5月,Smartbi从客户需求出发,并结合企业在数据分析、处理等方面遇到的问题,对数据模型、数据指标 等数十项功能进行了优化升级。

Smartbi用户可以在官网下载下载PC端,更新后便可以使用相关功能,也可以在体验中心体验相关功能。
接下来,我们一起来看看5月的重点功能更新!

对V11产品内置Demo进行了内容更新和优化,整合了内置Demo并调整了目录结构。新Demo效果可在体验中心在线查看。具体新增和变更如下:
√新增5个大屏可视化看板
根据当前的UI流行趋势,新增看板中包含了一些酷炫的动态图,还增加了国风主题和商务插画风格的大屏,进一步丰富了内置大屏的风格。▼5个大屏可视化看板

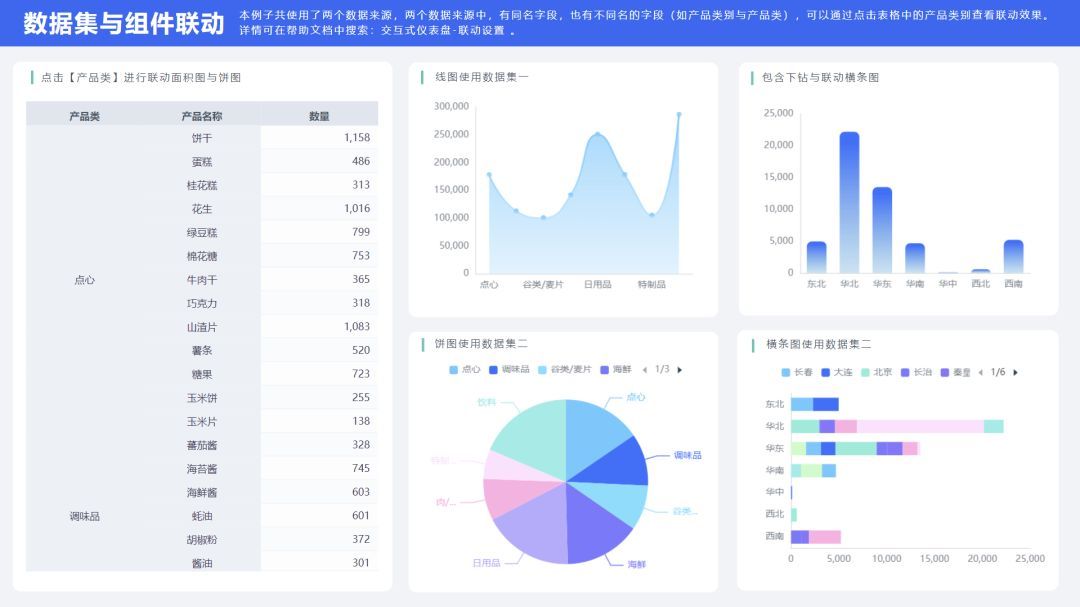
√ 新增6个套件模板实践案例
通过使用酷炫蓝绿和睿智蓝的套件图形,搭建了多个不同风格的案例模板,为用户提供了套件模板的使用参考,降低了用户在图形组件搭配上的难度。
▼6个数据分析看板模版

