【算法分析】
● DFS 序
DFS 序表示从根结点开始对树进行 DFS 所得的结点遍历顺序。
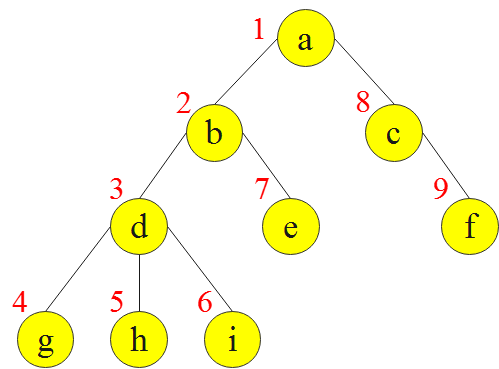
易得上图的 DFS 序为:1,2,3,4,5,6,7,8,9。可见,通过 DFS 序,可将一棵树映射为一个一维数组。
++假设以某结点 u 为根的子树大小为 cntu,u 在整棵树中的 DFS 序为 dfsu,则可得结点 u 的所有子树对应的 DFS 序区间为++++dfs\[u,dfsu+cntu-1]++。 → 这条性质是编写本题代码的关键。
容易发现,一棵子树所有结点的 DFS 序是整棵树的 DFS 序的连续一段。例如,上图中以 d 为根的子树,它的各结点的 DFS 序++3,4,5,6++ 是整棵树的 DFS 序++1,2,3,4,5,6,7,8,9++中的连续一段。可见,借助DFS序,可以快速判断一个结点是否在某子树内。对某子树进行操作,相当于在对应的 DFS 序区间内进行操作。
利用链式前向星存图,求树的 DFS 序的代码如下:
cpp
void dfs_seq(int u,int v) { //dfs sequence
dfs[u]=++id;
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
dfs_seq(j,u);
cnt[u]+=cnt[j];
}
return ;
}● 欧拉序
欧拉序与 DFS 序很像,但也有不同。欧拉序表示从根结点出发,按照 DFS 经过所有结点并返回根结点所得的结点遍历顺序(即返回时也要记录)。
若设 firstu 是欧拉序中某结点 u 第一次出现的位置,lastu 是欧拉序中 u 最后一次出现的位置,则以结点 u 为根的子树包含的结点,是欧拉序区间 first\[u, lastu] 之间的所有结点。换句话说,就是 first\[u, lastu] 之间的结点为 u 的子结点。
欧拉序有两种情况:
(1)DFS 时,第一次访问某结点时记录一次,随后每访问完该结点的一棵子树就再记录一次,一共有 2n-1 个编号。其中,n 是树中结点的个数。

易得上图的欧拉序为:1,2,3,4,3,5,3,6,3,2,7,2,1,8,9,8,1。这是第一种情况下的欧拉序。
针对第一种情况的欧拉序,具有如下性质:即++若设++++firstu++++是欧拉序中某结点 u 第一次出现的位置,++++firstv++++是欧拉序中某结点 v 第一次出现的位置,树上两结点 u, v 的最近公共祖先(LCA),为欧拉序区间++++first\[u, firstv]++++或++++first\[v, firstu]++++中时间戳最小的结点。其中,某结点的时间戳可以理解为第一次 DFS 遍历到该结点的顺序。++ ------→ 再次特别提醒,此性质仅适用于第一种情况下的欧拉序 。
利用链式前向星存图,在第一种情况下,求树的欧拉序的代码如下:
cpp
void ola_seq1(int u,int v) { //ola sequence 1
dfs[++id]=u;
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
ola_seq1(j,u);
dfs[++id]=u;
cnt[u]+=cnt[j];
}
return ;
}(2)DFS 时,每个结点入栈与出栈时分别记录一次,共 2n 个编号。其中,n 是树中结点的个数。
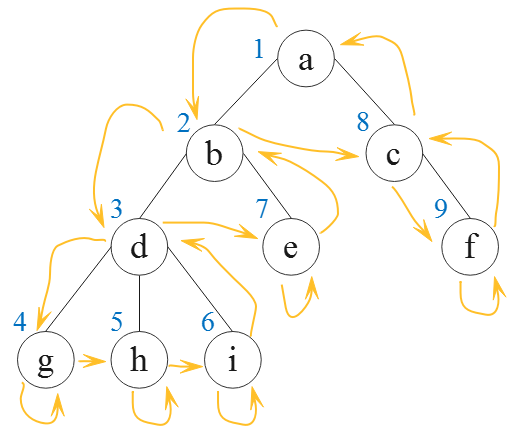
易得上图的欧拉序为:1,2,3,4,4,5,5,6,6,3,7,7,2,8,9,9,8,1。这是第二种情况下的欧拉序。
利用链式前向星存图,在第二种情况下,求树的欧拉序的代码如下:
cpp
void ola_seq2(int u,int v) { //ola sequence 2
dfs[++id]=u;
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
ola_seq2(j,u);
cnt[u]+=cnt[j];
}
dfs[++id]=u;
