1 绪论
- 本节无考点,仅供了解。

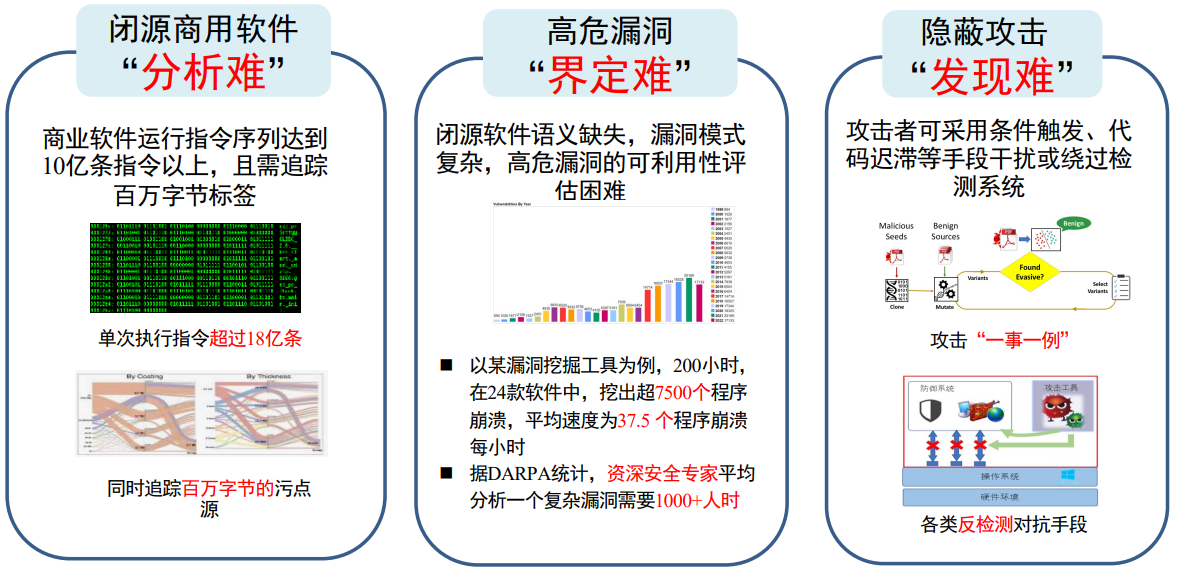





2 基础知识
考点: 汇编码理解和撰写,三种内存地址,不同的页管理方式。windows保护模式可能出题
- 汇编算法的阅读理解
- 给出汇编片段,理解其意思,输入->输出
- 保护模式的内存寻址,现代OS的分页机制
- x86机器码转换到汇编代码
- windows内存管理分页模式推导,系统调用
- ELF动态代码链接延迟绑定(逆向中综合),linux下的系统调用
2.1 处理器硬件架构基础
CPU按照字长可分为16位、32位和64位。
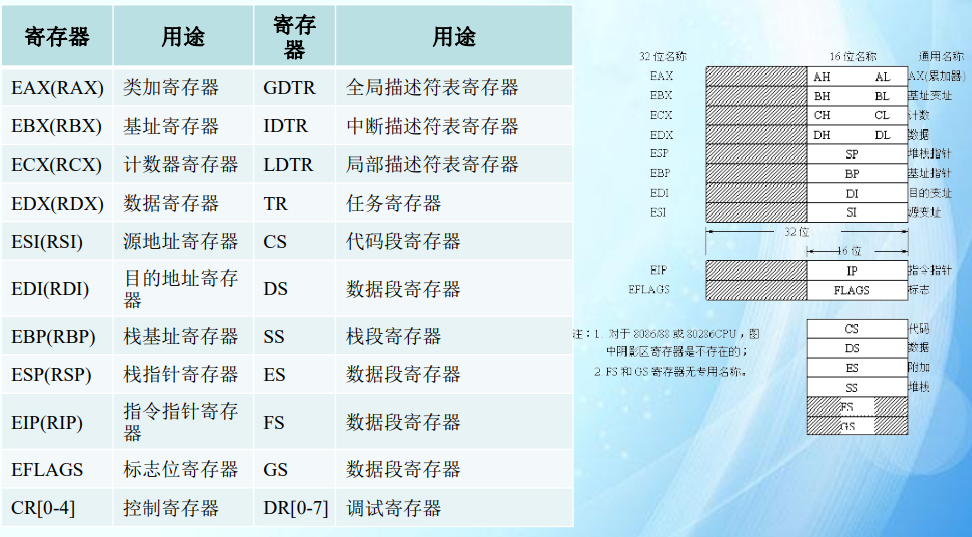


- 汇编指令细节这里不展开了。下面是考试要求:

这里给个示例代码:
asm
section .data
array dd 1, 2, 3, 4, 5 ; 定义一个数组,包含5个元素
array_len equ 5 ; 定义数组长度
section .text
global _start
_start:
xor eax, eax ; 将 eax 清零,用于存储累加和
xor ecx, ecx ; 将 ecx 清零,用于索引数组元素
sum_loop:
cmp ecx, array_len ; 比较索引是否达到数组长度
jge end_loop ; 如果索引 >= 数组长度,跳转到 end_loop
add eax, [array + ecx*4] ; 将当前数组元素的值加到 eax
inc ecx ; 索引加1
jmp sum_loop ; 跳回到 sum_loop 开始
end_loop:
; 这里可以添加其他代码,eax 中已经包含数组元素的累加和
; 退出程序
mov eax, 1
int 0x80保护模式

- 实模式没有内存保护机制,任何程序都可以访问系统内的任意内存地址。这导致一个程序可能会覆盖另一个程序的内存,从而导致系统崩溃。
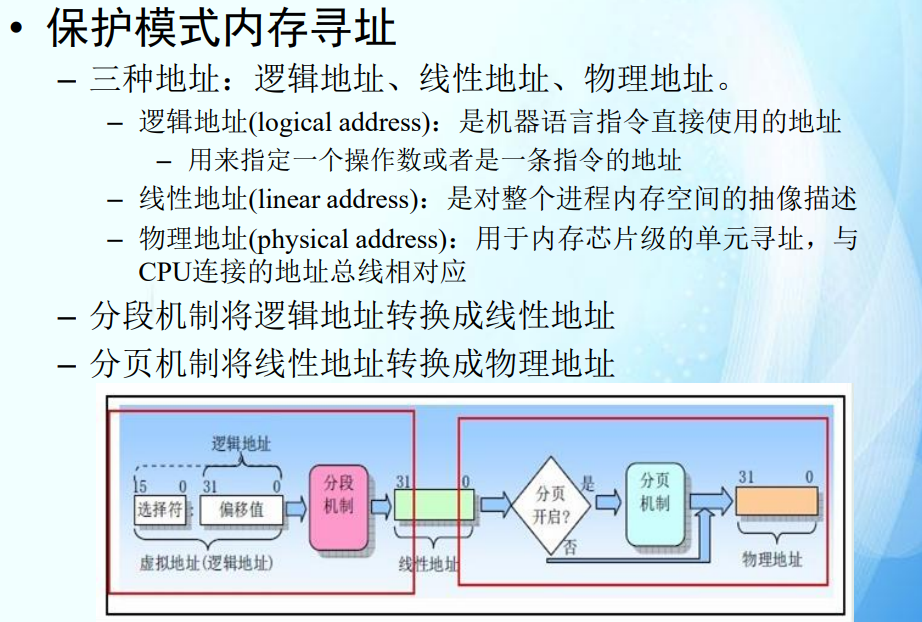 保护模式内存寻址
保护模式内存寻址
逻辑地址转线性地址

