国内的大模型应用我选择了国内综合实力最强的两个,一个是腾讯元宝,一个是通义千问。其它的豆包,Kimi,文心一言等在某些领域也有强于竞品的表现。
问一个中文文化比较基础的问题,我满以为中文文化chatGPT不如国内的大模型。可事实相反,以下是测试结果:
提问词都是同一个:姑妈的儿子和我之间怎么互相称呼
下面是ChatGPT-4o:
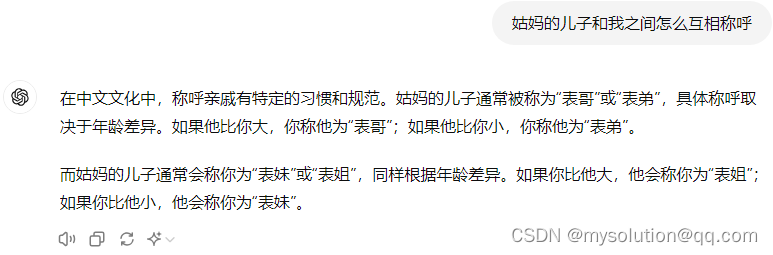
下面是腾讯元宝:
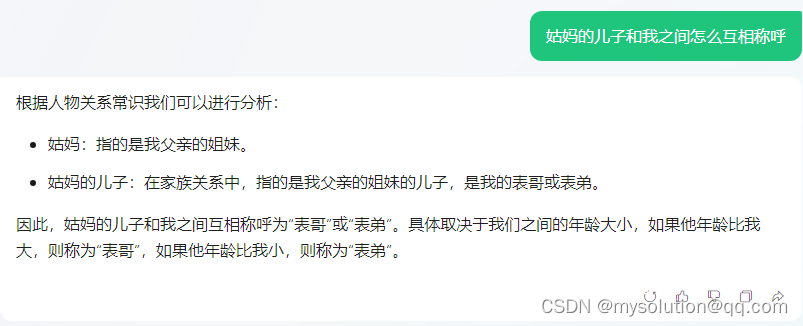
以下是通义千问:

ChatGPT-4o回答更全面,腾讯元宝回答对了一半,没有区分女性这种选项,通义千问回答就是错的,给通义一个纠正的机会,仍然回答错误。
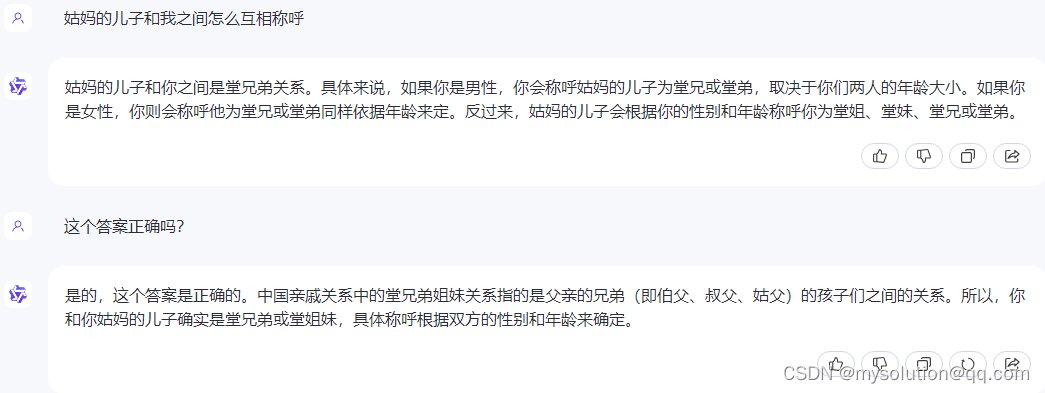
这个测试结果让我太意外了,完全没想到,五味陈杂。