概要介绍

对于逻辑回归我们可以从一个问题入手,到底什么是逻辑回归的算法思想?
面试官问"请描述逻辑回归的算法思想"这个问题时,其实是在考察你对这个基础模型的
本质理解------是只会调用sklearn.learn.LogisticRegression,还是真正明白它为什么叫"回归"却做分类,它的核心在算什么。"逻辑回归虽然名字里有'回归',但它实际上是一种用于解决二分类问题的线性模型。它的核心思想是:先拟合决策边界(线性回归的活儿),再把线性输出映射到0到1之间的概率(Sigmoid函数的活儿),最后根据概率进行分类。"


所以,逻辑回归的核心思想可以概括为:线性回归 + Sigmoid转换 + 最大似然估计。它简单、可解释性强、训练快,是很多复杂模型(如神经网络、推荐系统)的基础组件。
逻辑回归模型介绍: 概述: 属于有监督学习, 即: 有特征, 有标签, 且标签是离散的. 主要适用于: 二分类,是分类算法的一种. 原理: 把线性回归处理后的预测值 -> 通过 Sigmoid激活函数, 映射到[0, 1] 概率 -> 基于自定义的阈值, 结合概率来 分类. 1. 基于线性回归, 结合特征值, 计算出标签值. 2. 把上述算出来的标签值传给 激活函数(Sigmoid), 映射成 [0, 1]区间的值. 3. 结合手动设置的阈值, 来划分区间即可. 例如: 阈值 = 0.6, 则: 结果 > 0.6 A类 否则 B类 损失函数: 极大似然估计函数的 负数形式,先基于 极大似然函数计算, 然后转成 对数似然函数, 结合梯度下降, 计算最小值即可. 总结: 1. 逻辑回归原理: 把线性回归的输出, 作为逻辑回归的输入. 2. 默认情况下: 采用样本少的当做正例, 其它是反例(也叫: 假例) 3. (逻辑回归)损失函数的设计原则: 真实例子是正例的情况下, 概率值越大越好. 理解分类评估方法并进行详细的描述: 准确率:所有样本中预测正确的样本比例(包括正例和反例) 精确率:预测为正例样本中真正例样本的比例,查准率 召回率:真实为正例的样本中,预测为正例样本的比例,查全率 f1-score:精确率和召回率的组合 ROC曲线和AUC指标: ROC是以FPR(FP/ALL_反例)和TPR(TP/ALL_正例)绘制的模型评估曲线 AUC是ROC曲线下面积,取值在0-1之间,一般是大于0.5的, 表示模型的评估能力如何,越接近1越优秀. 机器学习项目流程 1. 准备数据. 2. 数据的预处理. 3. 特征工程. 特征提取, 特征预处理, 特征降维, 特征选取, 特征组合 4. 模型训练. 5. 模型预测. 6. 模型评估.
入门案例
python
"""
案例:
癌症预测案例, 目的: 演示逻辑回归相关API.
逻辑回归:
概述:
它属于分类算法的一种, 一般用于: 二分法.
原理:
1. 基于线性回归, 结合特征值, 计算出标签值.
2. 把上述算出来的标签值传给 激活函数(Sigmoid), 映射成 [0, 1]区间的值.
3. 结合手动设置的阈值, 来划分区间即可.
例如: 阈值 = 0.6, 则:
结果 > 0.6 A类
否则 B类
损失函数:
先基于 极大似然函数计算, 然后转成 对数似然函数, 结合梯度下降, 计算最小值即可.
总结:
1. 逻辑回归原理: 把线性回归的输出, 作为逻辑回归的输入.
2. 默认情况下: 采用样本少的当做正例, 其它是反例(也叫: 假例)
3. (逻辑回归)损失函数的设计原则: 真实例子是正例的情况下, 概率值越大越好.
回顾: 机器学习的开发流程
1. 准备数据.
2. 数据的预处理.
3. 特征工程.
特征提取, 特征预处理, 特征降维, 特征选取, 特征组合
4. 模型训练.
5. 模型预测.
6. 模型评估.