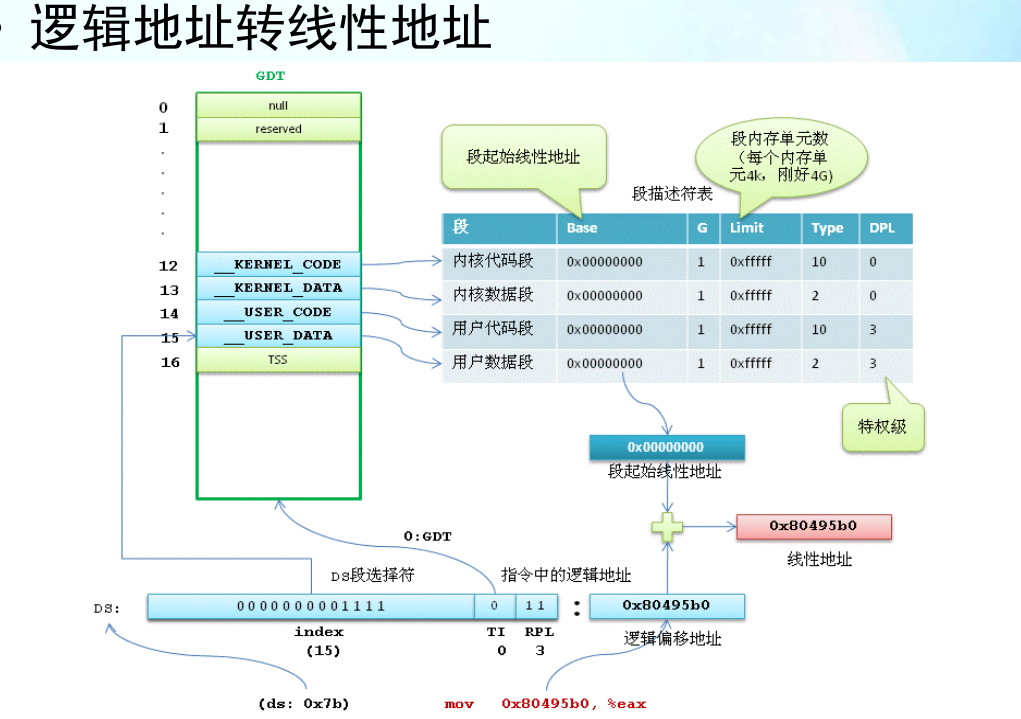
线性地址转物理地址
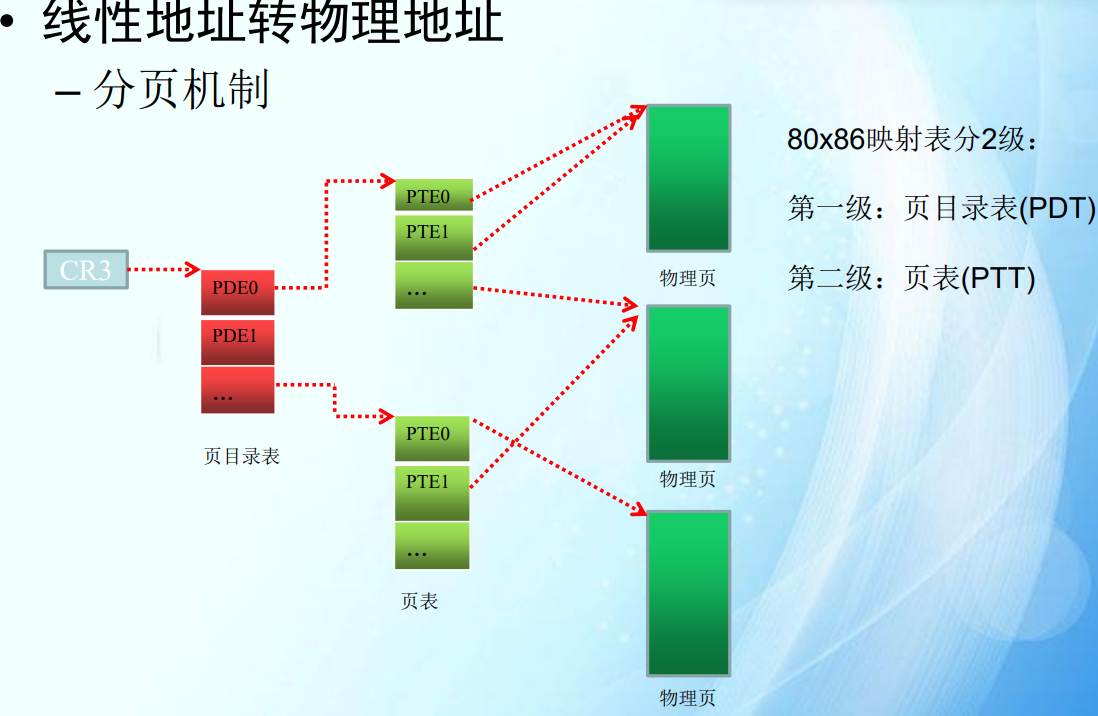
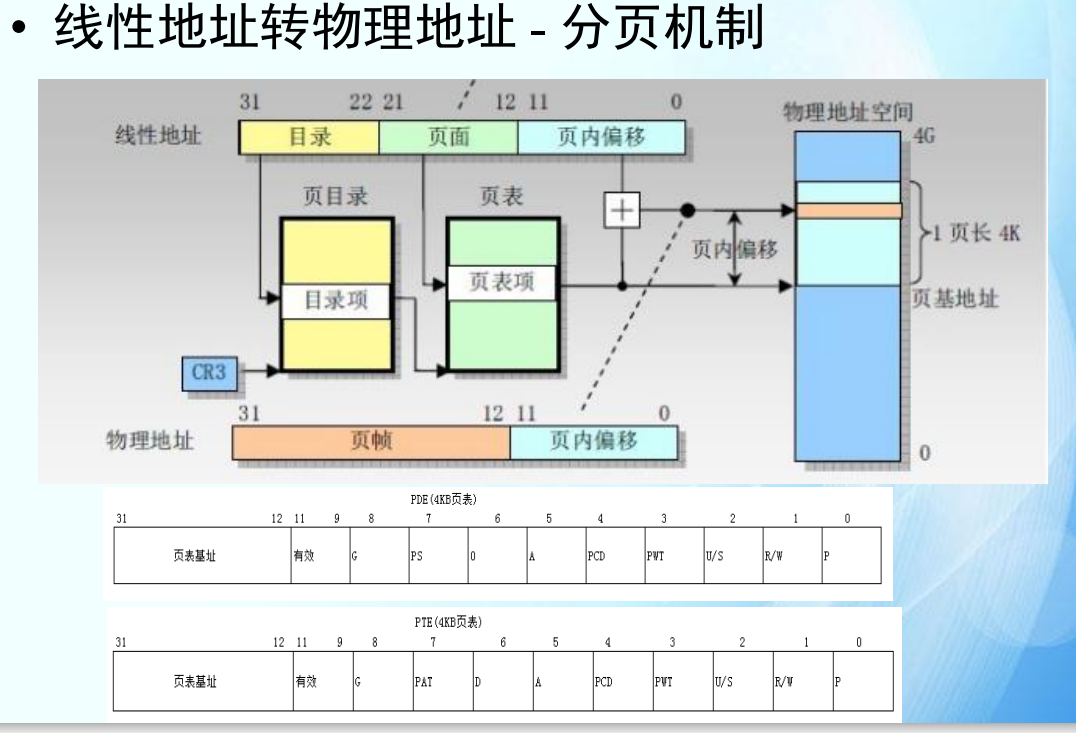

1.给定一个逻辑(虚拟)地址,尝试找到它的物理地址
在现代操作系统中,虚拟地址通过分页机制映射到物理地址。这个过程涉及页目录和页表。以下是一个示例过程:
虚拟地址结构(假设 32 位系统):
虚拟地址:0x12345678
页目录索引:虚拟地址的高 10 位(0x12345678 >> 22)
页表索引:虚拟地址的中间 10 位((0x12345678 >> 12) & 0x3FF)
页内偏移:虚拟地址的低 12 位(0x12345678 & 0xFFF)
查找过程:
使用页目录索引查找页目录,找到页表地址。
使用页表索引查找页表,找到物理页框地址。
物理地址 = 物理页框地址 + 页内偏移。
2.使用程序指令无法访问物理地址,那么操作系统是如何修改页目录表和页表
操作系统运行在高特权级别(内核模式),可以直接访问和修改页目录和页表。以下是一个示例过程:
特权级

2.2 反汇编与反编译基础
略。
2.3 Windows 操作系统基础




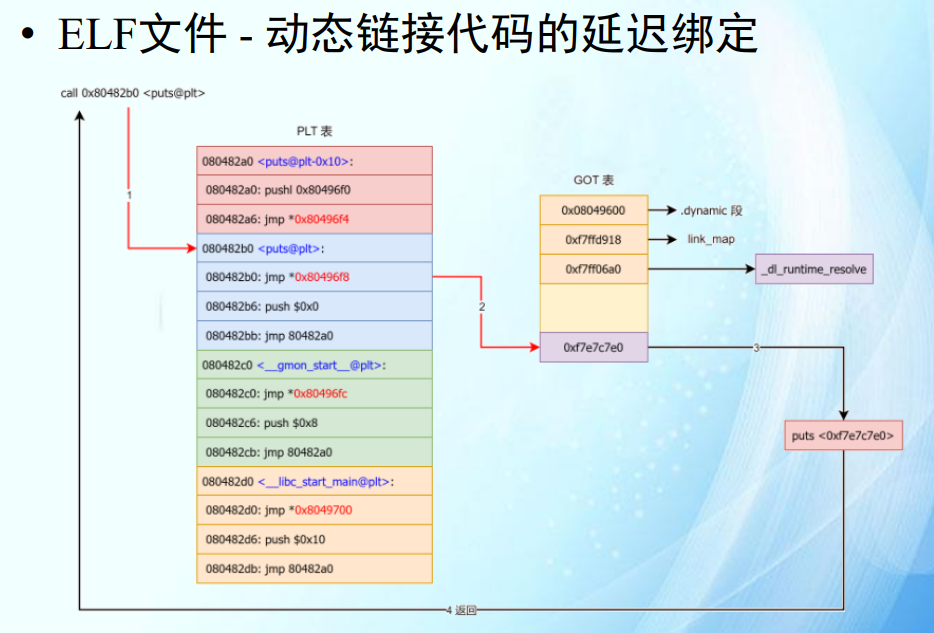
2.4 Linux 操作系统基础
略。
3 基础分析工具介绍
略。查ppt。
4 程序切片 (重点)
考点 :程序切片 :集中出题。
1、控制流、数据流(可达性(参考ppt中的案例)、活跃变量)和程序依赖图(包括数据依赖和控制依赖)
2、现有的切片方法的应用:基于图可达性的静态切片计算
3、不考察数据流方程
4、最好提前看一下动态切片(方法二)的例子
- 程序切片
- 数据流和控制流(和污点分析结合),控制流图(如何画)和程序依赖图的区别
- 可到达定义(算法,示例)、活性分析(理解概念)
- 静态切片
- 数据流方程(不考察,了解即可)
- 图可达算法
- 动态切片(往年静态切片为主,说不定会有动态)
- 基于程序依赖的切片(几种优化方法,和可到达定义的结合)
- 方法三后不用看




控制流分析



数据流分析
可到达定义分析(考察计算题)



