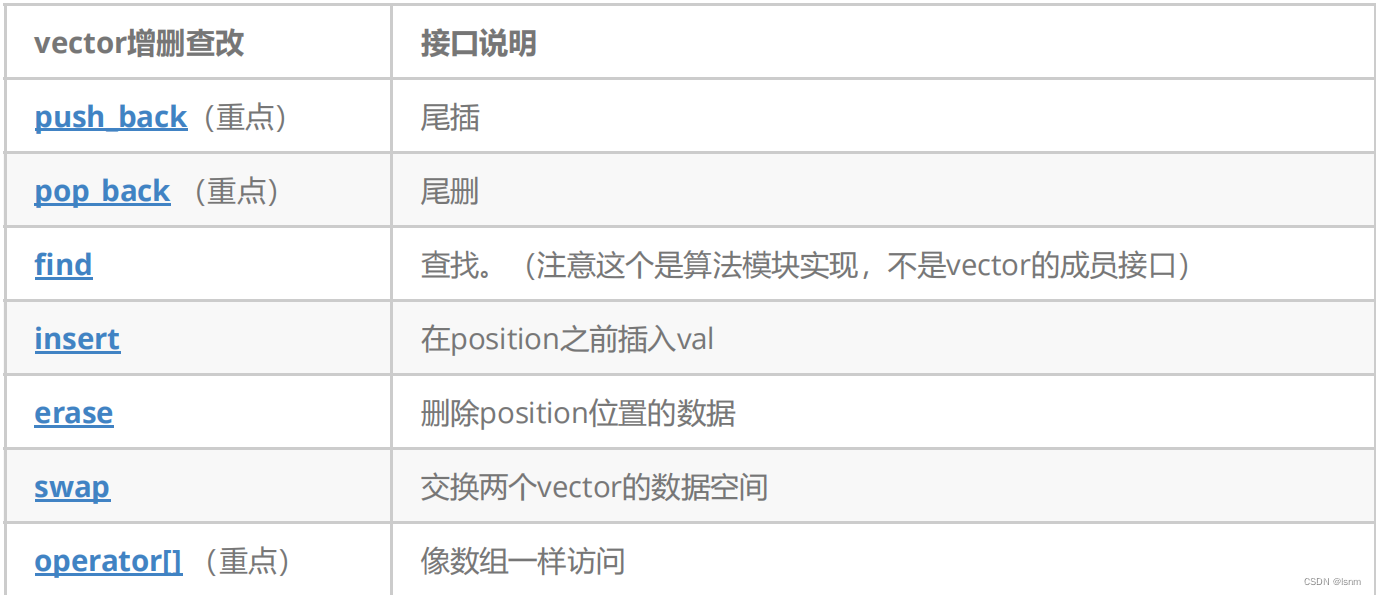
在vector中,insert和erase都没有下标版本,只有迭代器版本:
可发现不能传位置了。
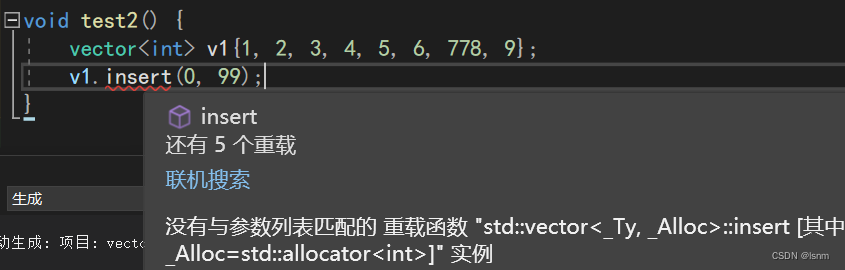 而应该写成 :
而应该写成 :