"""
# 导包
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 准备数据.
data = pd.read_csv('./data/breast-cancer-wisconsin.csv')
data.info() # 699行 * 11列, 看不到空值, 因为有?标记.
# 2. 数据的预处理.
# 2.1 用 np.NaN来替换?
data = data.replace('?', np.nan)
data.info()
# 2.2 因为有缺失值, 但是缺失值不多, 我们删除即可. 按行删除.
data.dropna(axis=0, inplace=True) # axis=0(默认), 按行删.
data.info()
# 3. 特征工程, 特征提取, 特征预处理, 特征降维, 特征选取, 特征组合
# 3.1 获取特征值 和 目标值(标签值).
x = data.iloc[:, 1:-1] # 从索引为1的列开始获取, 直至 最后一列(不包括).
# y = data.iloc[:, -1]
# y = data['Class']
y = data.Class
# 3.2 查看结果.
print(len(x), len(y))
print(x.head(10))
print(y.head(10))
# 3.3 拆分训练集 和 测试集.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 3.4 数据集相差不大, 可以不做 标准化处理, 但是为了让步骤更完整, 我们还是做一下.
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建模型, 逻辑回归模型.
estimator = LogisticRegression()
# 4.2 训练模型.
estimator.fit(x_train, y_train)
# 5. 模型预测.
y_predict = estimator.predict(x_test)
print(f'预测值: {y_predict}')
# 6. 模型评估.
print(f'准确率: {estimator.score(x_test, y_test)}') # 0.9854014598540146
print(f'准确率: {accuracy_score(y_test, y_predict)}') # 0.9854014598540146
# 至此, 逻辑回归的入门API代码我们就写完了, 但是我们这里做的是癌症预测, 思考: 仅仅靠正确率, 能衡量逻辑回归结果吗?
# 肯定是不可以的, 因为只知道正确率, 不知道到底哪些是预测成功了, 哪些是预测失败了, 所以为了进一步的评估, 我们需要加入:
# 混淆矩阵, 精确率(掌握), 召回率(掌握), F1值(F1-score)(掌握), ROC曲线(了解), AUC值(了解).混淆矩阵-精确率-召回率
python
"""
案例:
演示混淆矩阵 和 精确率, 召回率, F1值.
回顾: 逻辑回归
概述:
属于有监督学习, 即: 有特征, 有标签, 且标签是离散的.
适用于 二分类.
评估:
精确率, 召回率, F1值