- 修正:上图中的语句2 的可到达语句不包括4。


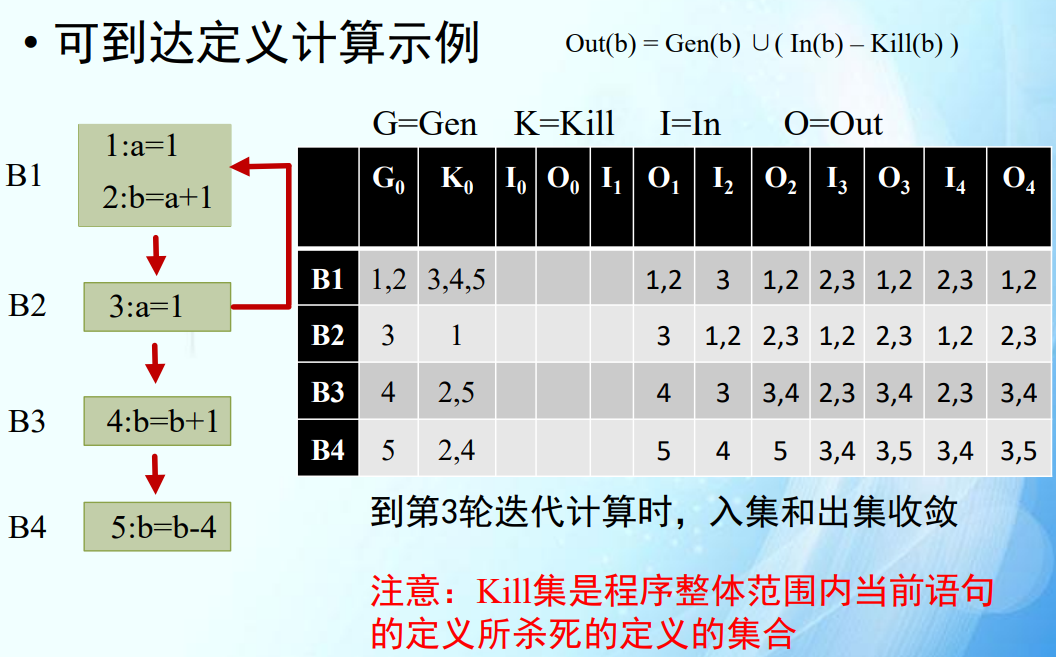

定义集合
我们先确定每个语句的 Gen 和 Kill 集合:
Gen(0) = {0}
Kill(0) = {}
Gen(1) = {1}
Kill(1) = {}
Gen(2) = {2}
Kill(2) = {}
Gen(4) = {4}
Kill(4) = {1}
Gen(5) = {5}
Kill(5) = {0}
Gen(7) = {7}
Kill(7) = {1, 4}
Gen(8) = {8}
Kill(8) = {0, 5}
Gen(9) = {9}
Kill(9) = {2}
路径分析
接下来我们分析从入口到 9 的所有路径:
0\] -\> \[1\] -\> \[2\] -\> \[3\] -\> \[4\] -\> \[5\] -\> \[9
0\] -\> \[1\] -\> \[2\] -\> \[3\] -\> \[6\] -\> \[7\] -\> \[8\] -\> \[9
在每个路径上,我们计算每个语句的 In 和 Out 集合。
路径1: 0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 9
In(0) = {}
Out(0) = Gen(0) = {0}
In(1) = Out(0) = {0}
Out(1) = Gen(1) ∪ (In(1) - Kill(1)) = {1} ∪ {0} = {0, 1}
In(2) = Out(1) = {0, 1}
Out(2) = Gen(2) ∪ (In(2) - Kill(2)) = {2} ∪ {0, 1} = {0, 1, 2}
In(3) = Out(2) = {0, 1, 2}
Out(3) = In(3) = {0, 1, 2}
In(4) = Out(3) = {0, 1, 2}
Out(4) = Gen(4) ∪ (In(4) - Kill(4)) = {4} ∪ {0, 2} = {0, 2, 4}
In(5) = Out(4) = {0, 2, 4}
Out(5) = Gen(5) ∪ (In(5) - Kill(5)) = {5} ∪ {2, 4} = {2, 4, 5}
In(9) = Out(5) = {2, 4, 5}
路径2: 0 -> 1 -> 2 -> 3 -> 6 -> 7 -> 8 -> 9
In(0) = {}
Out(0) = Gen(0) = {0}
In(1) = Out(0) = {0}
Out(1) = Gen(1) ∪ (In(1) - Kill(1)) = {1} ∪ {0} = {0, 1}
In(2) = Out(1) = {0, 1}
Out(2) = Gen(2) ∪ (In(2) - Kill(2)) = {2} ∪ {0, 1} = {0, 1, 2}
In(3) = Out(2) = {0, 1, 2}
Out(3) = In(3) = {0, 1, 2}
In(6) = Out(3) = {0, 1, 2}
Out(6) = In(6) = {0, 1, 2}
In(7) = Out(6) = {0, 1, 2}
Out(7) = Gen(7) ∪ (In(7) - Kill(7)) = {7} ∪ {0, 2} = {0, 2, 7}
In(8) = Out(7) = {0, 2, 7}
Out(8) = Gen(8) ∪ (In(8) - Kill(8)) = {8} ∪ {7} = {7, 8}
In(9) = Out(8) = {7, 8}
对于路径1和路径2,我们得出In(9) = {2, 4, 5} ∪ {7, 8} = {2, 4, 5, 7, 8}
综合所有路径 Out(9) = Gen(9) ∪ (In(9) - Kill(9)) = {4, 5, 7, 8, 9}
9 处的可到达定义是 {4, 5, 7, 8, 9}。

Soundness(正确性):在数据流分析中,一个分析方法是"sound"的,意味着它不会遗漏任何可能影响程序行为的重要信息。在可到达定义分析中,soundness 意味着所有实际可能到达某点的定义都应该被包含在结果中。
False Positives(误报):在可到达定义分析中,误报指的是分析认为某个定义可达,但实际上在程序执行时不可能达到。一般来说,为了保持正确性,分析方法通常会倾向于保守,即宁愿包含更多的定义(可能的误报),也不遗漏任何实际可达的定义。
该方法是 sound 的,不会遗漏任何可能的定义。由于保守的性质,可能会存在误报,但这是为了确保正确性而做出的权衡。
活性分析(理解概念,不考计算)


程序依赖图
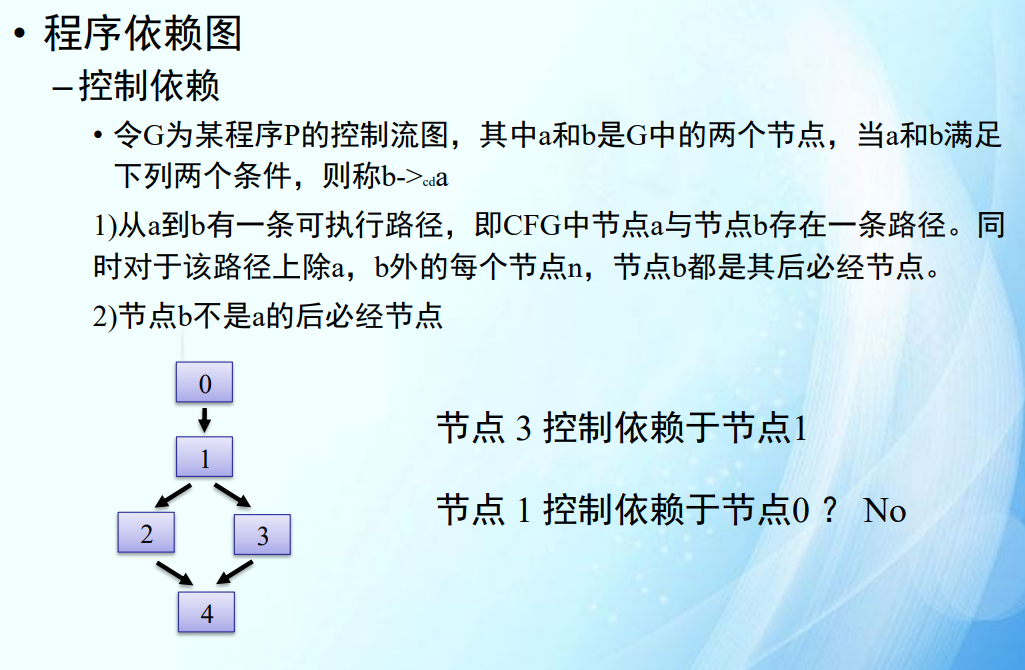

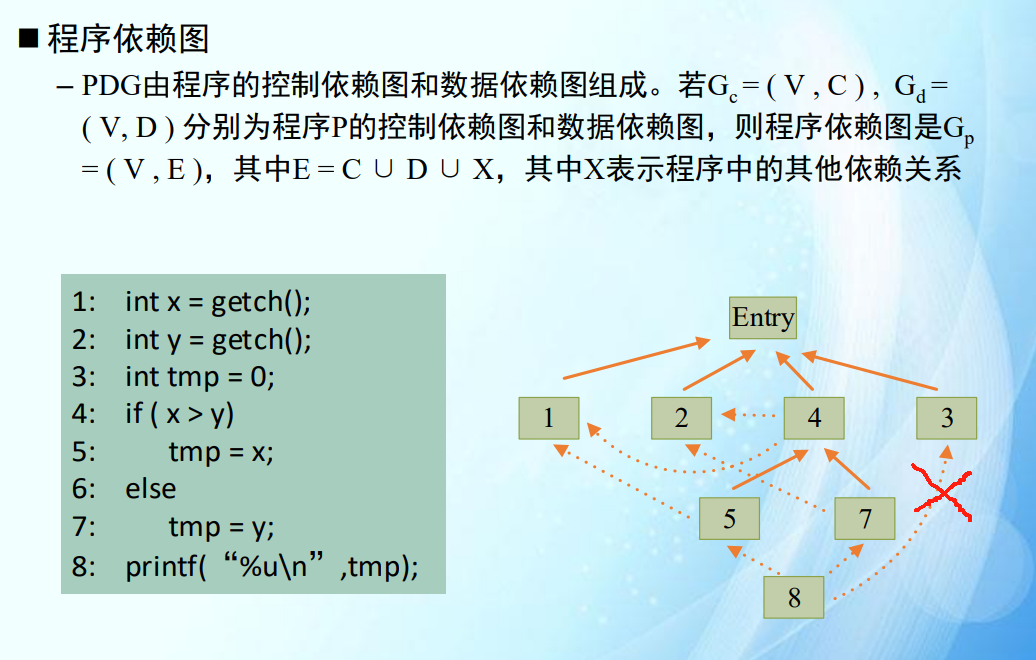
- 实线:控制流依赖;虚线:数据流依赖;(叉掉的是ppt错了)

- 新增的红线是数据依赖。
- PDG 统一不考虑指向自己的依赖边。考试不考 for 循环,换为 while。

程序切片

基于数据流方程求解程序切片(不考)


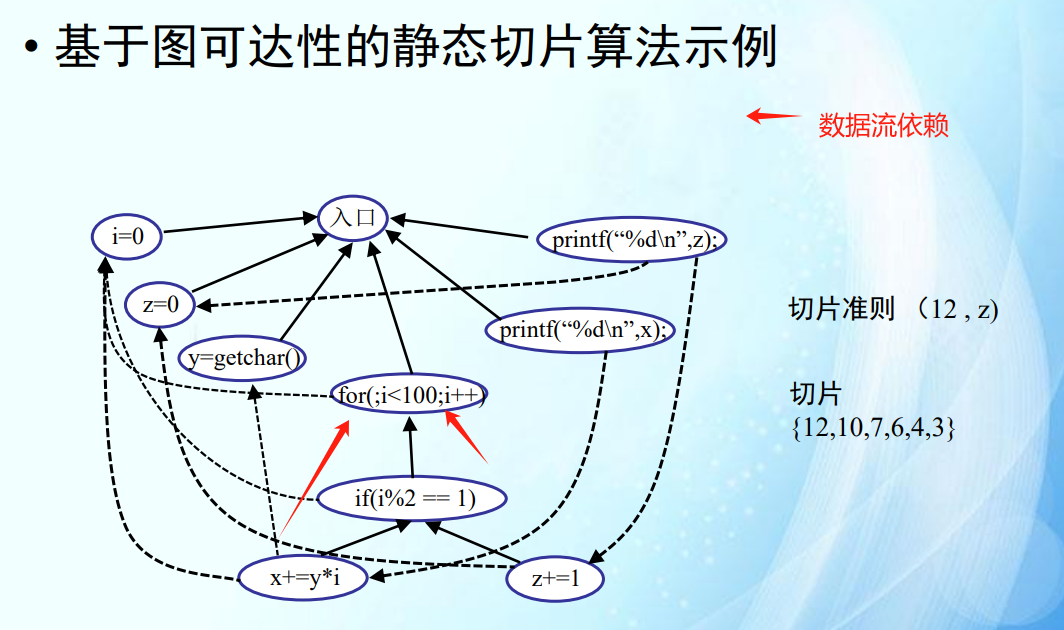
基于图可达性的静态切片计算(考点)