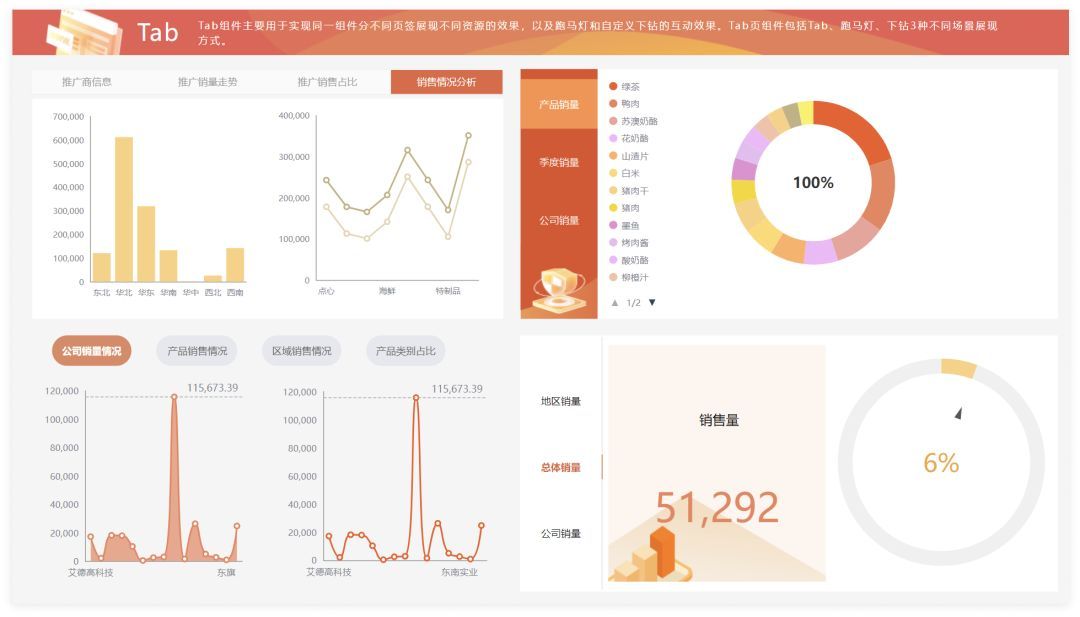
√新增3个移动端看板
此次新增的移动端看板在色彩运用和整体色调上更加新颖,图形展示效果也更加丰富,突显了产品在移动端的图形展示能力和布局能力。
▼上下滚动查看3个移动端看板



√优化原有Demo效果
通过图形合集,更密集、更便捷地展示了仪表盘可视化的图表能力,使用全新即席查询、透视分析功能搭建数据探索Demo。
▼向左滚动查看更多Demo效果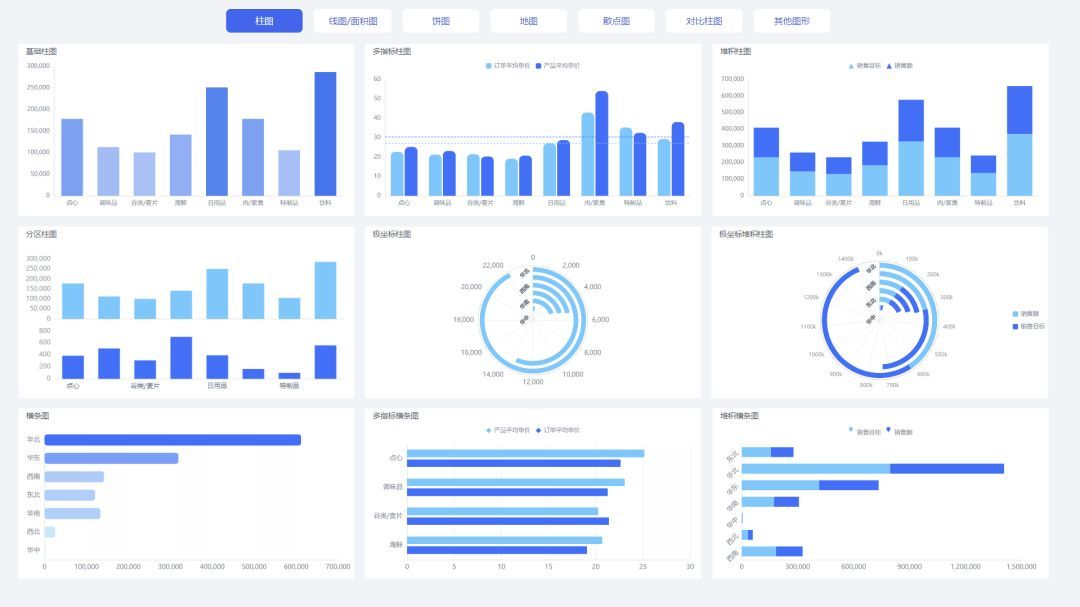