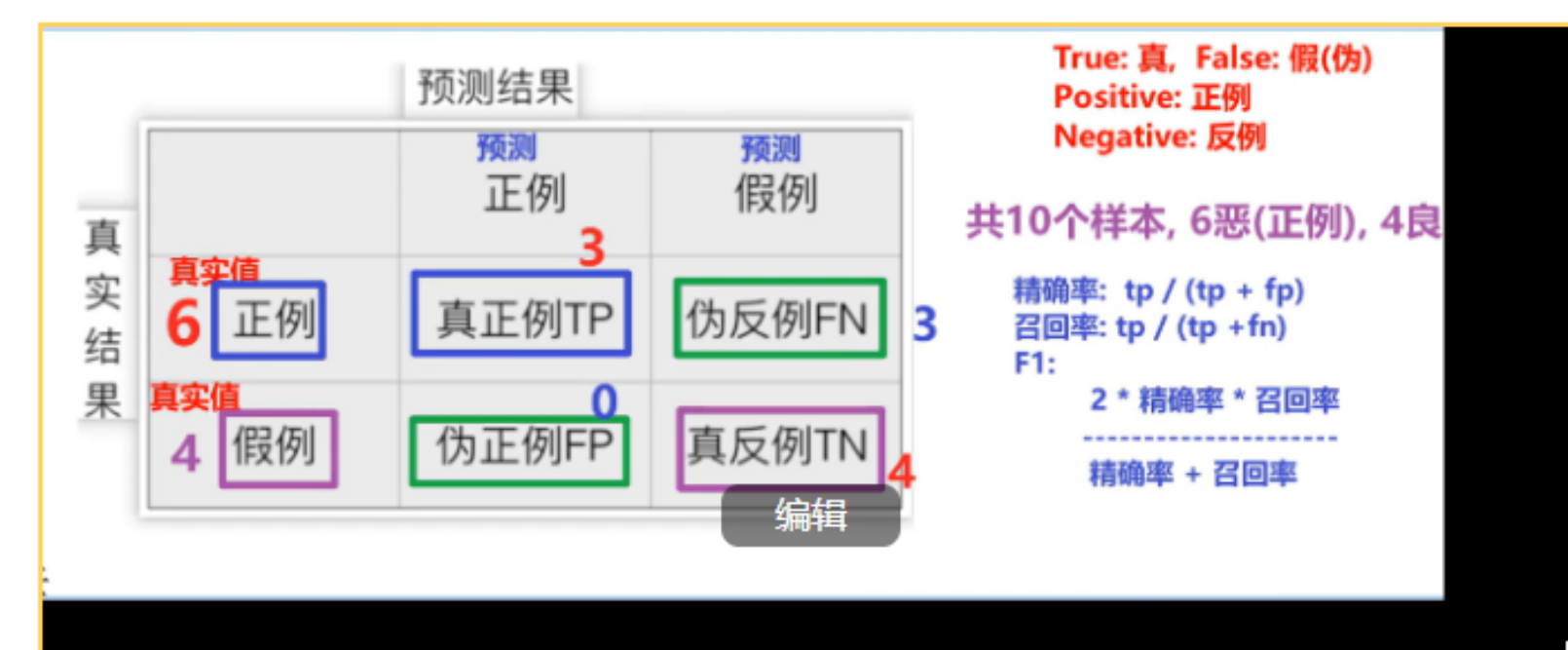
混淆矩阵:
概述:
用来描述 真实值 和 预测值之间关系的.
图解:
预测标签(正例) 预测标签(反例)
真实标签(正例) 真正例(TP) 伪反例(FN)
真实标签(反例) 伪正例(FP) 真反例(TN)
单词:
True: 真, False: 假(伪)
Positive: 正例
Negative: 反例
结论:
1. 模拟使用 分类少的 充当 正例.
2. 精确率 = 真正例 在 预测正例中的占比, 即: tp / (tp + fp)
3. 召回率 = 真正例 在 真正例中的占比, 即: tp / (tp + fn)
4. F1值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
逻辑回归 评估方式:
准确率:
预测正确的 / 样本总数, 即: (tp + tn) / 样本总数
精确率(查准率, Precision):
真正例 / (真正例 + 伪正例), 即: tp / (tp + fp)
大白话: 真正例 在 预测为正例的结果中的 占比.
召回率(查全率, Recall):
真正例 / (真正例 + 伪反例), 即: tp / (tp + fn)
大白话: 真正例 在 真实正例样本中的 占比.
F1值(F1-Score):
2 * 精确率 * 召回率 / (精确率 + 召回率)
适用于: 既要考虑精确率, 还要考虑召回率的情况.
"""
# 导包
import pandas as pd
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score # 混淆矩阵, 精确率, 召回率, F1值
# 需求: 已知有10个样本, 6个恶性肿瘤(正例), 4个良性肿瘤(反例).
# 模型A预测结果为: 预测对了3个恶性肿瘤, 预测对了4个良性肿瘤
# 模型B预测结果为: 预测对了6个恶性肿瘤, 预测对了1个良性肿瘤
# 请针对于上述的数据集, 搭建 混淆矩阵, 并分别计算模型A, 模型B的 精确率, 召回率, F1值.
# 1. 定义变量, 记录: 样本数据
y_train = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
# 2. 定义变量, 记录: 模型A的预测结果
y_pred_A = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
# 3. 定义变量, 记录: 模型B的预测结果
y_pred_B = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '恶性', '恶性', '恶性']
# 4. 用标签标记 正例, 反例.
label = ['恶性', '良性'] # 标签
df_label = ['恶性(正例)', '良性(反例)']
# 5. 针对于 真实值(y_train) 和 模型A的预测结果(y_pred_A), 搭建 混淆矩阵.
cm_A = confusion_matrix(y_train, y_pred_A, labels=label) # 参数1: 真实值, 参数2: 预测值, 参数3: 标签, 默认: 默认, 会用 分类少的 样本当做 正例.
