python
# 这个简易项目实现了一个基于 LLM 的问答助手,主要功能包括:
#
# 加载预训练的问答模型(默认使用 BERT 模型)
# 读取文本文件作为问答的上下文
# 提供交互式界面,允许用户基于加载的文本进行提问
# 输出模型生成的答案及其置信度
import os
from transformers import pipeline, AutoTokenizer, AutoModelForQuestionAnswering
import torch
class LLMQAAssistant:
def __init__(self, model_name="bert-large-uncased-whole-word-masking-finetuned-squad"):
"""初始化问答助手,加载预训练模型和分词器"""
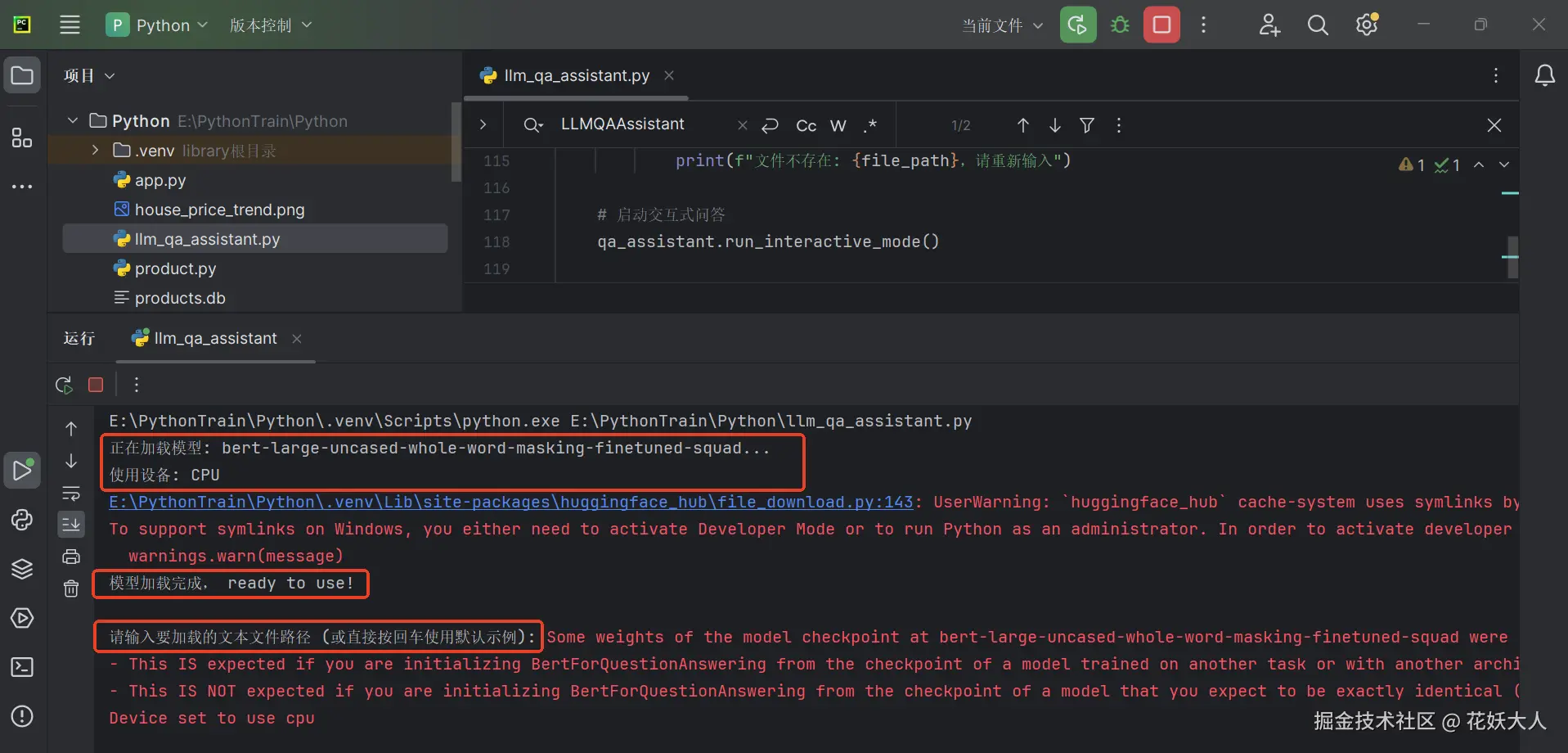
print(f"正在加载模型: {model_name}...")