动态切片

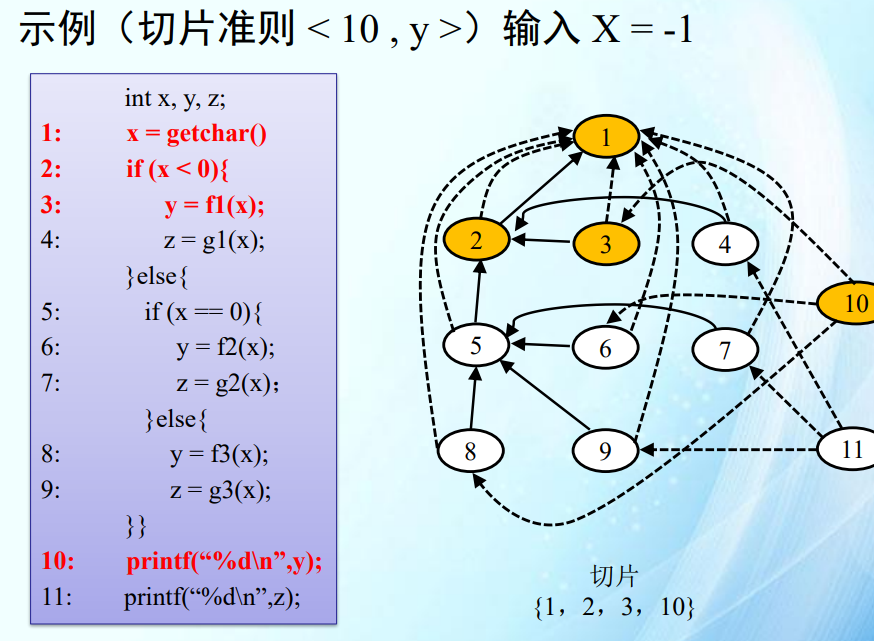



N=1,循环只有一次,所以切片不应该包含7。

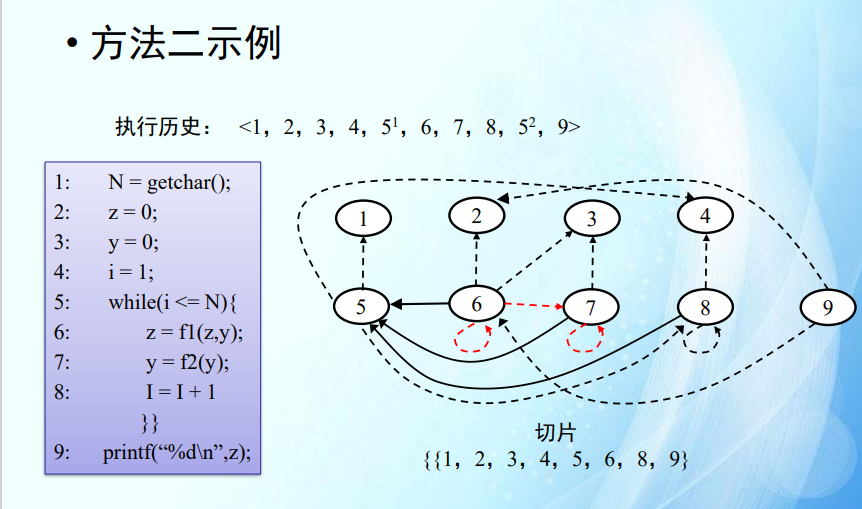
第二轮根本执行不到7。红色边需要删除。
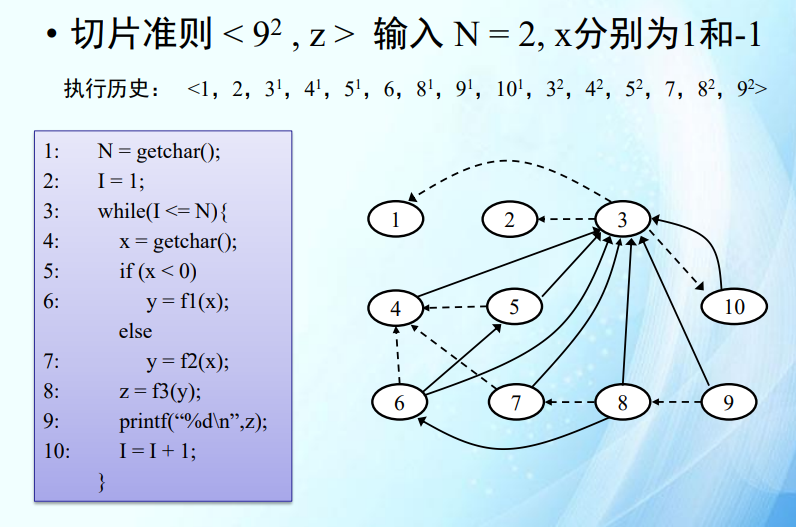

方法三之后不看。考试不考。
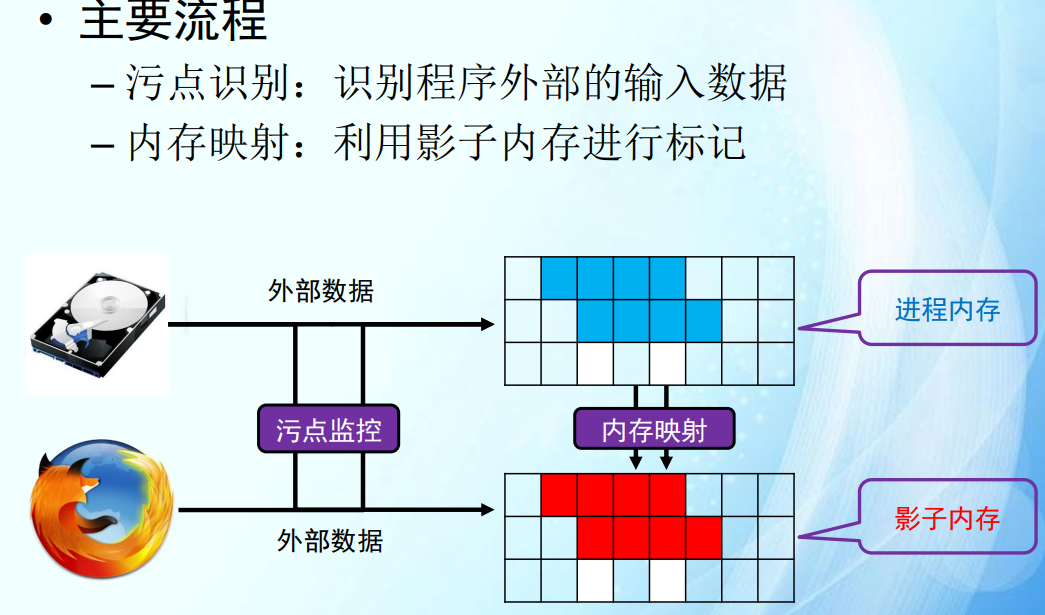
5 污点分析
考点 :污点分析:会应用程序切片的可达性分析等技术。不会出难题,会基于汇编码。
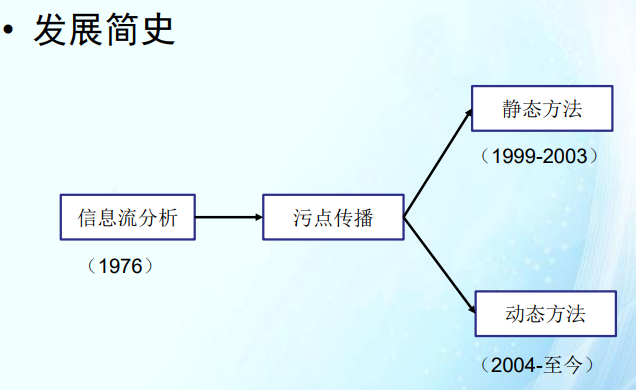
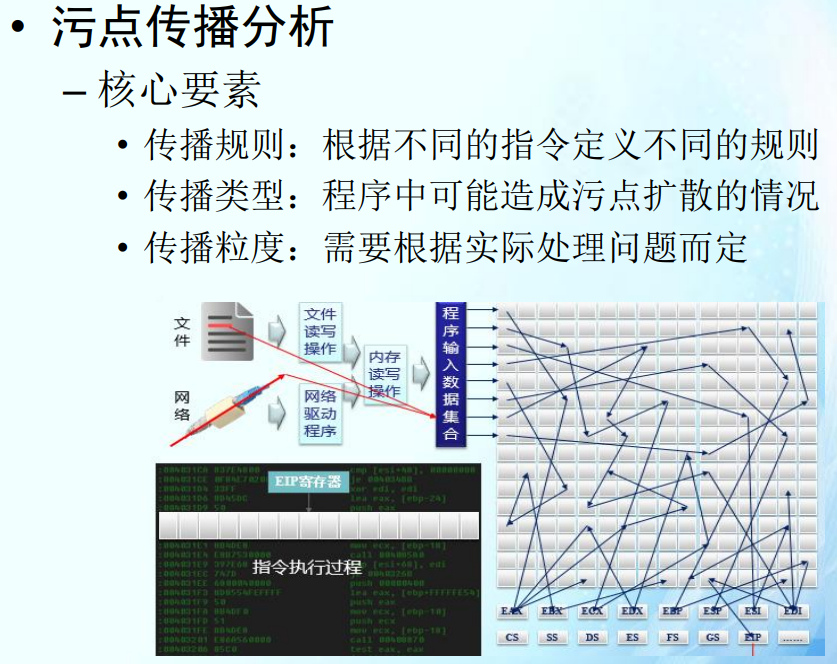
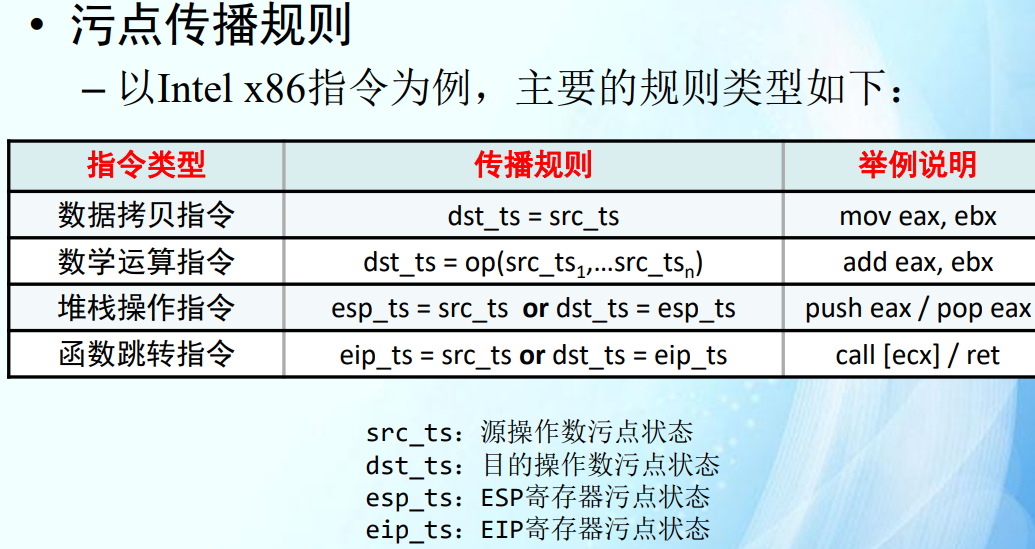
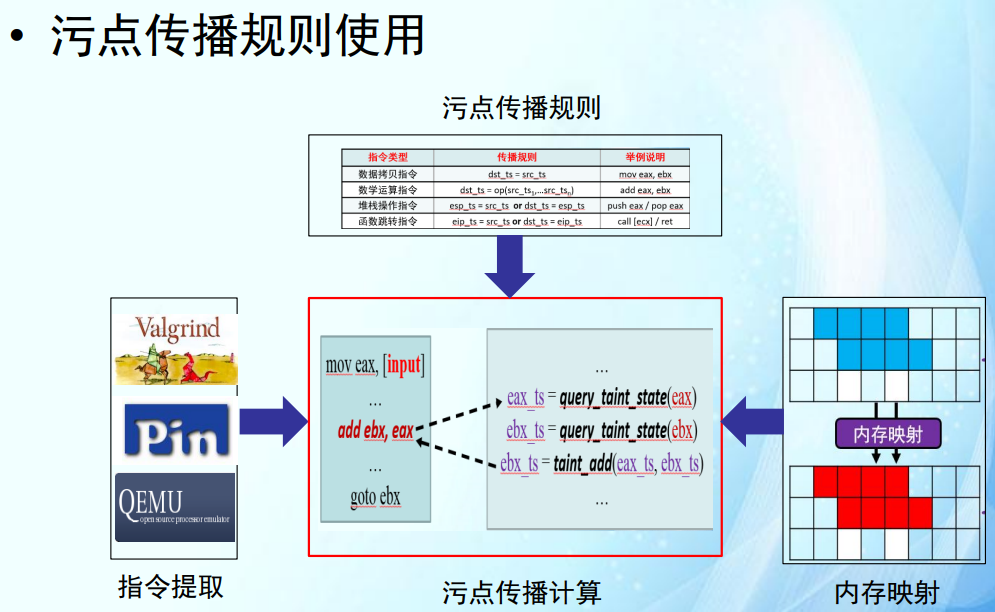
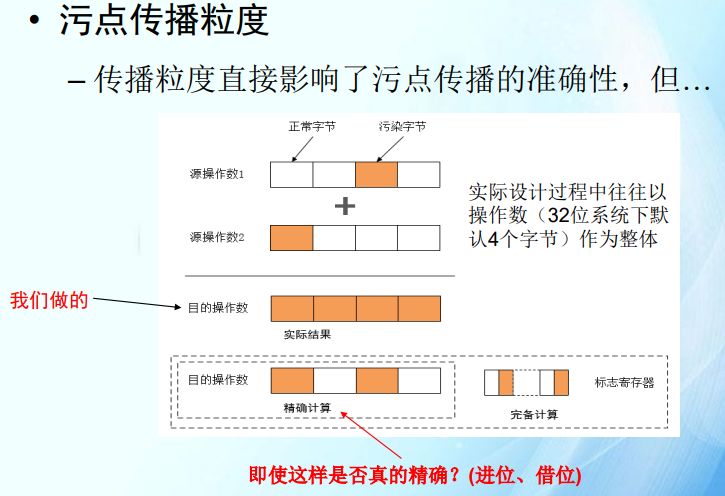
污点传播