print(f'混淆矩阵A: \n {cm_A}')
# 6. 为了测试结果更好看, 把上述的 混淆矩阵 转换成 DataFrame.
df_A = pd.DataFrame(cm_A, index=df_label, columns=df_label)
print(f'混淆矩阵A的 DataFrame对象形式: \n {df_A}')
# 7. 针对于 真实值(y_train) 和 模型B的预测结果(y_pred_B), 搭建 混淆矩阵.
cm_B = confusion_matrix(y_train, y_pred_B, labels=label)
print(f'混淆矩阵B: \n {cm_B}')
# 8. 为了测试结果更好看, 把上述的 混淆矩阵 转换成 DataFrame.
df_B = pd.DataFrame(cm_B, index=df_label, columns=df_label)
print(f'混淆矩阵B的 DataFrame对象形式: \n {df_B}')
# 9. 计算A模型的 精确率, 召回率, F1值.
print(f'模型A 精确率: {precision_score(y_train, y_pred_A, pos_label='恶性')}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签
print(f'模型A 召回率: {recall_score(y_train, y_pred_A, pos_label="恶性")}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签
print(f'模型A F1值: {f1_score(y_train, y_pred_A, pos_label="恶性")}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签
# 10. 计算B模型的 精确率, 召回率, F1值.
print(f'模型B 精确率: {precision_score(y_train, y_pred_B, pos_label='恶性')}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签
print(f'模型B 召回率: {recall_score(y_train, y_pred_B, pos_label="恶性")}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签
print(f'模型B F1值: {f1_score(y_train, y_pred_B, pos_label="恶性")}') # 参1: 真实值, 参2: 预测值, 参3: 正例的标签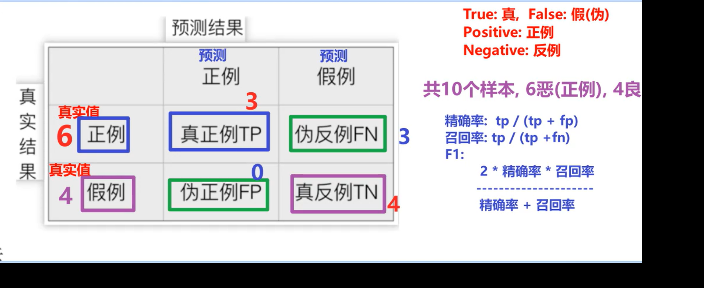
ROC曲线的绘制
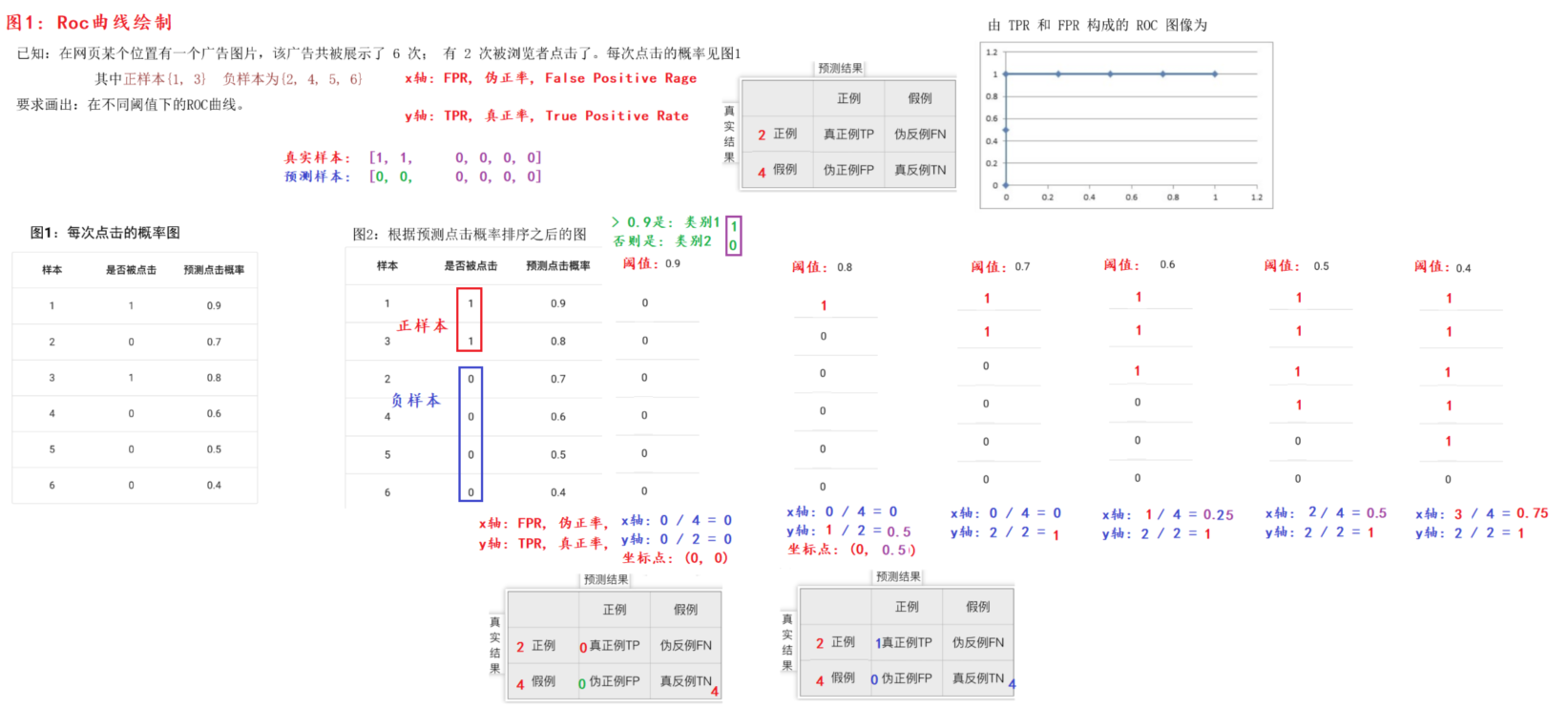
FPR伪正率:伪正例FP 在 全部假例 的占比
TPR真正率:真正例TP 在 全部正例 的占比
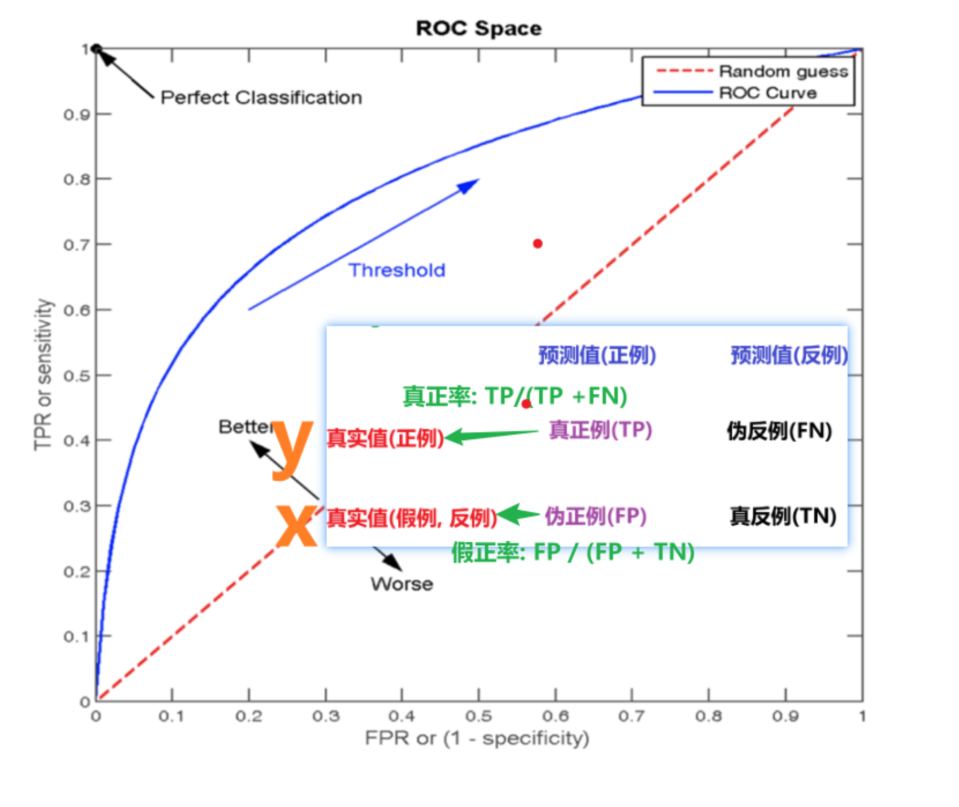
客户流失案例分析
python
"""
案例:
电信客户流失分析.