为了提升用户使用体验,提高用户数据分析效率,在新版本中优化了多个功能模块的性能(以下优化数据的测试结果,都是基于产品推荐配置验证):
√优化仪表盘打开渲染性能
当仪表盘上组件较多(超过100个),无数据缓存时页面首次打开性能普遍提升,从原来的平均8.9秒,优化到平均5.9秒,提升30%左右。
√ 优化仪表盘大数据图形刷新性能
支持最大输出行数达50W,且图形数据超过5000行时自动进入大数据做图模式,图形刷新性能提升100%。
▲本次性能优化的图形有:柱图、堆积柱图、横条图、堆积横条图、线图、堆积线图、曲线图、堆积曲线图、阶梯线图、堆积阶梯线图、面积图、堆积面积图、曲线面积图、堆积曲线面积图、散点图。
√ 资源树加载性能优化
-
当资源树节点较多时,部分页面加载较慢,例如在数据模型中选择数据源时,当目录下有4000个子节点时,前端渲染性能从2.2秒提升到0.8秒。
-
当资源树上某个节点下的子节点较多时,管理员展开节点的速度较慢。例如,某个节点下有3500个子节点时,展开节点的性能从3.22秒提升到1.4秒。
-
当资源树上某个节点下的子节点较多且需要判断用户资源权限时,展开节点的速度也会较慢。例如,某个节点下有3500个子节点,涉及1万个不同角色的资源权限判断时,某个角色用户展开该节点查看自己可访问的子节点时,性能从2.87秒提升到1秒内。
√ 资源树搜索性能优化
-
当资源树节点较多时,输入关键字搜索的性能较慢。例如,在分析展现资源树上有127,000个节点时,管理员输入关键字搜索的性能提升显著,从超过1小时无法返回结果提升到仅需3.4秒即可返回结果。
-
在资源树节点较多且需要判断用户资源权限的情况下,输入关键字搜索的性能也较慢。例如,在资源树上有120,000个节点的即席查询界面中,普通用户输入关键字搜索字段的性能从超过1小时无法返回结果提升到仅需4秒即可返回结果。

对于系统安全要求较高的项目,可以采用前后端分离部署的方式。在这种部署方式下,产品在部署时将内外网、前后端彻底分离:前端服务器仅提供静态资源访问,而后端服务器负责处理所有动态请求。
此外,系统还支持客户端访问的白名单机制,并能够对前后端的请求和响应进行加密和解密,进一步提升安全性。

√ 支持全面开启"SQL引擎"
为提升查询效能,系统全面整合了"SQL引擎",无需任何手动配置即可直接使用,使数据查询更加高效和便捷。"SQL引擎"自动应用于所有基于数据模型的展示层,具体场景如下:
-
即席查询和仪表盘的明细表,默认采用SQL引擎。
-
透视分析和仪表盘其他数据组件,在未使用多维引擎进行计算(如计算度量、计算成员、计算命名集)时,默认使用SQL引擎。
在产品推荐配置下,我们对比了"SQL引擎"与"多维引擎"的性能,在相同数据库、基于2个维度、2个度量加过滤和排序的场景下进行非缓存数据查询:
-
1000万行数据,"多维引擎"无法查询出结果,而"SQL引擎"能正常查询出数据。
-
100万行数据,"多维引擎"平均需要61秒,而"SQL引擎"平均只需9秒。
👉更多详解请点击了解更多:SQL引擎介绍( https://wiki.smartbi.com.cn/pages/viewpage.action?smt_poid=43\&pageId=113542956**)**
√ 数据模型的度量区支持创建多级目录
为了方便用户一目了然地查看和编辑指标,产品最初只支持一级目录。然而,面对日益复杂的数据管理挑战,尤其是在处理拥有庞大指标体系(如包含500多个字段的大宽表)的项目时,为了更好地按照业务逻辑分层或根据分析需求进行分类,新版本中度量功能现已支持创建多级目录。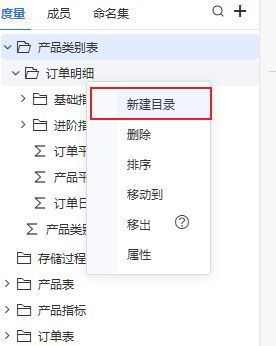