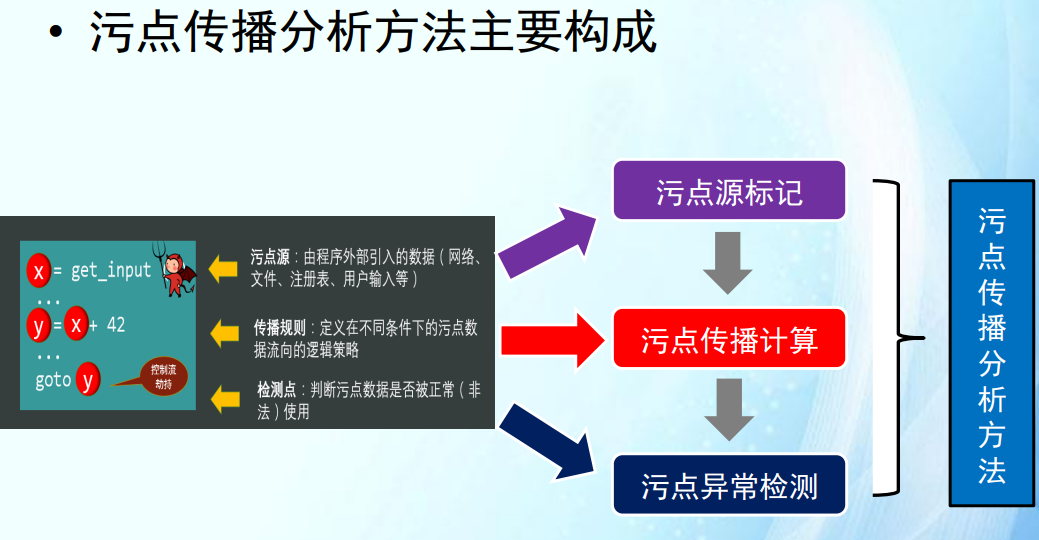


- 用户级监控缺陷:无法跟踪内核指令。许多安全漏洞可能涉及内核态的操作,例如缓冲区溢出、权限提升攻击等。如果监控工具无法跟踪内核态,将无法全面检测和分析这些安全漏洞,可能导致潜在的安全威胁被忽视。



当内存指针本身是污点时:任意地址读、写




6 模糊测试(了解概念即可)
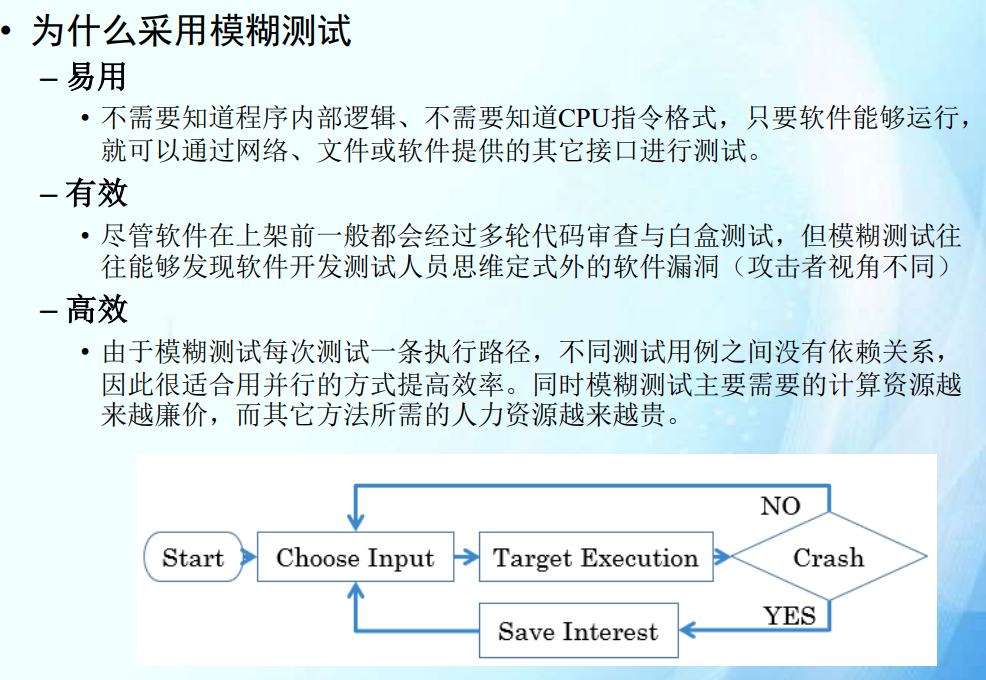
考点: 模糊测试:不会出综合题。重点是AFL。
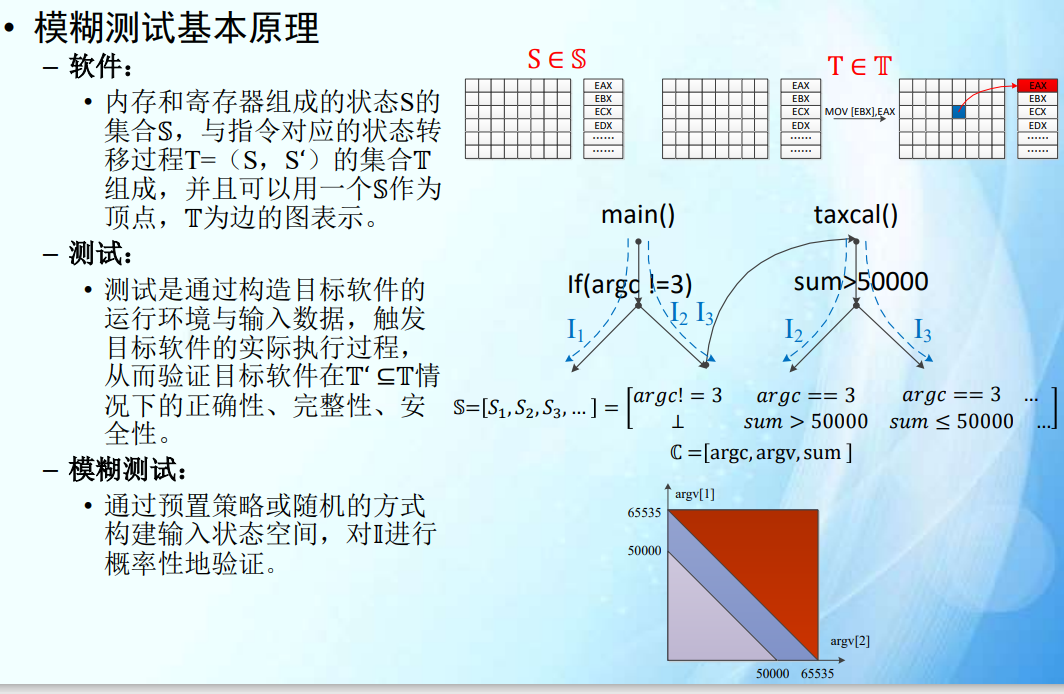
- 模糊测试
- 基本原理
- AFL基本原理,实现细节(插桩,覆盖率获取)
- 算法优化(不涉及)










