本文转载自 Agoda Engineering,介绍了在实际应用中,如何应对 Kafka 负载均衡所遇到的各种挑战,并提出相应的解决思路。本文简要阐述了 Kafka 的并行性机制、常用的分区策略以及在实际操作中遇到的异构硬件、不均匀工作负载等问题。通过深入分析这些挑战,并提供具体的解决方案,本文旨在帮助读者更好地理解和应用 Kafka 的负载均衡技术,从而提高系统的整体性能和稳定性。
以下大部分内容翻译自原文 how-we-solve-load-balancing-challenges-in-apache-kafka,并已获得原作者同意。
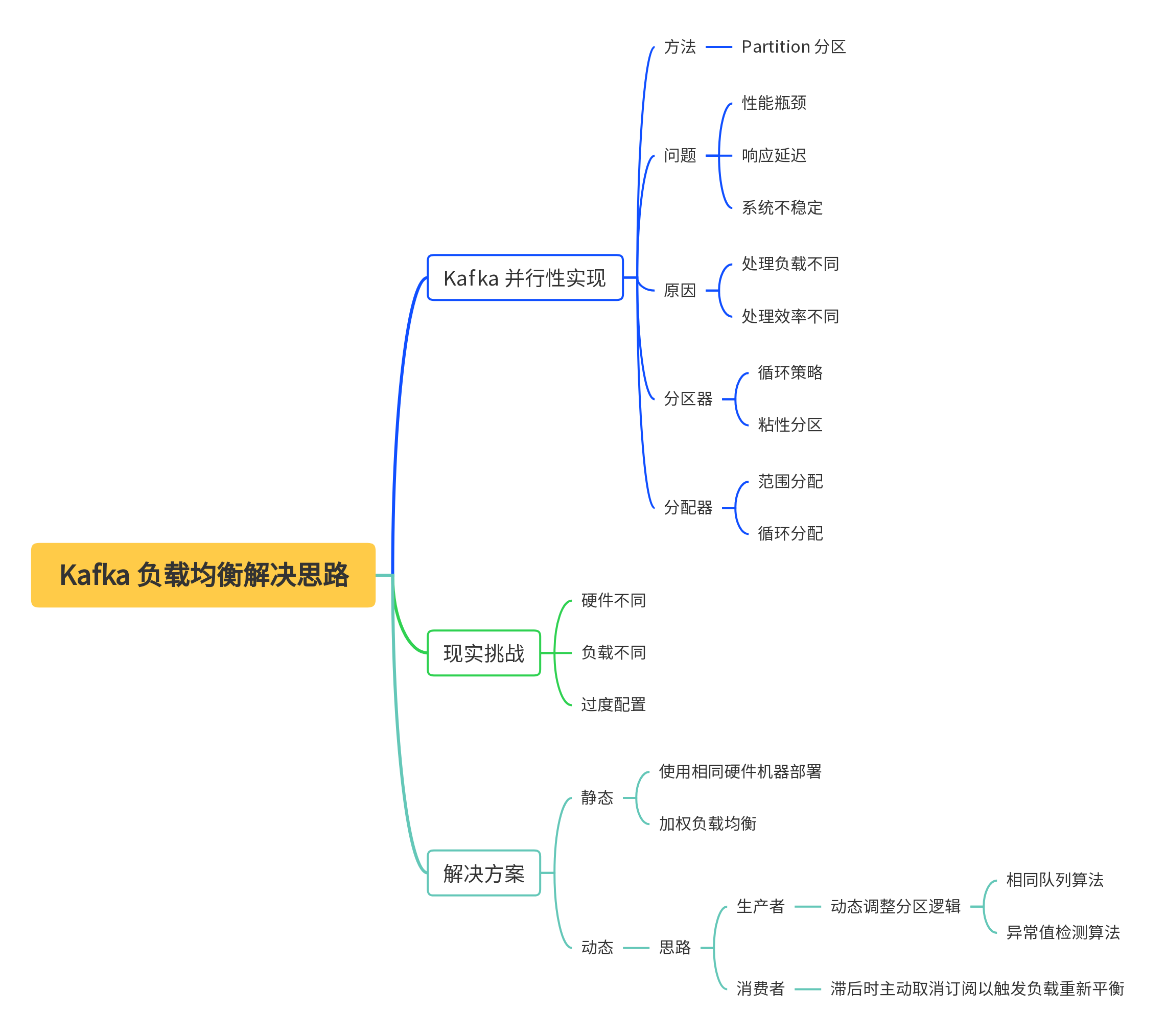
思维导图
Kafka 并行性
Kafka 通过分区来实现并行性,如下图所示,生产者(Producer)产生的消息会按照一定的分区策略分配到多个分区(Partition)中,消费组中的每个消费者会分别负责消费其中的若干个分区。
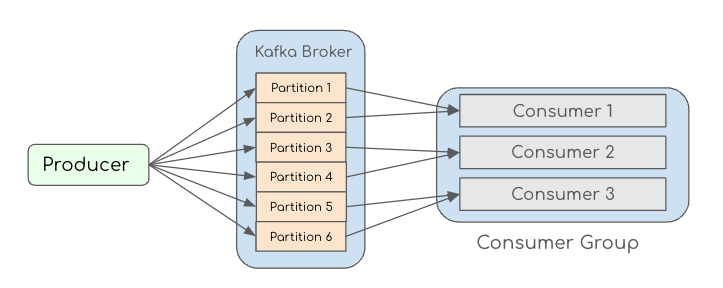
分区策略:
- 轮询(Round Robin):默认情况下,Kafka 使用轮询策略将消息均匀地分配到所有分区。
- 哈希(Key Hashing):如果消息有分区键,Kafka 会对键进行哈希计算,将消息分配到特定的分区。
- 自定义分区策略:开发者可以实现自定义的分区器(Partitioner)逻辑,以满足特定需求。
如果要使用轮询或者哈希策略来达到"负载均衡"的目的,那么需要满足以下 2 个假设:
- 消费者拥有相同的处理能力,
- 消息的工作量相等。
然而,在实践中,这些假设往往不成立。
现实挑战
1. 异构硬件