目的:
1. 演示逻辑回归的相关操作, 主要是: 二分法(流失, 不流失)
2. 演示逻辑回归的评估操作, 主要是: 混淆矩阵, 准确率, 召回率, F1值, ROC曲线, AUC值, 分类评估报告(了解)
"""
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
# 准确率 精确率 召回率 F1值 roc曲线 分类评估报告
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, classification_report
from sklearn.model_selection import train_test_split
# 1. 定义函数, 用于实现: 数据预处理.
def dm01_数据预处理():
# 1. 读取数据.
data = pd.read_csv('./data/churn.csv')
data.info()
# 2. 因为上述的Churn, gender是字符串类型, 我们对其做热编码(one-hot)处理.
data = pd.get_dummies(data)
data.info()
print(data.head(10))
# 3. 删除列, 因为热编码之后, 会多出一个列, 我们删除掉.
data.drop(['gender_Male', 'Churn_No'], axis=1, inplace=True)
print(data.head(10))
# 4. 修改列名.
data.rename(columns={'Churn_Yes':'flag'}, inplace=True)
print(data.head(10))
# 5. 我们查看下数据集中, 标签 是否是 均衡的.
print(data.flag.value_counts()) # False -> 不流失, True -> 流失
# 2. 定义函数, 用于显示: 月度会员的流失情况.
def dm02_会员流失可视化情况():
# 1. 读取数据.
data = pd.read_csv('./data/churn.csv')
# 2. 对上述的数据做 热编码处理.
data = pd.get_dummies(data)
# 3. 删除列, 因为热编码之后, 会多出一个列, 我们删除掉.
data.drop(['gender_Male', 'Churn_No'], axis=1, inplace=True)
# 4. 修改列名.
data.rename(columns={'Churn_Yes':'flag'}, inplace=True)
# 5. 查看数据集的分布情况.
print(data.flag.value_counts())
print(data.columns) # 查看所有列名.
# 6. 通过计数柱状图, 绘制(月度)会员的流失情况.
# 参数x意思是: x轴的列名(是否是月度会员, 0 -> 不是会员, 1 -> 是会员)
# 参数hue意思是: 根据hue的值, 将数据进行分类(False -> 不流失, True -> 流失)
sns.countplot(data, x='Contract_Month', hue='flag')
plt.show()
# 3. 定义函数, 用于实现: 逻辑回归模型的训练和评估.
def dm03_逻辑回归模型训练评估():
# 1. 读取数据.
data = pd.read_csv('./data/churn.csv')
# 2. 对上述的数据做 热编码处理.
data = pd.get_dummies(data)
# 3. 删除列, 因为热编码之后, 会多出一个列, 我们删除掉.
data.drop(['gender_Male', 'Churn_No'], axis=1, inplace=True)
# 4. 修改列名.
data.rename(columns={'Churn_Yes':'flag'}, inplace=True)
# 5. 查看数据集, 从中筛除: 特征列 和 标签列.
# print(data.head(10)) # 特征列: Contract_Month, PaymentElectronic, internet_other
# print(data.columns) # 标签列: flag
# 6. 拆分训练集和测试集.
x = data[['Contract_Month', 'PaymentElectronic', 'internet_other']]
y = data['flag']
# print(len(x), len(y))
# print(x.head(10))
# print(y.head(10))
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 7. 创建逻辑回归模型, 并训练.