略。。
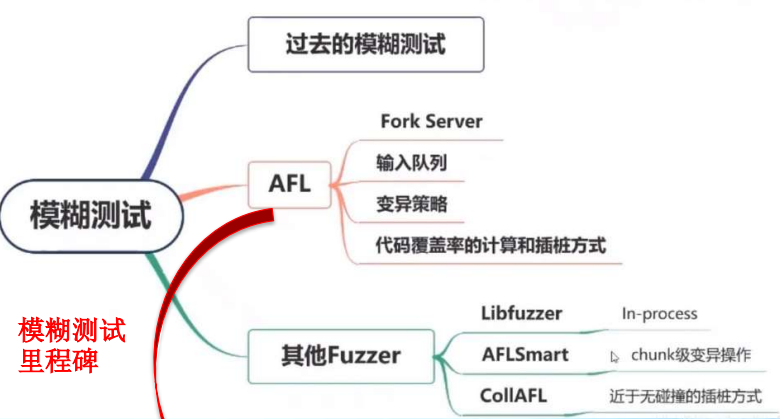
反馈式模糊测试 AFL




7 符号执行技术(重点)
考点 符号执行:重点考基本思路和方法,会用符号执行分析给定程序。注意动态/静态符号执行的区别,可能会考动态符号执行。混合符号执行的概念。常考题型:执行树。
- 符号执行
- 主要做什么
- 路径表达式
- 执行树(如何画,经常出现的题型)
- 动态符号执行(基本概念),与静态的区别,给定输入能否走到指定分支
经典符号执行






路径条件


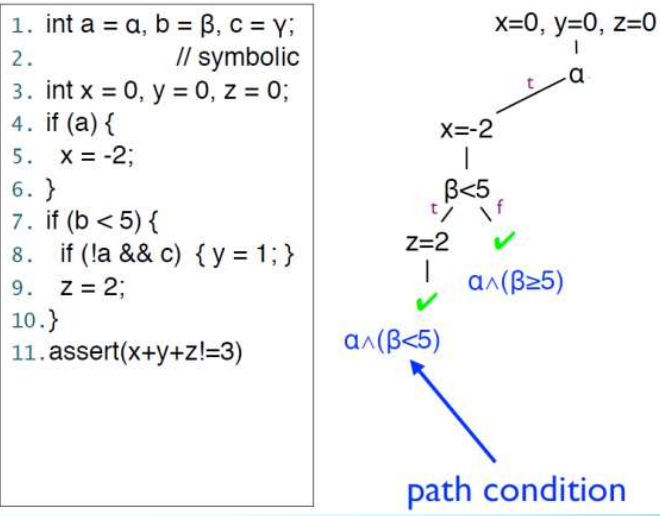


执行树


注:上图loc:13的z值ppt里有误,以后面的ppt为准。z值此时不需要更新。





过程内分析、过程间分析


动态符号执行(考概念)


并行符号执行(非重点)

选择符号执行(非重点)



8 网络协议逆向分析
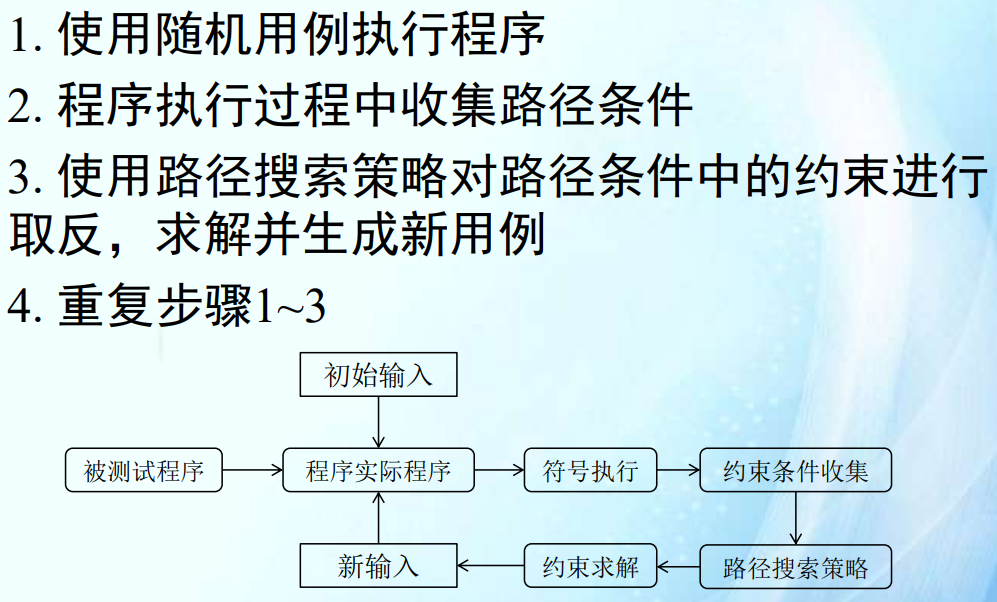
考点:考基本概念,可能会结合污点传播(基于分隔符的划分方法)、程序切片(基于字段来源回溯的方法,动态后向数据切片)。最好熟悉这一章三个方法的流程。状态机不考分析题。
- 网络协议逆向(基本概念)
- 和污点,切片相关的内容,可能会进行结合
- 基于分隔符(污点)
- 基于消息处理指令(调用栈恢复)
- 基于字段来源回溯(切片)
- 字段关系识别
- 密码算法逆向恢复(基本了解)
- 和污点,切片相关的内容,可能会进行结合
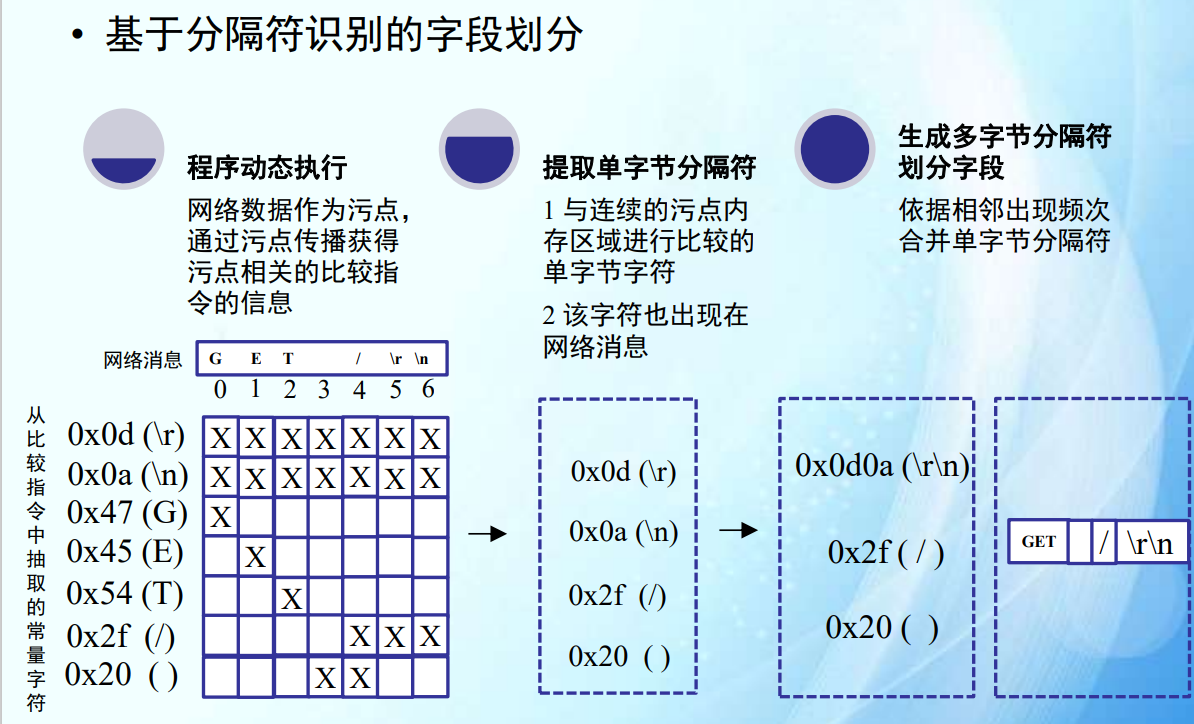
字段划分