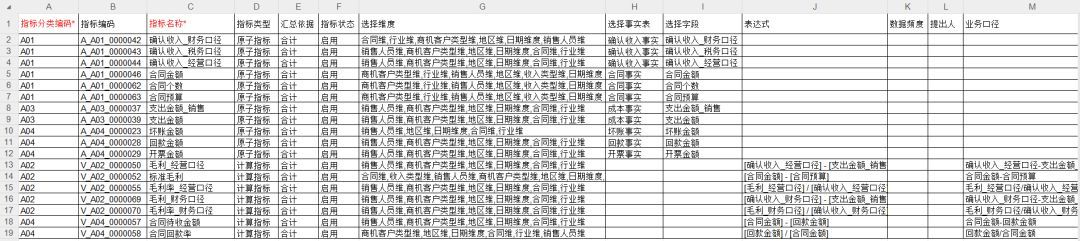
√ 指标管理支持导出计算指标
作为一种重要的数据资产,指标体系在项目中有时需要导出为指标清单文档。这个文档不仅可以用作存档资料,还能帮助熟悉Excel工具的用户更方便地筛选、查找和标记指标。在旧版本中,系统只能导出原子指标。为确保指标清单的完整性,新版本新增了对计算指标导出的支持。 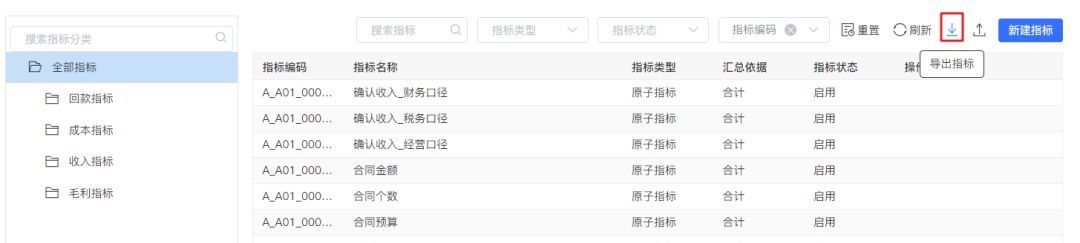