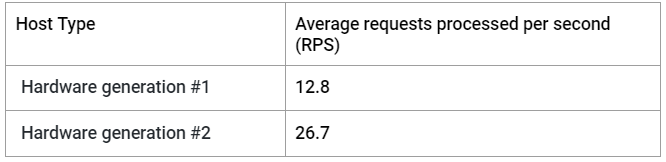
不同代的服务器硬件性能不同,导致处理速率存在差异。例如,使用不同代硬件进行处理的基准显示性能存在显着差异:
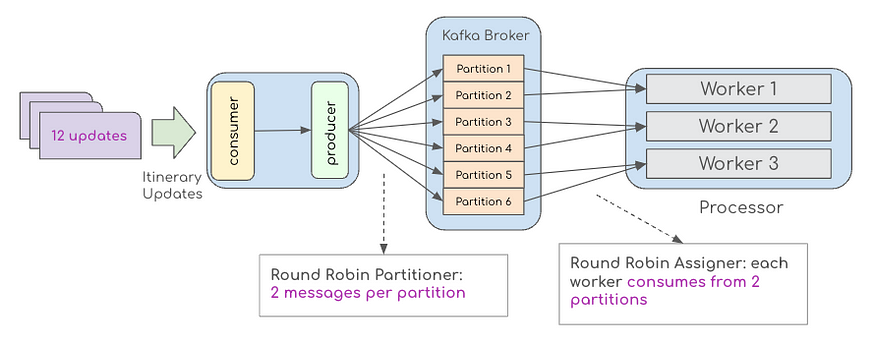
2. 每条 Kafka 消息的工作负载不均匀
下图显示了在一个时间窗口内到达的 12 条消息。在这里,生产者向该主题中的六个分区中的每一个发布两条消息。因此,每个 worker 消耗来自 2 个分区的数据,这意味着每个 worker 需要处理 4 条消息。
不同的消息可能需要不同的处理步骤集。例如,处理消息可能涉及调用第三方 HTTP 端点,并且不同的响应大小或延迟可能会影响处理速率。此外,对于涉及数据库操作的应用程序,其数据库查询的延迟可能会根据查询参数而波动,从而导致处理速率发生变化。
3. 过度配置问题
由于工作负载和处理效率不同,为了达到系统吞吐量的需求,可能会出现过度配置问题,从而导致资源浪费。
假设我们的高吞吐量和低吞吐量的处理速率分别为 20 msg/s 和 10 msg/s(根据表 1 中的数据进行简化)。使用两个较快的处理器和一个较慢的处理器,我们预计总容量为 20+20+10 = 50 条消息/秒。但是,当保持消息的循环分配时,我们无法达到此容量。下图显示了如果流量持续达到每秒 50 条消息时会发生什么情况。
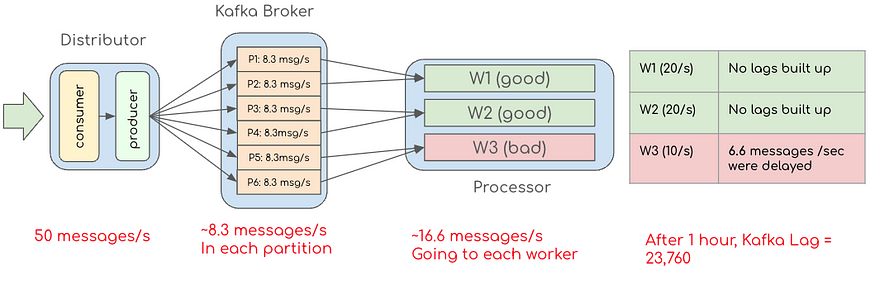
从这个例子中我们可以看到,我们的处理器服务一次最多只能接受 30 条消息,以防止滞后并确保及时传递更新。