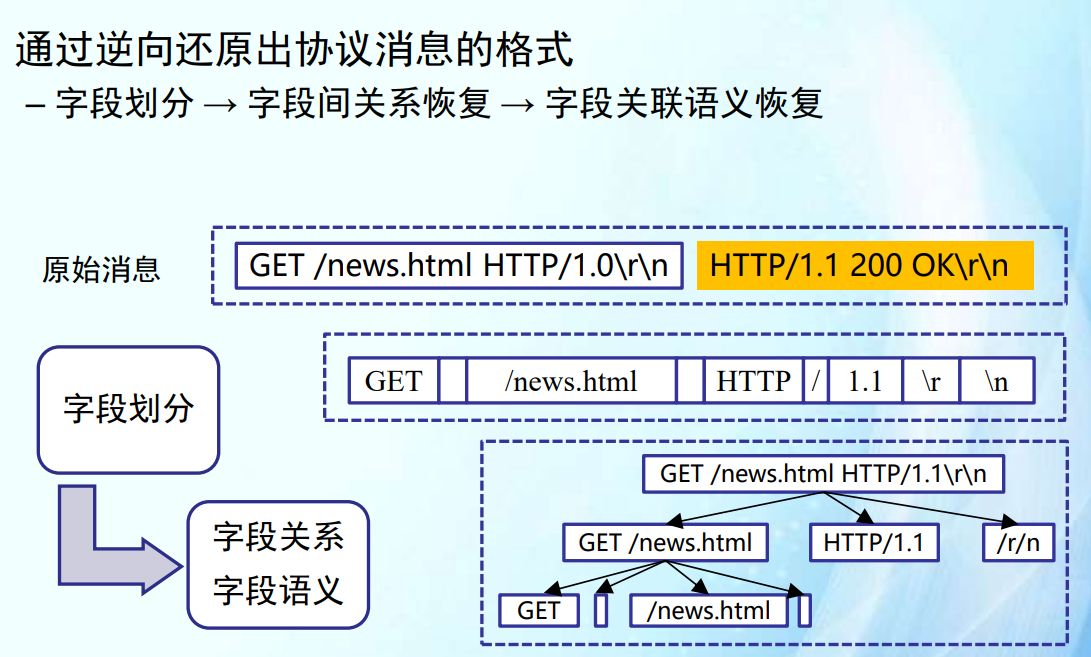


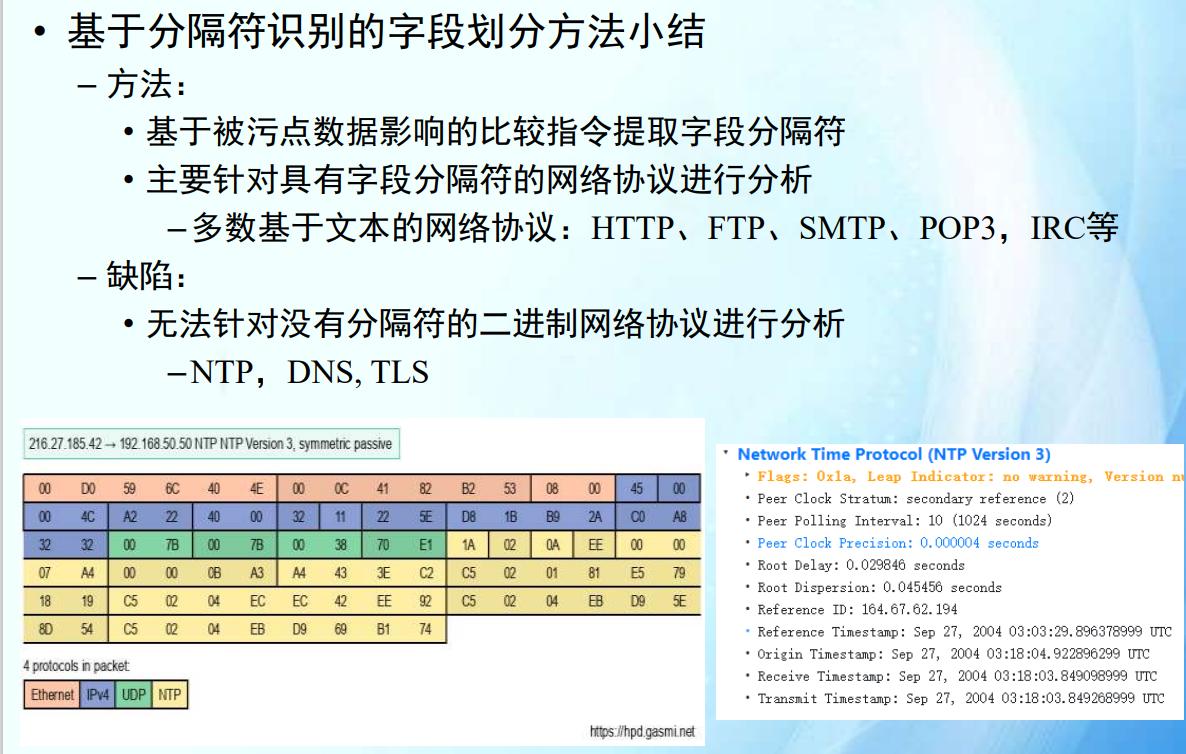
基于分隔符的划分方法


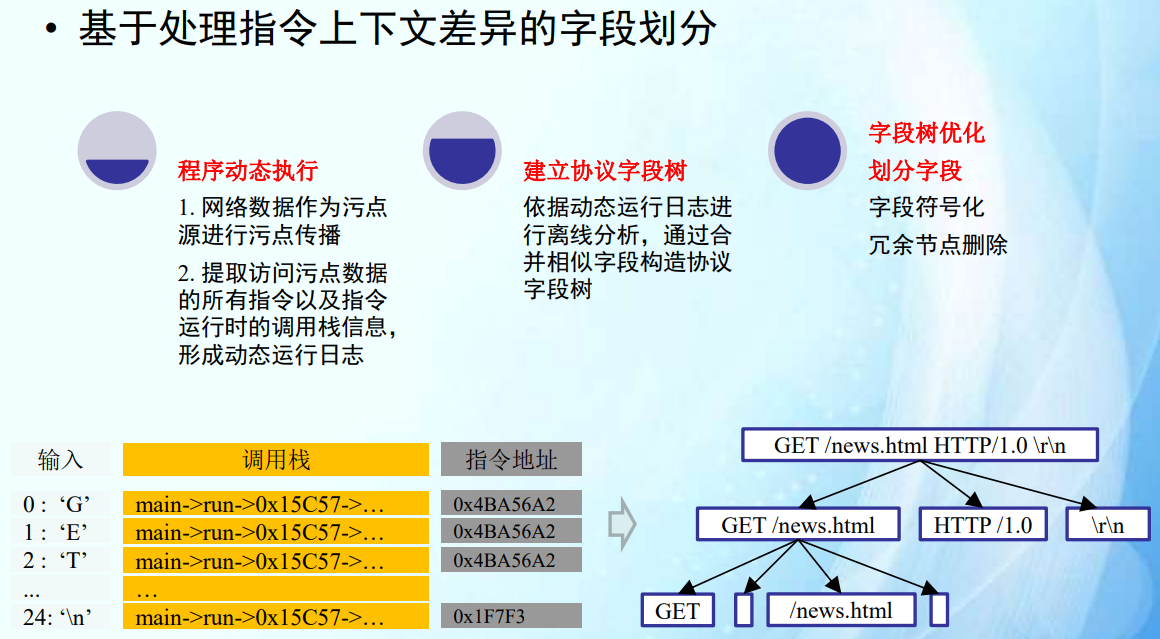
基于消息处理指令上下文差异的划分方法




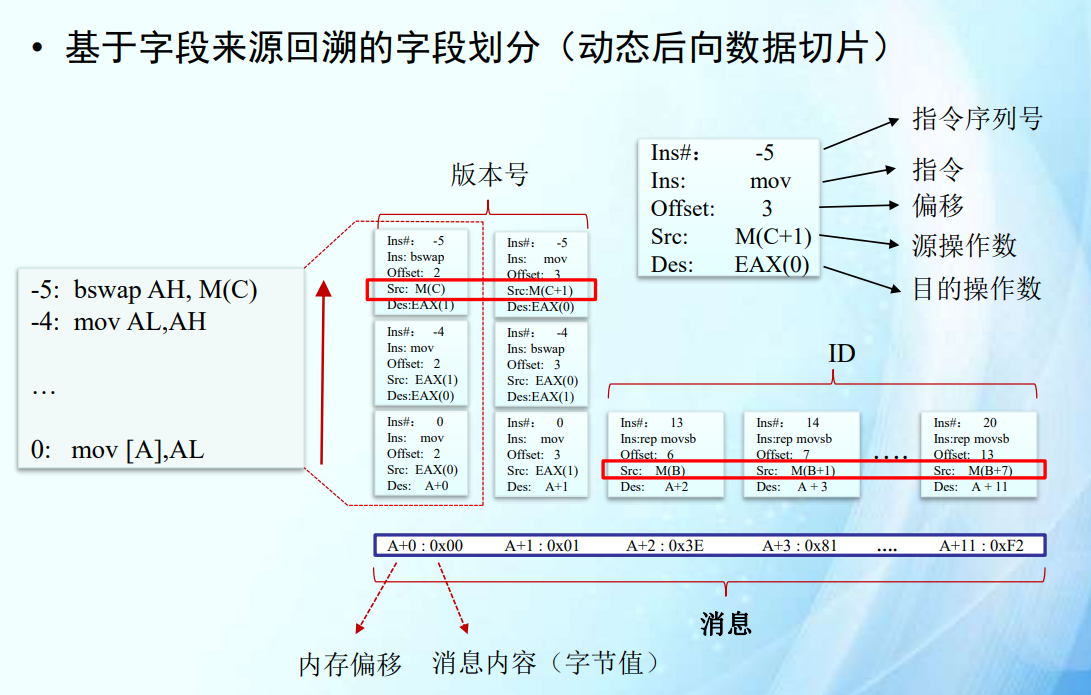
基于字段来源回溯的划分方法
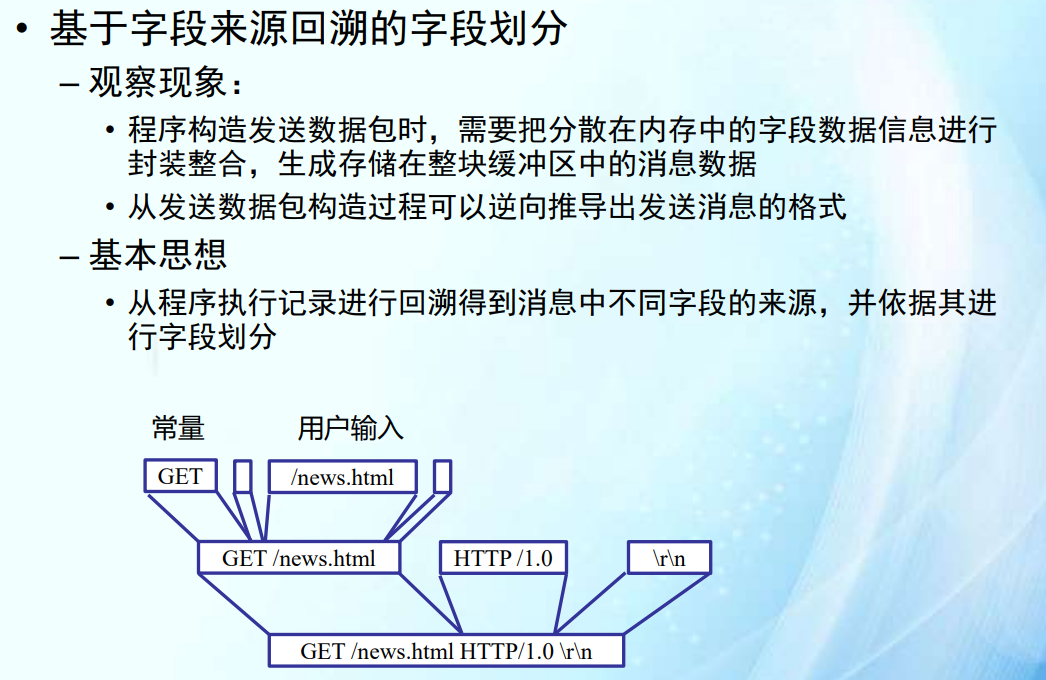
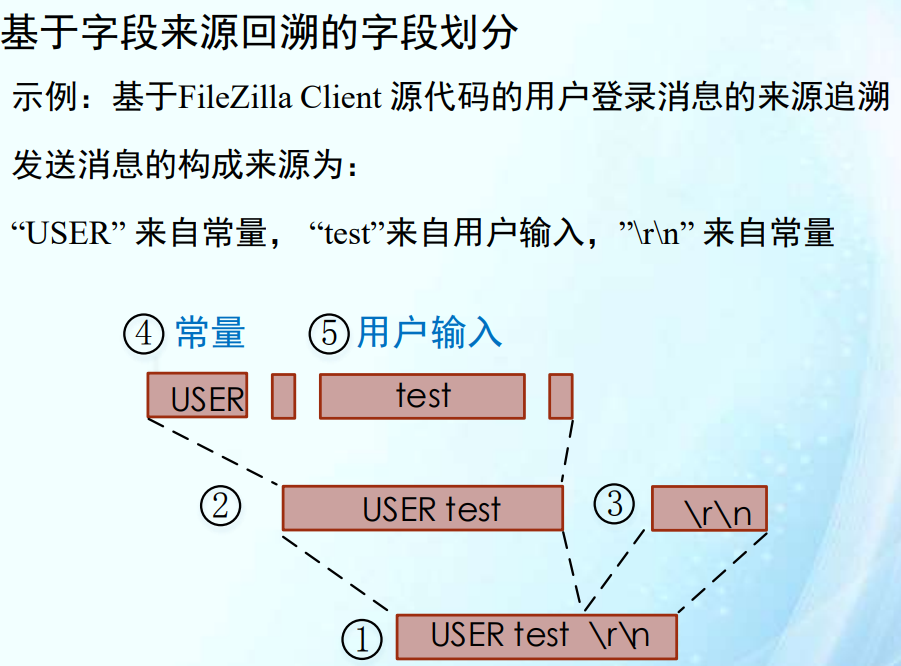