# 检查是否有可用的GPU
self.device = 0 if torch.cuda.is_available() else -1
print(f"使用设备: {'GPU' if self.device == 0 else 'CPU'}")
# 加载分词器和模型
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForQuestionAnswering.from_pretrained(model_name)
# 创建问答管道
self.qa_pipeline = pipeline(
"question-answering",
model=self.model,
tokenizer=self.tokenizer,
device=self.device
)
self.context = ""
print("模型加载完成, ready to use!")
def load_text_file(self, file_path):
"""加载文本文件作为问答上下文"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
self.context = file.read()
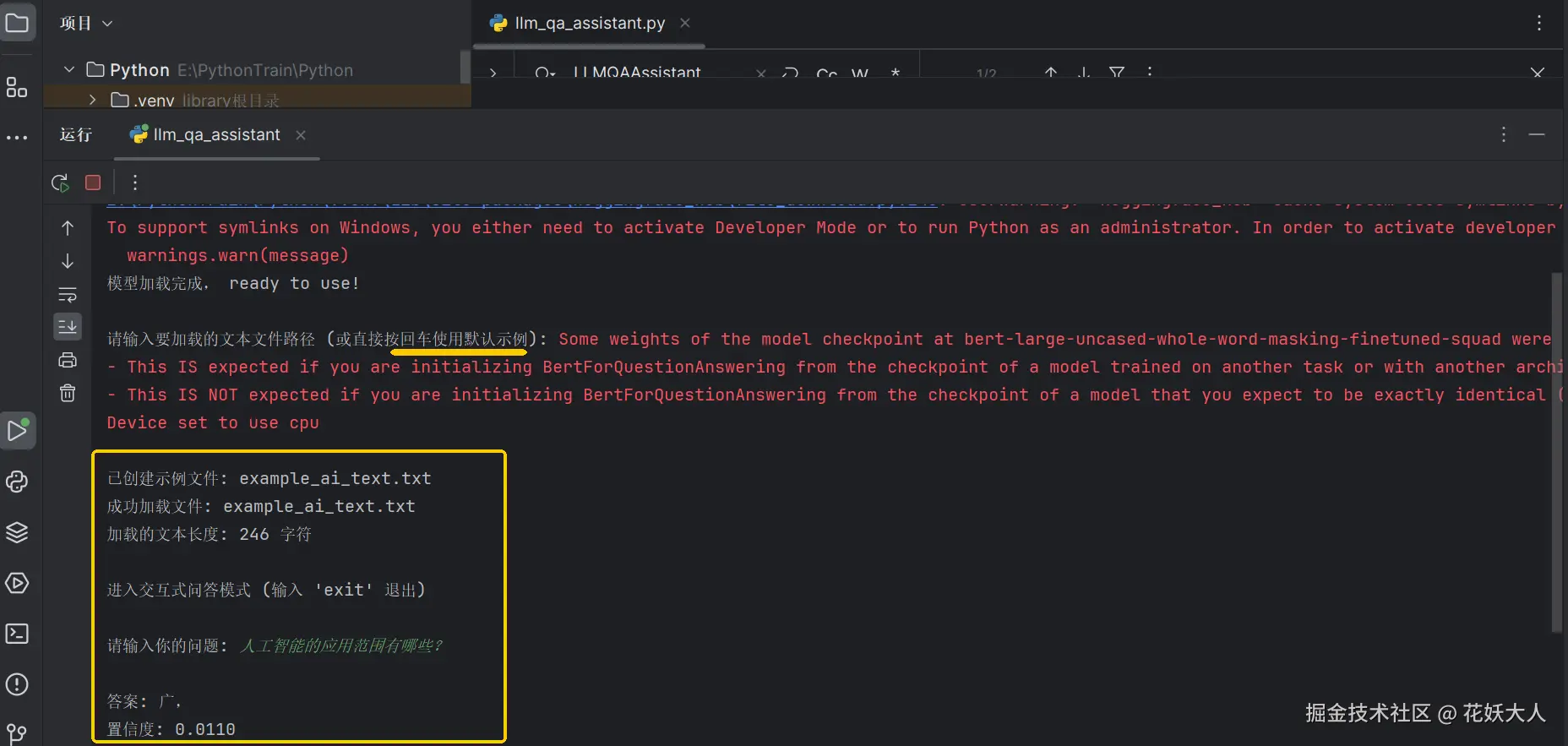
print(f"成功加载文件: {file_path}")
print(f"加载的文本长度: {len(self.context)} 字符")
return True
except Exception as e:
print(f"加载文件失败: {str(e)}")
return False
def ask_question(self, question):
"""基于加载的上下文回答问题"""
if not self.context:
print("请先加载文本文件作为上下文!")
return None
try:
# 限制上下文长度,避免模型处理过长文本
max_context_length = 384 # BERT模型的典型最大长度
if len(self.context) > max_context_length:
# 这里简化处理,只取前max_context_length个字符
# 更复杂的实现可以做文本分割和段落匹配
processed_context = self.context[:max_context_length]
print(f"注意: 上下文过长,已截断至 {max_context_length} 字符")
else:
processed_context = self.context
# 进行问答
result = self.qa_pipeline(question=question, context=processed_context)
return result
except Exception as e:
print(f"回答问题时出错: {str(e)}")