√ ETL目标表支持人大金仓数据库KingbaseES
人大金仓KingbaseES是国产通用数据库,是信创产业的优秀产品。在旧版本中,ETL仅支持从KingbaseES读取数据,无法写入。新版本中,ETL已经支持将KingbaseES作为目标表,满足更多数据写入的需求。
√ ETL自动生成分区条件,加快抽取速度
ETL默认采用单线程进行数据抽取,但通过设置分区,可以实现多线程抽取,从而显著提高抽取速度。例如,在Oracle数据库中,1亿条数据单线程需要20分钟,而使用8线程仅需4分11秒,速度提升了4.8倍。然而,在旧版本中,需要用户手动设置分区条件,对用户技能要求较高。新版本提供了图形化的分析结果 和一键生成分区条件 的入口,大大提高了用户生成分区条件的便捷性和易用性。 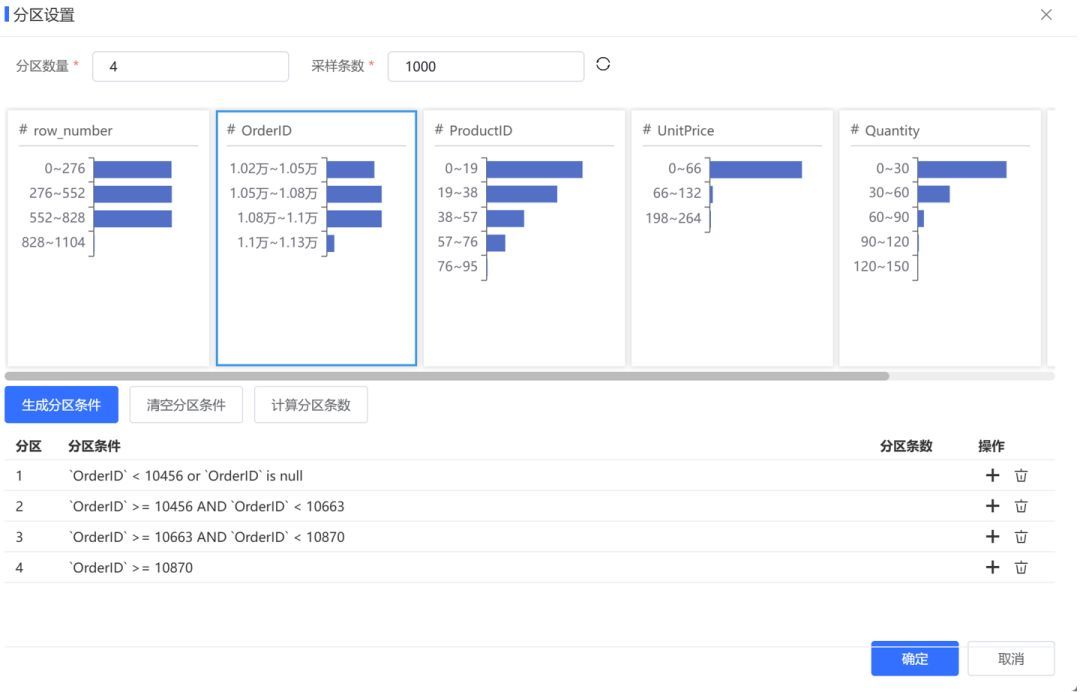

√ 增加"进入即席查询模式"入口
为了让用户在查看看板数据时,更灵活地分析某个组件的明细数据,新版本在仪表盘的组件菜单中新增了**"进入即席查询模式"** 入口。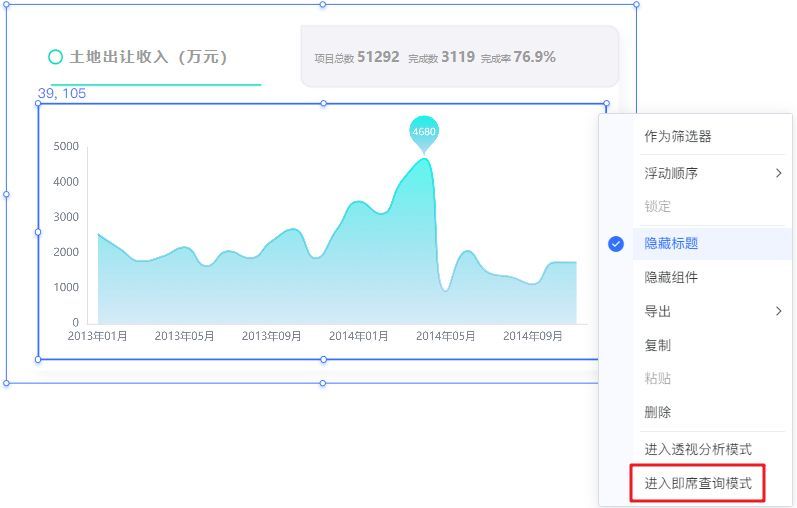
√ 自定义字段支持查看来源字段
在业务用户使用报表分析数据时,如果现有的数据模型字段无法满足业务需求,可以在报表层中创建自定义字段,例如分组字段或维度转度量字段。然而,由于这些自定义字段保存在自定义维度/度量目录下,用户可能在一段时间后不记得这些字段的来源。在新版本中,针对报表层创建的分组字段、转换度量等自定义字段,字段属性中增加了查看其来源字段的功能。 
√ 联动筛选器刷新逻辑优化
当报表数据量较大且包含多个筛选器时,用户通常希望报表在打开时默认不刷新,待选择完所有筛选条件后再手动刷新整个报表。为确保用户能顺利选择所需的所有筛选条件,新版本优化了联动筛选器的刷新逻辑。当设置"切换参数时是否刷新"为"不刷新"时,被联动的筛选器能根据影响它的筛选条件的变化更新备选值。