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 8. 模型预测.
y_predict = estimator.predict(x_test)
print(f'预测值为: {y_predict}')
# 9. 模型评估.
# 9.1 准确率.
print(f'准确率: {estimator.score(x_test, y_test)}')
print(f'准确率: {accuracy_score(y_test, y_predict)}') # 真实值, 预测值.
print('-' * 22)
# 9.2 精确率.
print(f'精确率: {precision_score(y_test, y_predict)}')
print('-' * 22)
# 9.3 召回率.
print(f'召回率: {recall_score(y_test, y_predict)}')
print('-' * 22)
# 9.4 F1值
print(f'F1值: {f1_score(y_test, y_predict)}')
print('-' * 22)
# 9.5 roc曲线
print(f'roc曲线: {roc_auc_score(y_test, y_predict)}')
print('-' * 22)
# 9.6 分类评估报告
# 参数macro avg意思是: 宏平均, 是指: 所有的分类器, 都按照 macro 的方式, 计算平均值/
# 不考虑样本的权重, 直接平均, 跟样本的数量, 权重无关, 所有特征权重都一样, 适合于 数据集比较平衡的情况.
# 参数weighted avg意思是: 权重平均, 是指: 所有的分类器, 都按照 weighted 的方式, 计算平均值/
# 考虑样本的权重, 根据样本的权重, 计算平均值, 适合于 数据集比较不平衡的情况.
print(f'分类评估报告: {classification_report(y_test, y_predict)}')
# 4. 在main函数中测试.
if __name__ == '__main__':
# dm01_数据预处理()
# dm02_会员流失可视化情况()
dm03_逻辑回归模型训练评估()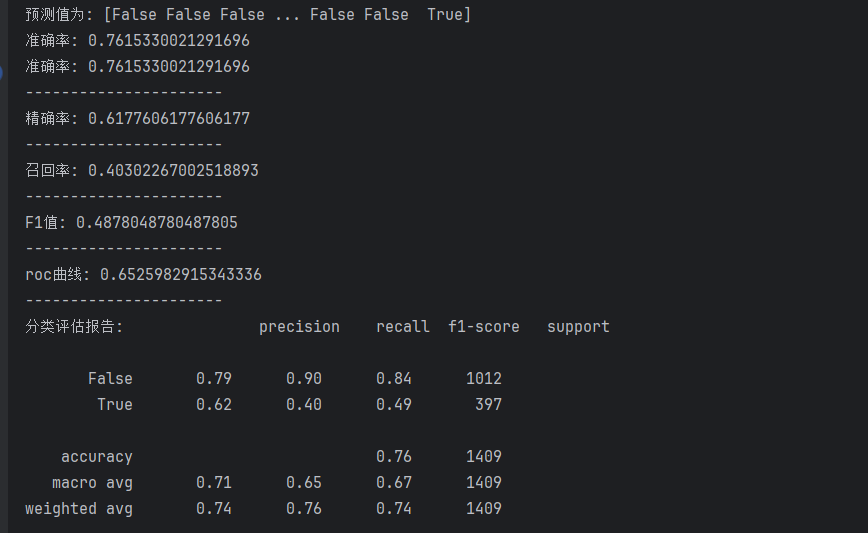
一、分类评估报告参数详解
首先,我们来逐一解读报告中每一列和每一行的含义。
1. 行(类别)
报告展示了两行,对应模型的输出类别。在这个客户流失案例中:
-
False(0) :代表负类 ,即不流失的客户。 -
True(1) :代表正类 ,即流失的客户。
2. 列(评估指标)
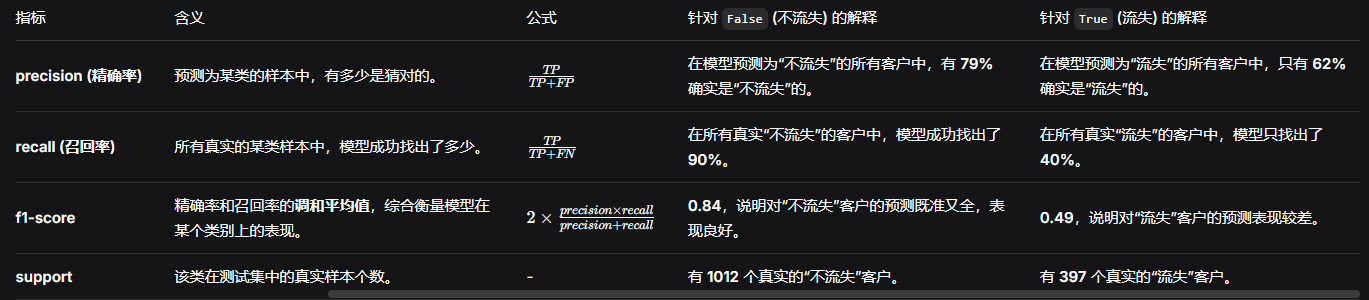
如果有疑惑可以参考着下图来解析评估指标
二、底层三行汇总指标解读