return;
}● 链式前向星:https://blog.csdn.net/hnjzsyjyj/article/details/139369904
validx:存储编号为 idx 的边的值
eidx:存储编号为 idx 的结点的值
neidx:存储编号为 idx 的结点指向的结点的编号
ha:存储头结点 a 指向的结点的编号
【算法代码】
下面代码的功能为输入 n 个结点,然后输入 n 对整数对 a 和 b 表示 a 和 b 之间有连边。如果 b 是 -1,那么 a 就是树的根。之后,分别按树的 DFS 序及两种欧拉序访问、输出对应的结点值。
由于本题采用链式前向星存树,而链式前向星是典型的头插法构建方法,故输入与输出是逆序的。运行代码后,易见本题的输出与上文的图示相比,明显是逆序的。
cpp
#include <bits/stdc++.h>
using namespace std;
const int N=1e3+5;
const int M=N<<1;
int root;
int dfs[N],cnt[N],id;
int h[N],e[M],ne[M],idx;
int n,m;
void add(int a,int b) {
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void dfs_seq(int u,int v) { //dfs sequence
dfs[u]=++id;
cout<<u<<" ";
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
dfs_seq(j,u);
cnt[u]+=cnt[j];
}
return ;
}
void ola_seq1(int u,int v) { //ola sequence 1
dfs[++id]=u;
cout<<u<<" ";
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
ola_seq1(j,u);
dfs[++id]=u;
cout<<u<<" ";
cnt[u]+=cnt[j];
}
return;
}
void ola_seq2(int u,int v) { //ola sequence 2
dfs[++id]=u;
cout<<u<<" ";
cnt[u]=1;
for(int i=h[u]; ~i; i=ne[i]) {
int j=e[i];
if(j==v) continue;
ola_seq2(j,u);
cnt[u]+=cnt[j];
}
dfs[++id]=u;
cout<<u<<" ";
return;
}
int main() {
cin>>n;
memset(h,-1,sizeof(h));
int a,b;
for(int i=1; i<=n; i++) {
cin>>a>>b;
if(b==-1) root=a;
else add(a,b),add(b,a);
}
id=0,dfs_seq(root,-1),cout<<endl;
id=0,ola_seq1(root,-1),cout<<endl;
id=0,ola_seq2(root,-1),cout<<endl;
return 0;
}
/*
in:
9
1 -1
1 2
1 8
2 3
2 7
3 4
3 5
3 6
8 9
out:
1 8 9 2 7 3 6 5 4
1 8 9 8 1 2 7 2 3 6 3 5 3 4 3 2 1
1 8 9 9 8 2 7 7 3 6 6 5 5 4 4 3 2 1
*/【参考文献】
https://www.cnblogs.com/stxy-ferryman/p/7741970.html
https://www.cnblogs.com/hetailang/p/16209936.html
https://blog.csdn.net/littlegengjie/article/details/134430600
https://blog.csdn.net/zht2002/article/details/128686361