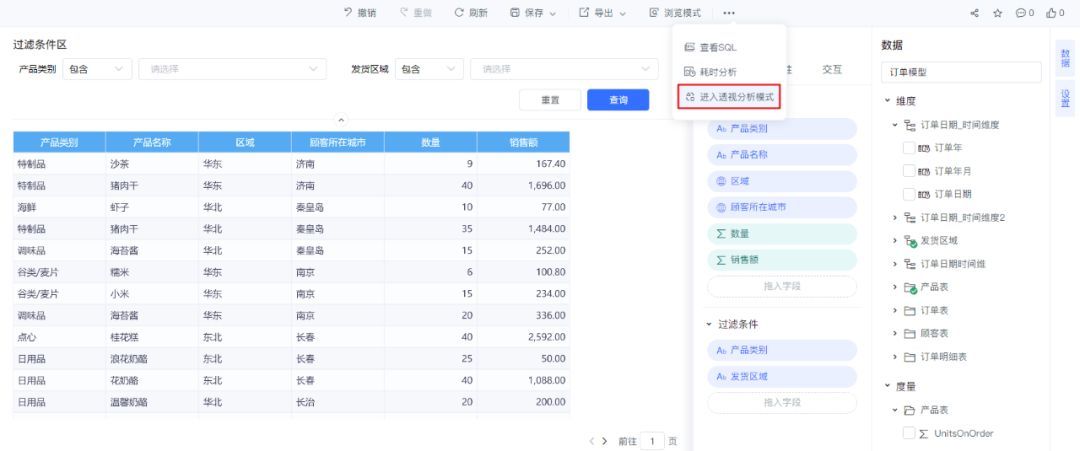
√ 即席查询与透视分析报表支持互相转换
在用户使用即席查询分析明细数据时,如果想进一步分析汇总数据,通常需要新建一个透视分析,并重新选择所有字段和条件,这样的过程非常繁琐。
为了简化操作,新版本允许即席查询直接转换为透视分析,同理,即席查询和透视分析的互相转换功能,帮助业务人员轻松实现数据查询和探索。

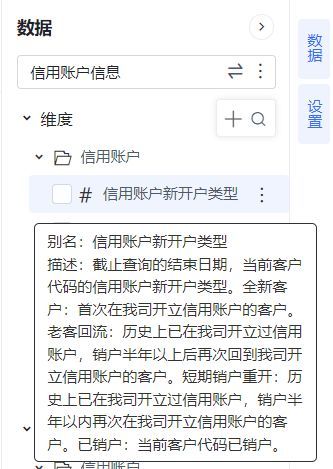
√ 资源的"描述"长度扩大到"2000字节"
为了精确描述某个指标的业务含义,有时需要详细的文字说明。为便于在数据分析时完整查看复杂指标的业务含义,新版本将资源的"描述"长度扩展至2000字节,能够存储更多信息。

产品的二次扩展接口旨在为用户和开发者提供更广泛的定制化和扩展可能性,以实现个性化的功能优化和扩展。在新版本中,我们在数据模型、流程引擎和电子表格模块中优化或新增了一系列扩展接口,以满足用户更多的个性化需求。
👉更多详解请点击了解更多:https://wiki.smartbi.com.cn/pages/viewpage.action?smt_poid=43\&pageId=114996719
以上就是Smartbi 5月的产品更新介绍啦,期待通过持续的产品更新、升级,帮助客户伙伴实现高效、轻松做好数据赋能业务决策。对于本次更新,您有什么建议吗?欢迎留言反馈。麦粉们也可以在社区的建议征集处发表意见。我们将持续优化迭代,带给大家更好的产品体验~点击下方按钮,抢先体验新功能哦!