基于切片的字段来源回溯



字段间关系识别




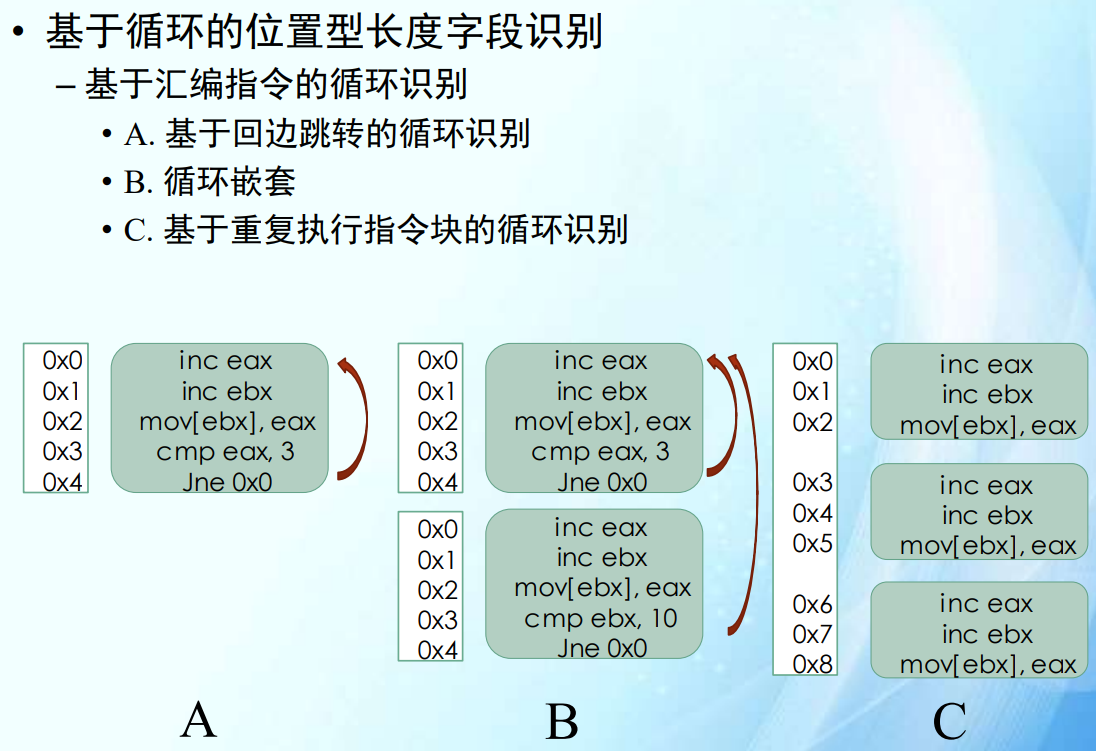
位置型字段




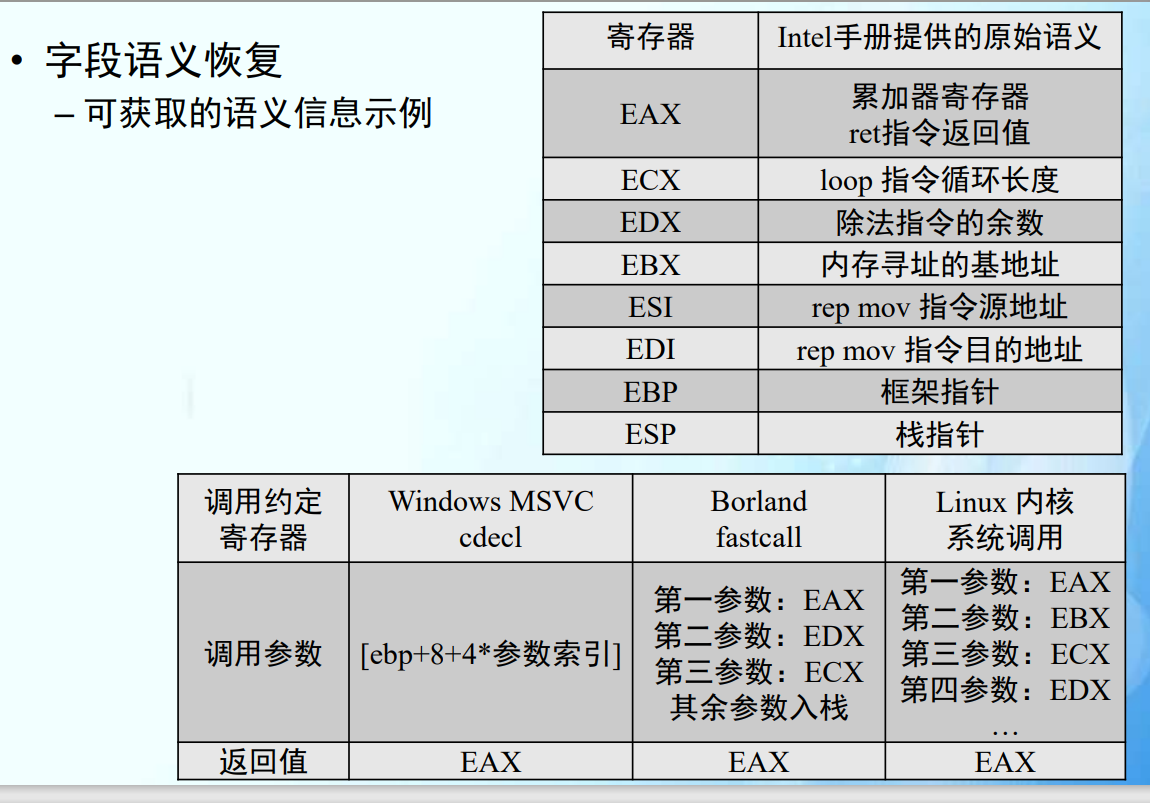
字段语义恢复








协议状态机恢复


略。

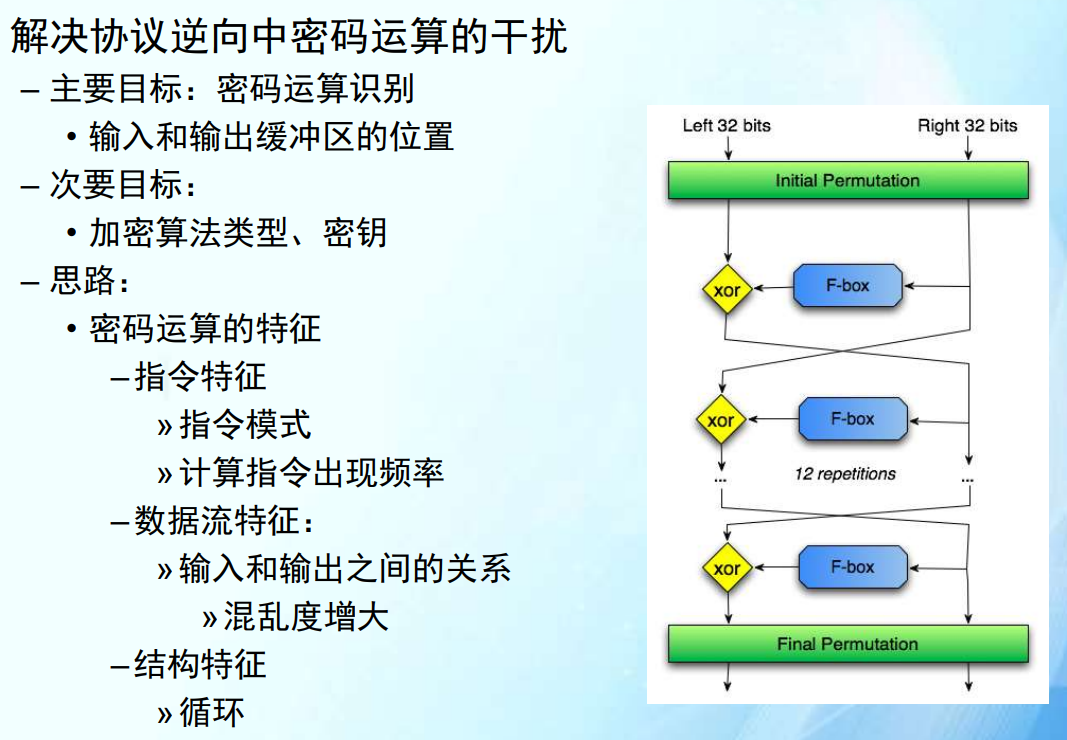
密码运算逆向恢复(了解即可)




9 软件漏洞机理分析
考点: 识别代码中可能触发漏洞的脆弱点。需要掌握ppt中给出的示例
- 软件漏洞原理
- 漏洞类型
- 漏洞分析利用(综合)
- 防护机制(基本概念)
- 软件漏洞机理
- 脆弱点分析
- 路径分析


- 漏洞内容略。
10 软件漏洞利用
考点: 会考漏洞利用。不会只靠各类漏洞的概念,需要在理解概念的基础上解题。
- 软件漏洞利用
- 最后综合题,ppt中实例
- 堆中脱链的计算