在这种情况下,要实际每秒处理 50 条消息,我们必须总共扩展到 5 台机器,以保证及时处理所有消息。由于这种不适当的分配逻辑(66.7%的过度配置),我们会向该系统过度配置额外的两台机器。
为了每秒处理 50 条消息,我们需要扩展到五台机器以确保及时处理所有消息。由于这种不适当的分配逻辑(66.7% 的过度配置),这会导致向该系统过度配置两台额外的机器。
静态解决方案
1. 在相同的 Pod(机器)上部署
考虑控制服务部署中使用的硬件类型以缓解问题。如果您在虚拟机上部署服务并拥有充足的资源和性能相同的硬件,则此方法是可行的。
然而,由于成本效益和灵活性下降,在私有云环境中通常不建议采用这种策略,主要是因为同时升级所有现有硬件可能具有挑战性。如果它非常适合您的情况,则可以使用Kubernetes 关联性将 Pod 分配给某些类型的节点。
2. 加权负载均衡
如果容量是可预测的并且大部分时间保持静态,则为不同的消费者分配不同的权重可以帮助最大限度地利用可用资源。例如,在为表现较好的消费者赋予更高的权重后,我们可以将更多流量路由给这些消费者。
动态解决方案
虽然我们可以估计消息的容量和工作负载来设计静态规则来确定加权负载平衡策略,但由于以下几个因素,这种方法在实际生产环境中可能并不总是可行:
- 消息的工作负载并不统一,这使得估计机器容量变得困难。
- 依赖关系(例如网络和第三方连接)不稳定,有时会导致实际处理中的容量发生变化。
- 该系统经常添加新功能,增加额外的维护工作以保持权重更新。
为了解决这些问题,我们可以动态监控每个分区中的当前滞后并根据当前流量状况做出相应响应。
有 2 种思路:
- 生产者角度:使用自定义算法根据滞后的消息数量来确定每个分区的流量,这种生产者称为滞后感知生产者(Lag-aware Producer)。
