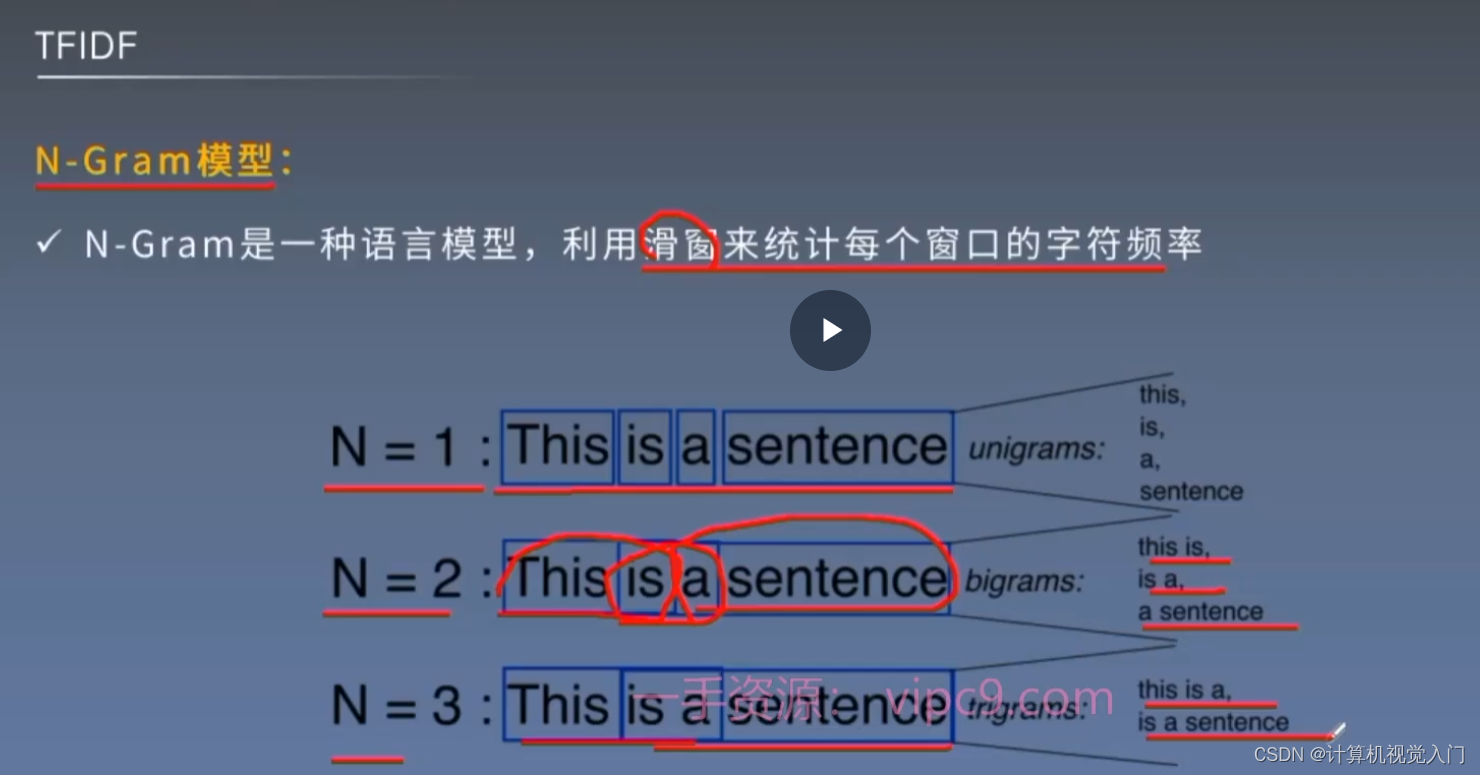
1. N-gram
n决定关联信息
2. TF____IDF
TF:词频

IDF:逆向序列
假如:TF * IDF 就是当前的文件,那么乘积反而更大!
因为它只出现在 特定的文章中!


TF-IDF 简介
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法,用于评估一个词在文档集合中的重要程度。它由两部分组成:
- TF(词频):一个词在文档中出现的次数。
- IDF(逆文档频率):该词在整个语料库中出现的频率的逆。
代码示例
下面的代码展示了如何计算一个文本语料库中每个词的TF-IDF值,并将每个句子编码为一个包含这些TF-IDF值的向量。
python
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文档
documents = [
"The cat sat on the mat",
"The dog sat on the log",
"The cat chased the mouse",
"The dog chased the cat"
]
# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 对文档进行TF-IDF转换
tfidf_matrix = vectorizer.fit_transform(documents)
# 获取词汇表
feature_names = vectorizer.get_feature_names_out()
# 打印TF-IDF矩阵
print(tfidf_matrix.toarray())
# 打印词汇表
print(feature_names)代码解释
- 创建示例文档:包含四个简单的句子。
- 创建TF-IDF向量化器 :使用
TfidfVectorizer类。 - 进行TF-IDF转换 :将文档列表传递给向量化器的
fit_transform方法,生成TF-IDF矩阵。 - 获取词汇表 :使用
get_feature_names_out方法获取词汇表中的词。 - 打印TF-IDF矩阵 和词汇表:分别打印TF-IDF矩阵和词汇表。
示例输出
假设上述代码的输出如下:
python
[[0. 0. 0. 0.469417 0.580285 0.469417 0.469417 0. 0. 0. 0. ]
[0. 0. 0. 0.469417 0.580285 0.469417 0. 0.469417 0. 0. 0. ]
[0.469417 0.469417 0. 0. 0. 0. 0.469417 0. 0. 0.580285 0.469417 ]
[0.469417 0.469417 0.469417 0. 0. 0. 0.469417 0. 0.580285 0. 0. ]]
['cat' 'chased' 'dog' 'log' 'mat' 'mouse' 'on' 'sat' 'the']每一行对应一个文档,每一列对应一个词汇表中的词。值是该词在该文档中的TF-IDF值。
解释图片中的步骤
-
切分所有的词,记词的数量为 n:
- 对文档进行词切分,统计每个词的数量,得到词汇表大小 n。
-
计算每个词的 TF-IDF 值:
- 使用上面代码中的
TfidfVectorizer计算每个词的 TF-IDF 值。
- 使用上面代码中的
-
对每个句子进行编码:
- 使用 TF-IDF 值将每个句子编码为一个向量,向量的维度为 n。如果一个词在句子中出现,其值为该词的 TF-IDF 值,如果未出现则值为 0。
-
降维操作:
- 由于 n 可能很大,可以使用 PCA、SVD、LDA 等方法对向量进行降维。
这个过程可以将文档转化为向量表示,便于后续的机器学习和数据分析。