拓展:
sklearn简介:
sklearn(Scikit-learn)是一个广泛使用的Python机器学习库,它是由Pedregosa等人在2011年创建的。这个库是基于NumPy和SciPy库构建的,提供了一系列简单易用的接口,用于数据预处理、模型选择、特征提取、模型训练和评估等机器学习任务。它包含了各种监督学习(如线性回归、决策树、支持向量机、随机森林等)、无监督学习(聚类、降维)、半监督学习、集成学习以及模型选择和交叉验证工具。sklearn的特点包括:
- 模块化设计:将机器学习算法分为多个独立的模块,使得代码结构清晰,易于理解和使用。
- 易用性:提供了直观的API,对新手友好,同时也支持高级用法。
- 丰富的算法:涵盖了众多常用的机器学习算法。
- 可扩展性:允许用户自定义特征工程和模型参数。
- 集成:与其他Python库(如NumPy, Pandas, Matplotlib等)无缝集成。
使用
sklearn进行机器学习的基本流程通常包括数据加载、预处理(如标准化、编码等)、划分训练集和测试集、选择合适的模型、训练模型、评估性能和调整超参数等步骤。
sklearn.datasets简介:
sklearn.datasets是scikit-learn库中的一个重要模块,它包含了各种预定义的数据集,用于机器学习和数据科学的入门和实验。这些数据集覆盖了多个领域,如分类、回归、聚类和无监督学习任务,包括经典的鸢尾花(Iris)、波士顿房价、糖尿病数据集等,以及一些更复杂的文本、图像和时间序列数据。在
sklearn.datasets中,你可以找到以下类型的函数和数据集:
- 加载功能 :如
load_iris()、load_boston()等,用于加载预定义的数值型数据集。- 加载分类数据 :如
load_digits(),用于手写数字分类任务。- 加载回归数据 :如
load_diabetes(),包含糖尿病患者的相关特征和血糖水平。- 加载文本数据 :如
fetch_20newsgroups(),用于文本分类的新闻组数据。- 加载图像数据 :如
load_digits()中的图像数据,或fetch_openml()可以获取OpenML平台上的图片数据。- 加载模拟数据 :如
make_classification()、make_regression()等,用于生成定制的数据集以进行特定模型的训练。通过这些数据集,开发人员可以直接使用进行模型训练、评估和调试,无需从头开始创建数据。同时,它们也常常被用作示例,帮助理解不同算法在实际问题上的应用。
对sklearn.datasets中的鸢尾花(Iris)数据集,按训练集:测试集=7:3构建决策树模型并对模型进行评估。
python
#导入模块
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
#from sklearn.tree import export_graphviz
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #指定默认字体
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#加载数据
iris = load_iris()
irisdf = pd.DataFrame(iris.data,columns=iris.feature_names)
irisdf.head(5)
#划分数据集
from sklearn import model_selection
x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data,
iris.target,
test_size=0.3,
random_state=1)
#训练模型
dct = DecisionTreeClassifier()
fm = dct.fit(x_train,y_train)
pred = dct.predict(x_test)
#输出精确度、召回率和F1分数等信息
print(classification_report(y_test,pred,target_names=iris.target_names))
#可视化决策树
from sklearn import tree
tree.plot_tree(fm,filled=True,
feature_names=iris.feature_names,
class_names=iris.target_names)
'''
filled=True:填充颜色;
feature_names:特征变量名称
class_names:类别名称
'''
#报告模型结果 函数
def reprt_model(model,feature_name,class_name):
'''
model:模型;feature_name:特征变量名称;class_name:类别名称
'''
model_preds = model.predict(x_test)
print(classification_report(y_test,model_preds,
target_names=iris.target_names))
print('\n')
plt.figure(figsize=(12,8),dpi=150)
tree.plot_tree(model,filled=True,
feature_names=feature_name,
class_names=class_name)
#输出 报告模型结果
reprt_model(dct,iris.feature_names,iris.target_names)
#列联表
cross_table = pd.crosstab(y_test, pred)
print(cross_table)输出结果:

列联表:从列联表可以看出,在测试集的45个样本中错误分类的只有2个。1个将1类误分类到2类中,一个将2类误分类到1类中。
模型评估:
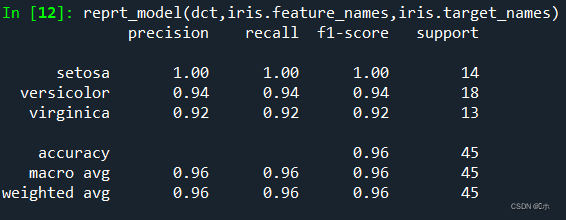
指标说明:
1、precision:精确度;recall:召回率;f1-score:f1分数;support:支持度。
2、accuracy:准确度;macro avg:宏平均;weighted avg:加权平均。
3、setosa、versicolor、Virginica为鸢尾花卉的三种属性,在数据集中分别用0、1、2代替。