- 消费者角度:这些消费者旨在监控当前滞后的消息数量,并可以在必要时取消订阅以触发负载重新平衡。通常,可以采用自定义的重新平衡策略来调整分区分配。这种消费者称为滞后感知消费者(Lag-aware Comsumer)。
1. 从生产者角度出发
如此图所示,生产者可以使用自定义算法根据滞后确定每个分区的流量。为了减少对 Kafka 代理的调用次数,系统可以维护一个内部延迟缓存,而不是在发布每条消息之前调用 Kafka 代理。
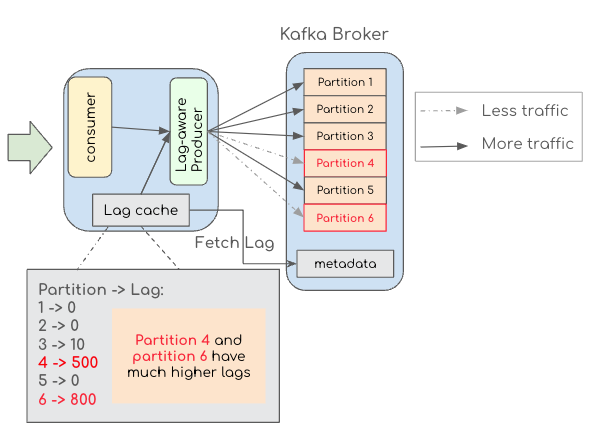
使用滞后数据,定制的算法被设计为向经历高滞后的分区发布更少的流量,向低滞后的分区发布更多流量,以平衡每个分区上的工作负载。当滞后平衡且稳定时,此方法应确保消息的均匀分布。
不适用情况:
- 纯消费者应用程序:您的应用程序不控制消息生成。
- **多个消费者组:**当生成的消息被多个消费者组消费时,生产者可能会为其他消费者组产生不必要的倾斜负载,因为滞后只是特定于一个消费者组的信息。
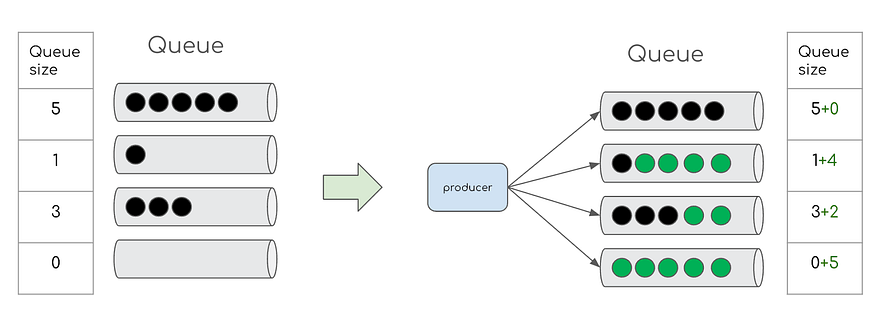
相同队列长度算法
该算法将每个分区滞后视为处理的队列大小。获取滞后信息后,它会发布适当数量的消息以填充短队列。此方法更适合由于异构硬件而导致的倾斜滞后分布,其中高性能 Pod(机器)在大多数情况下能够更快地处理。
异常值检测算法
该算法利用统计方法来确定所有分区的上离群值,并暂时停止那些慢速离群值的发布过程。在原文章中,针对 Agoda 的特定需求,他们提出了 IQR(四分位距)和 STD(标准差)异常值检测算法。算法流程图如下所示。
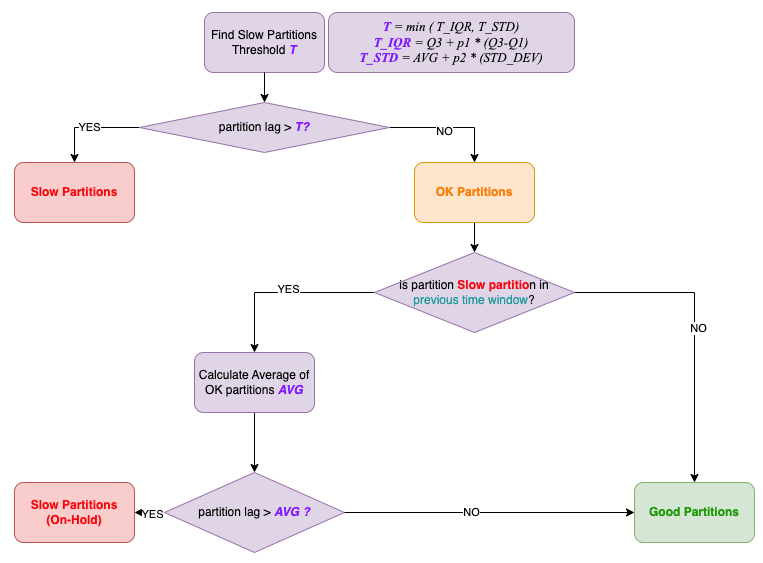