return None
def run_interactive_mode(self):
"""交互式问答模式"""
print("\n进入交互式问答模式 (输入 'exit' 退出)")
while True:
question = input("\n请输入你的问题: ")
if question.lower() == 'exit':
print("再见!")
break
result = self.ask_question(question)
if result:
print(f"\n答案: {result['answer']}")
print(f"置信度: {result['score']:.4f}")
if __name__ == "__main__":
# 创建问答助手实例
qa_assistant = LLMQAAssistant()
# 提示用户输入文本文件路径
while True:
file_path = input("\n请输入要加载的文本文件路径 (或直接按回车使用默认示例): ")
if not file_path:
# 创建一个简单的示例文本文件
example_text = """
人工智能(AI)是计算机科学的一个分支,它致力于创造能够模拟人类智能的系统。
这些系统可以执行通常需要人类智能才能完成的任务,如理解语言、识别模式、解决问题和学习。
机器学习是人工智能的一个重要子领域,它使系统能够从数据中学习并改进,而无需显式编程。
深度学习是机器学习的一个子集,它使用多层神经网络来处理复杂的数据。
人工智能的应用范围很广,包括自然语言处理、计算机视觉、语音识别、推荐系统等。
"""
with open("example_ai_text.txt", 'w', encoding='utf-8') as f:
f.write(example_text.strip())
file_path = "example_ai_text.txt"
print(f"已创建示例文件: {file_path}")
if os.path.exists(file_path):
if qa_assistant.load_text_file(file_path):
break
else:
print(f"文件不存在: {file_path},请重新输入")
# 启动交互式问答
qa_assistant.run_interactive_mode()问题:
- 为啥这个项目运行不起来, File "E:\PythonTrain\Python.venv\Lib\site-packages\urllib3\connection.py", line 198, in _new_conn sock = connection.create_connection。 地址在国外:访问打开浏览器访问
https://huggingface.co,能打开说明网络基本正常
2.Xet Storage 的提示,安装hf_xet pip install hf_xet