再来观察一下两种insert的用法:
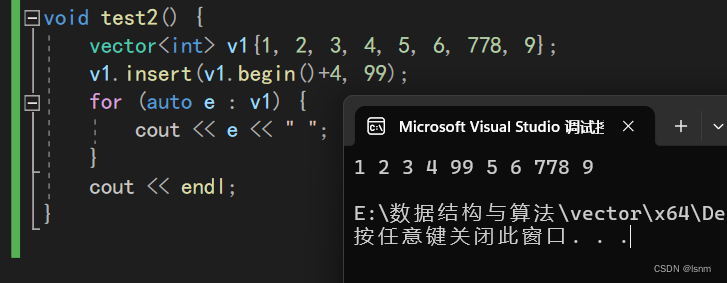
另一种则可以控制多少个数据需要被修改成最后的参数:
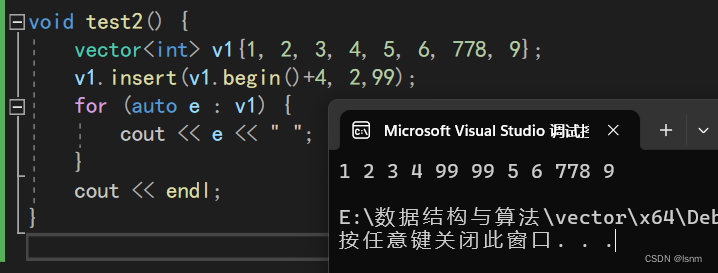
emplace和insert的作用是几乎一样的,但是效率有点小差距。

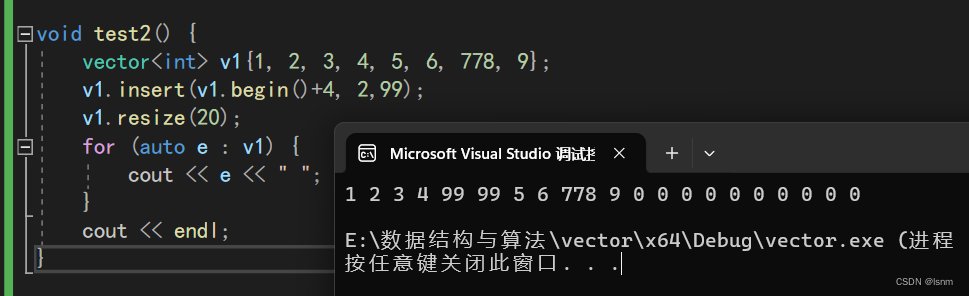
2.6 resize
resize不会改变原有空间的数据,而是在多开出的空间输入你的参数。相当于在数组末尾insert。


vector的resize不像string那样默认加\0,而是加0:
2.7 sort的使用
sort是一个函数模版,参数为迭代器。


可以通过v1.begin()+-n来控制从哪开始,或者利用size来只排序前一半:

默认排序是升序,如果希望降序:
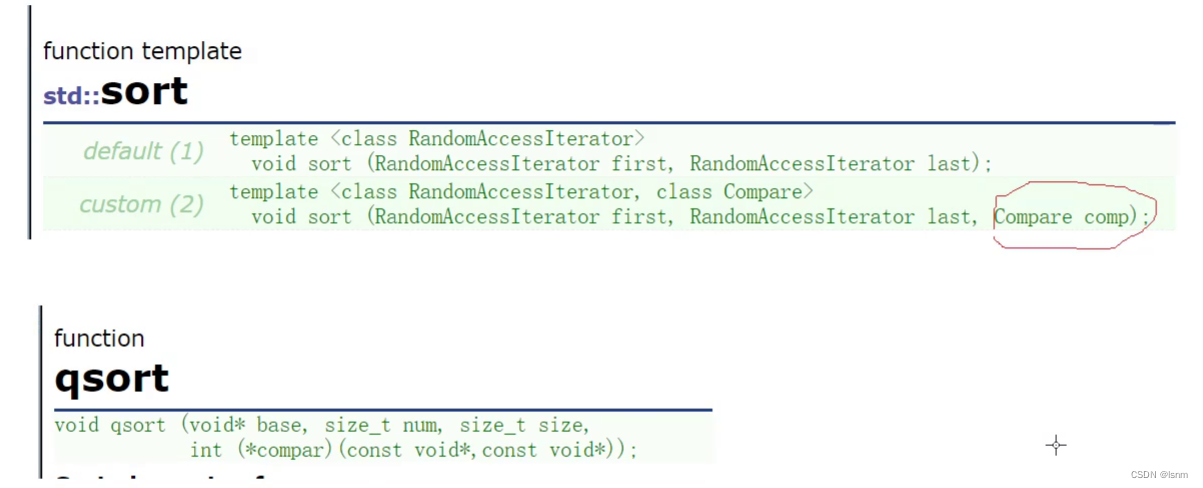
sort的第三个参数表示需要传一个可比较的对象(就像qsort需要传一个函数指针一样)
使用仿函数,仿函数是一个对象