- 慢速分区:(已关闭)由于存在延迟,这些分区的消息生成已停止。
- 好的分区:(打开)照常发布并均匀分发到所有好的分区。
- OK 分区:(观察/半开放)为了提高性能不佳的机器的性能,当系统尝试将慢速分区提升为良好分区时,会添加一个观察期。通过仅生成一小部分消息并进行观察,可以将该观察阶段优化为"半开放"状态。当滞后获取间隔相对较长时,半开放是有益的,因为它可以防止消费者延迟等待传入消息而更新的滞后数据尚未查询的情况。
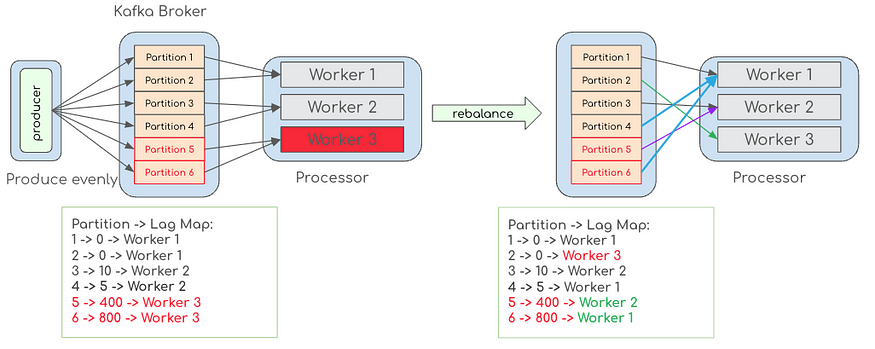
2. 从消费者角度出发
这里 Adoga 提出的思路是:遇到高延迟的实例可以主动取消订阅主题以触发重新平衡。在重新平衡期间,可以使用自定义的分配器来平衡所有消费者实例之间的分区。
触发重新平衡的成本非常昂贵,因为急切的重新平衡会停止消费者组中的所有处理。Kafka 2.4中引入的增量协作再平衡协议已经最大限度地减少了性能影响,允许更频繁的再平衡以更好地分配每个分区上的负载。
为了增强重新分配的灵活性,分区的数量应该大于 worker 的数量。这一比率应根据应用程序而有所不同,并假设一个工作线程至少可以处理来自一个分区的负载以避免饥饿。
总结
本文从 Kafka 并行性的一般实现出发,探讨了 Kafka 实现负载均衡在现实实践中可能遇到的各种挑战,并从静态调整和动态调整两个方面给出了解决思路,特别注重讨论了动态调整策略,并分别从生产者和消费者的角度提出了解决方案。
总之,通过在 Kafka 中实现负载均衡,可以有效地将工作负载分配到可用资源之间,从而显著提高服务性能。具体的算法和策略需要根据实际情况进行选择和调整。