在机器学习中,聚类是一种无监督学习,那对于聚类结果,我们应该如何评估其好坏呢?我们这里介绍两类性能度量。
1.外部指标
**外部指标的意思是将聚类结果与某个"参考模型"进行比较。**哎其实也很好理解,就相当于老师批改卷子一样,肯定是对着参考答案改,同学们的答案肯定是千奇百怪的啦~,这里同学们的答案就相当于各种各样的聚类结果,参考答案就相当于参考模型呗(有没有感觉有点像监督学习)
我们先来看看西瓜书中的一些定义:

哇,这公式这么复杂呀,这是干嘛的?别慌别慌,其实不难理解,它是把聚类结果和参考模型的进行对比,就相当于你老师在给你批改卷子的过程,它是两个点两个点进行对比 的,SS意思就是(same,same)就是你聚类结果里面的两个点和参考模型里面的两个点的分类是一样的,SD(same,different)意思是聚类结果里面这两个点分类是一样的,但是参考模型这两个点分类是不一样的;后面的意思以此类推。它是遍历里面的所有点,假如说,我现在拿第一个点,然后遍历簇中的所有点对比,再拿第二个点,遍历编号大于2的所有点进行对比,然后以此类推。我们来看个例子,如下图

在我们这个例子中有5个点,给出了一个聚类结果,然后和参考模型对比,先拿点1和其余四个点对比,然后在那点2和大于2的三个点对比,以此类推,记录每个集合元素的个数,最后的总数就是上述的公式可以计算出。
基于上述的分组我们就可以导出一些常用的聚类性能度量外部指标:

我们依然拿上面的例子来理解这些公式,如下图
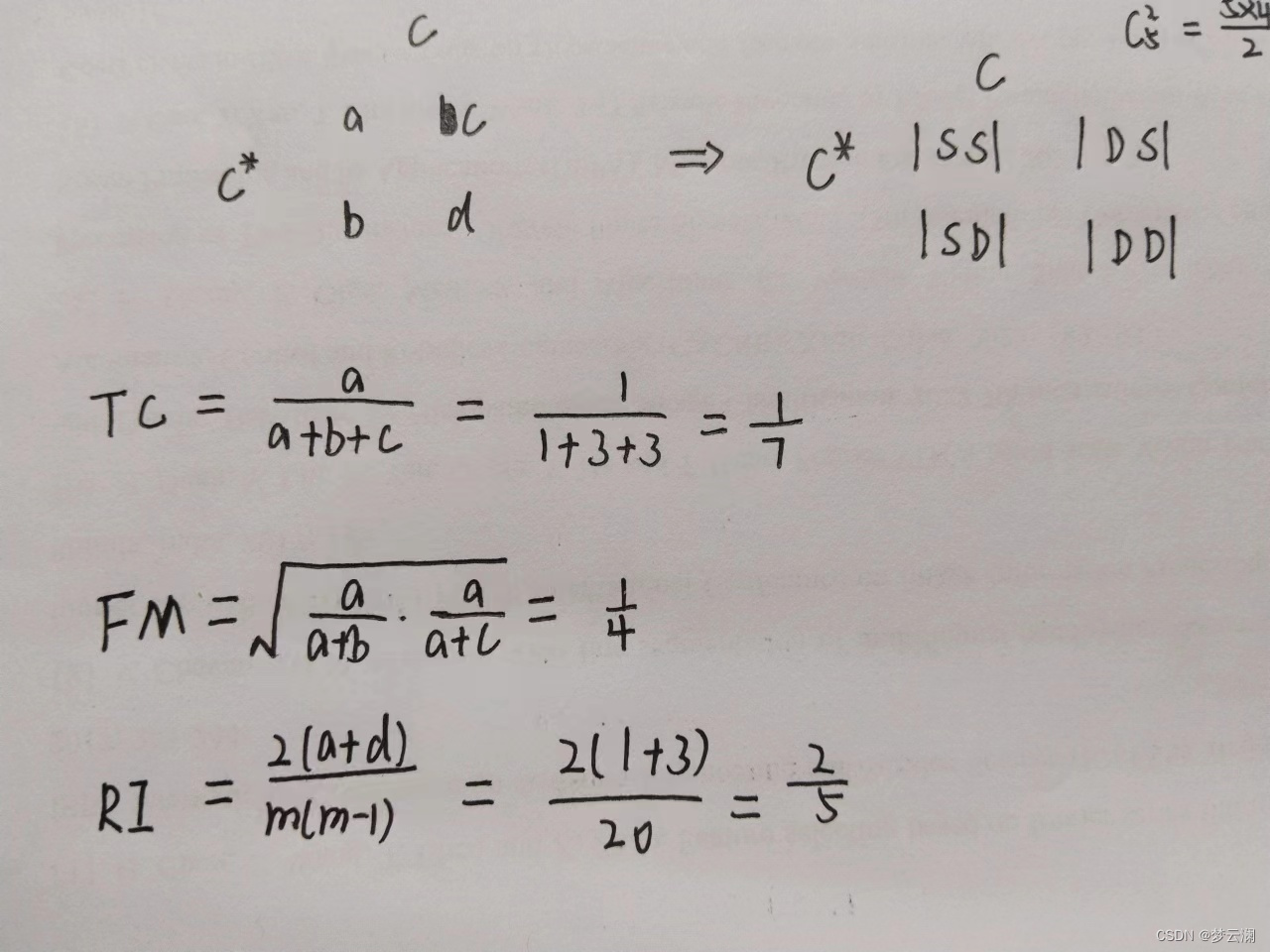
如图所示,我们把参考模型和聚类结果那样一放,小伙伴们有没有想到什么呀?是不是和下面的表有点相似呀
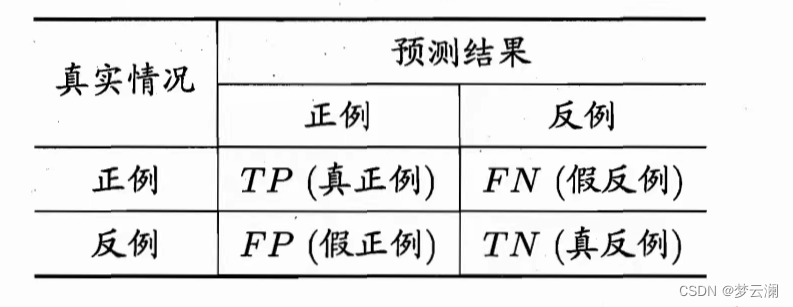
哎差不多的,你看看,SS不就相当于TP的位置嘛?其他也一样,那三个性能度量公式分子都和"TP""TN"有关,那肯定值越大越好呗。
2.内部指标
然后我们再来看看内部指标,先看一下书上的定义,如图:

哦豁,又一大坨,没关系,我们接着用例子说明,如图:
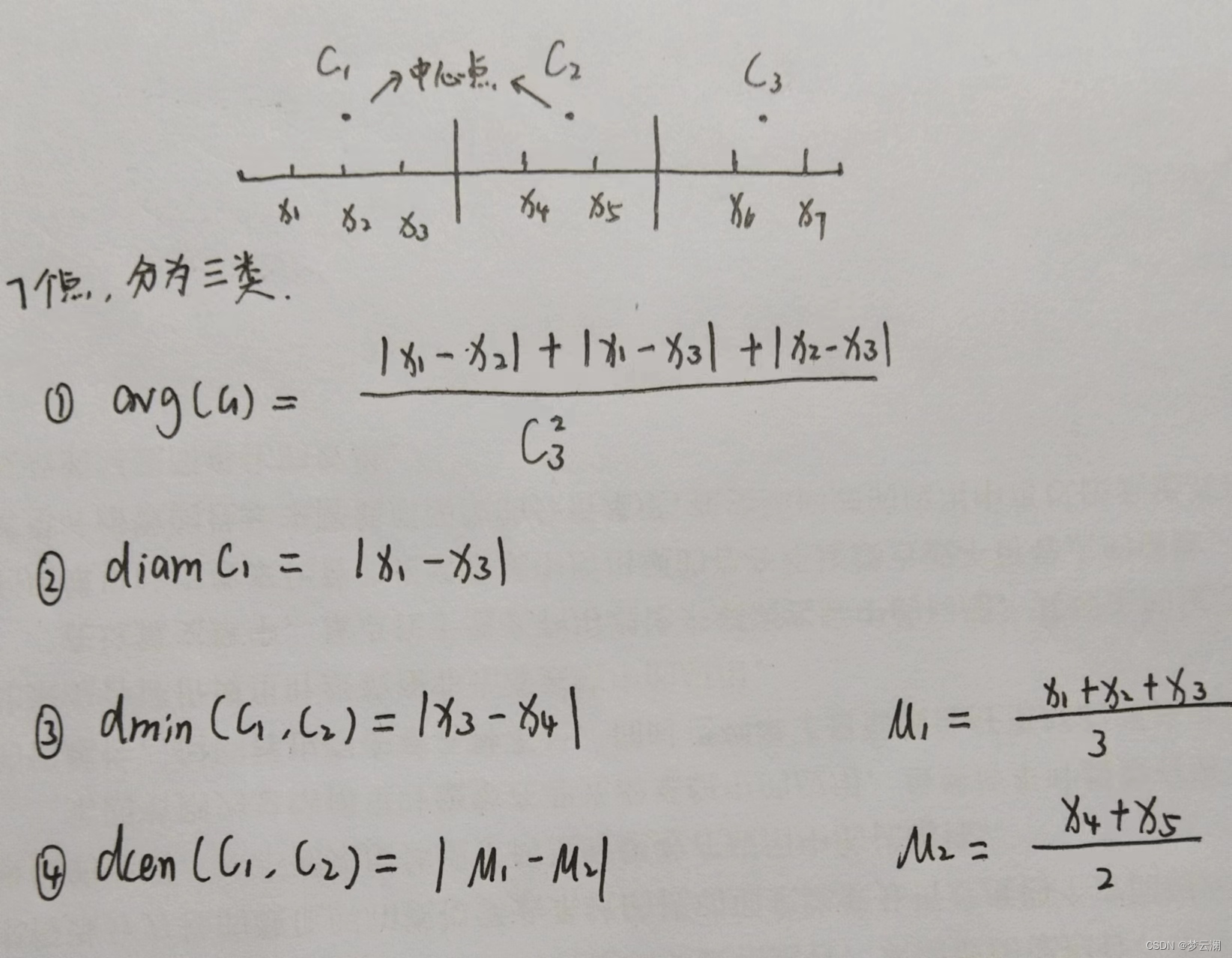
结合图中的例子再对应上述的公式,怎么样?不难理解叭~
此时,我们看一下内部指标

式子看着长,其实也不难昂,别慌,我们一起来看看,DBI的公式中其实就是把上述的四个公式组合一下,然后多了个求最大值函数和求和,然后这个DBI为什么越小越好?你看啊,公式里面分母的位置是两个簇中心点的距离那肯定是越大越好,分子是簇内样本间的平均距离,那肯定是越小越好,这样综合来看,最后肯定是DBI的值越小越好。
DI的式子分母是不同簇最近样本间的距离,那肯定是越大越好,分母是样本间的最远距离,那肯定是越小越好,这样样本越集中嘛,那整体来看,就是DI的值越大越好。
ok,这篇就到这里啦,欢迎小伙伴们批评指正~(图片知识来源于西瓜书,例子来源于b站up主致敬大神)