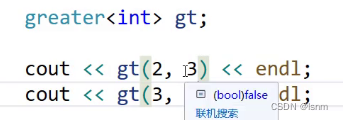
greater是在库中实现的,可以选出更大的,相应的还有less:

可以用greater或less比较两个数,输出为0或1。
或者也可以利用匿名对象:
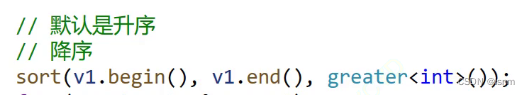
仿函数的具体内容会在后文中讲解,现在知道有这个东西就行了。
3.练习使用vector
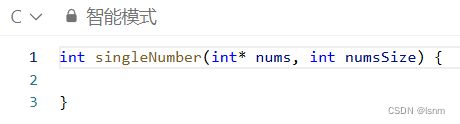
从题目中也可以看出,C++一般都是传vector,而C语言是传int* 和为了能修改而不得不传指针的returnsize:
思路非常简单并且做过无数遍,按位异或即可。

cpp
int singleNumber(vector<int>& nums) {
int ans=0;
for(auto e:nums){
ans^=e;
}
return ans;
}重点理解:resize / operator\[\]以及vector的包含。
类似于一个二维数组
将vector<int>作为参数形成一个新的vector。
所以这里会实例化两个类,一个是vector<int>,另一个是vector<vector<int>>,而在杨辉三角中,每一个vector<int>的大小和元素都是不一样,如下图:
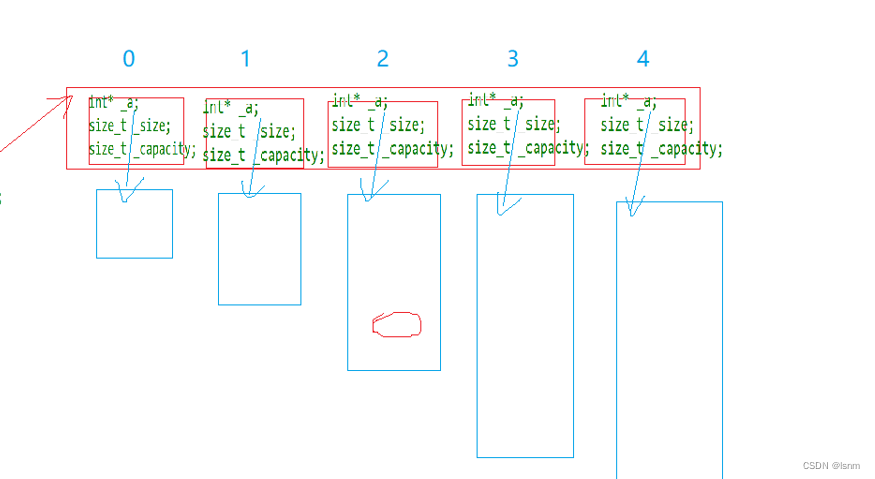
通过vector实现了动态二维数组,该数组可以直接由运算符重载而直接用两个方括号访问:


杨辉三角的解题思路对于现在的大家应该很简单了:

cpp
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> v;
v.resize(numRows);
for(int i =0;i<numRows;++i){
v[i].resize(i+1,0);
v[i][0]=v[i][i]=1;
}
for(int i=0;i<numRows;++i){
for(int j=0;j<=i;++j){
if(v[i][j]==0){
v[i][j]= v[i-1][j]+ v[i-1][j-1];
}
}
}
return v;
}
};Leetcode传一维数组时需要一个returnsize,为了能改变其值所以传进来的是int* returnsize(正如第一题)
传二维数组时还需要一个数组returncolumnsize来记录每一个一维数组有多少个元素,为了能改变这个一维数组的值只能传int** returncolumnsize.