AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
- 基于python的知识图谱技术
- 一文理清python学习路径
- Linux、Git、Docker常用指令
- linux和windows系统下的python环境迁移
- linux下python服务定时(自)启动
- windows下基于python语言的TTS开发
- python opencv实现图像分割
- python使用API实现word文档翻译
- yolo-world:"目标检测届大模型"
- 爬虫进阶:多线程爬虫
- python使用modbustcp协议与PLC进行简单通信
- ChatTTS:开源语音合成项目
- sqlite性能考量及使用(附可视化操作软件)
- 拓扑数据的关键点识别算法
- python脚本将视频抽帧为图像数据集
- 图文RAG组件:360LayoutAnalysis中文论文及研报图像分析
文章目录
简介
最近要做一些图文RAG研究,其中,面向图文交叠的文档难以解析,因此对文档的图文内容进行详细定位就成了关键。
该开源项目基于YOLO8,并结合优质中文研报场景数据,训练出了轻量级符合需求的图文分析模型。
开源地址:
模型权重:
部署等工作可以通过镜像网站完成。
实际使用
其模型文件只有几MB,环境文件依赖搭建过程也很快,基本没有什么问题出现。
测试数据:
测试结果:
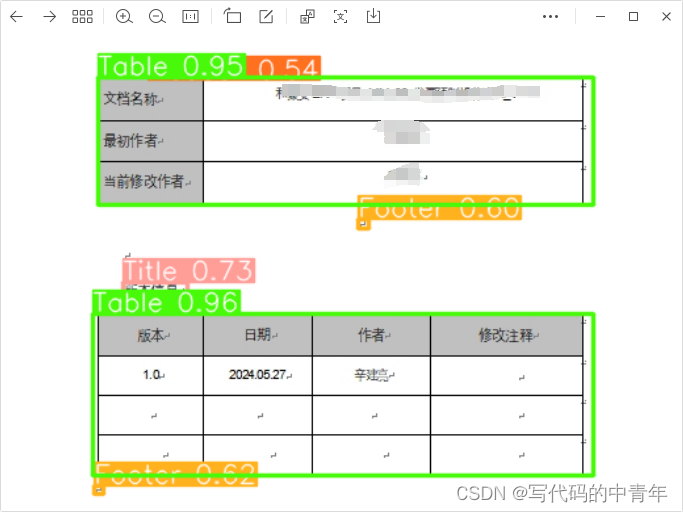
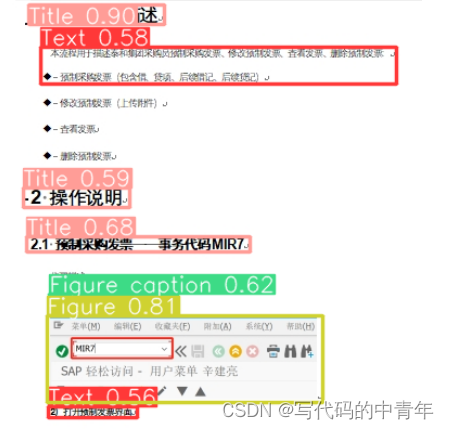
对于研报识别,主要针对9类进行识别:
0: '文本' 1: '标题' 2: '页眉' 3: '页脚' 4: '插图'
5: '表格' 6: '目录' 7: '图注' 8: '表注'
基本上覆盖了一般图文文件中的内容种类,其识别结果后处理难度低,具有较高的实用价值。
代码
python
from ultralytics import YOLO
import cv2
import cv2
def draw_rectangles_with_custom_labels_and_confidences(image_path, regions, labels, confidences):
# 读取原始图像
image = cv2.imread(image_path)
if image is None:
print("Error: Image not found.")
return
# 确保区域、标签和置信度列表长度一致
if len(regions) != len(labels) or len(regions) != len(confidences):
print("Error: The number of regions, labels, and confidences must match.")
return
# 遍历所有区域,标签和置信度
for i, (top_left, bottom_right) in enumerate(regions):
# 绘制矩形框
color = (0, 255, 0) # 绿色框,可以根据需要更改颜色
cv2.rectangle(image, top_left, bottom_right, color, 2)
# 计算文本标签的位置
text = f"{labels[i]} {confidences[i]:.2f}"
text_width, text_height = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
text_x = top_left[0]
text_y = top_left[1] - text_height - 10
# 创建一个背景矩形用于文本
bg_color = (0, 255, 0) # 与框颜色相同,可以根据需要更改颜色
cv2.rectangle(image, (text_x, text_y), (text_x + text_width, text_y + text_height + 10), bg_color, -1)
# 在矩形框上方添加文本标签
cv2.putText(image, text, (text_x, text_y + text_height + 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2)
# 保存图像(可选)
cv2.imwrite('annotated_image'+image_path, image)
model_path = '/home/super/lyq/360LayoutAnalysis/report-8n.pt' # 权重路径
model = YOLO(model_path)
modulue = {0: 'Text', 1: 'Title', 2: 'Header', 3: 'Footer', 4: 'Figure', 5: 'Table', 6: 'Toc', 7: 'Figure caption', 8: 'Table caption'}
image_path = '/home/super/lyq/360LayoutAnalysis/360LayoutAnalysis/case/TEST/4.png' # 待预测图片路径
result = model(image_path, save=True, conf=0.5, save_crop=False, line_width=2)
# 解析result
tlbrxy_ls = [((int(i[0]),int(i[1])),(int(i[2]),int(i[3]))) for i in result[0].boxes.xyxy.cpu().numpy().tolist()]
type_ls = [modulue[i] for i in result[0].boxes.cls.cpu().numpy().tolist()]
confidence_ls = result[0].boxes.conf.cpu().numpy().tolist()
len_result = len(confidence_ls)
for index in range(len_result):
draw_rectangles_with_custom_labels_and_confidences(image_path,tlbrxy_ls,type_ls,confidence_ls)
'''
print(result[0].names) # 输出id2label map
print(result[0].boxes) # 输出所有的检测到的bounding box
print(result[0].boxes.xyxy) # 输出所有的检测到的bounding box的左上和右下坐标
print(result[0].boxes.cls) # 输出所有的检测到的bounding box类别对应的id
print(result[0].boxes.conf) # 输出所有的检测到的bounding box的置信度
'''