报告底部还有三行,提供了不同维度的总体评价:
1. accuracy (准确率)
-
数值 :0.76
-
含义:所有测试样本中,预测正确的比例。
-
解读 :整体来看,模型在 76% 的情况下能正确判断客户是否流失。但要注意,这个指标在样本不平衡时容易被多数类(不流失)带偏。
2. macro avg (宏平均)
-
数值:precision 0.71, recall 0.65, f1-score 0.67
-
含义 :分别计算每个类别的指标,然后直接取算术平均,不考虑样本多少。
-
解读 :宏平均把"流失"和"不流失"两个类别看得同等重要。0.65 的召回率说明,模型平均来看,找出每个类别(特别是流失客户)的能力较弱。这个指标更能反映模型在**少数类(流失)**上的糟糕表现。
3. weighted avg (加权平均)
-
数值:precision 0.74, recall 0.76, f1-score 0.74
-
含义 :分别计算每个类别的指标,然后按该类样本数加权平均。
-
解读 :由于"不流失"的样本(1012个)远多于"流失"的样本(397个),加权平均的结果更偏向于"不流失"类的指标,因此看起来比宏平均更好看。但在业务中,如果更关注流失客户,这个指标会掩盖真正的问题。
三、结合代码和业务场景的分析
1. 业务背景
这是一个客户流失预测 模型。目标是提前发现可能流失的客户(True),以便运营商采取措施(如发送优惠券)进行挽留。
2. 模型表现分析
从业务角度看,我们最关心的是召回率 (Recall) ,因为漏掉一个真正要流失的客户(FN),就意味着直接损失了一个客户。相比之下,把没想流失的客户误判为流失(FP),最多只是多发一张优惠券的成本。
-
模型短板 :模型的召回率(流失类)只有 0.40 。这意味着在所有真实流失的客户中,模型只成功预测出了 40% ,而漏掉了剩下的 60%。这个模型在实际业务中帮助不大,因为大部分想走的客户它都没发现。
-
样本不平衡 :从
support列(1012 vs 397)可以清晰看到,测试集中"不流失"的样本远多于"流失"的样本。模型为了整体准确率,会更倾向于学习"不流失"的特征,导致对"流失"的判断能力弱。
3. 代码逻辑印证
-
特征选择 :代码中只用了三个特征:
['Contract_Month', 'PaymentElectronic', 'internet_other']。这可能过于简化,遗漏了如"用户月消费金额"、"客服通话次数"等重要特征,导致模型学习能力有限。 -
模型选择 :使用了默认参数的
LogisticRegression,没有针对样本不平衡问题进行调整(如设置class_weight='balanced')。
四、总结与优化建议
一句话总结报告 :这个逻辑回归模型对不流失 的客户预测得很好(召回率 90%),但对业务真正关心的流失客户预测能力很差(召回率 40%),模型可用性较低。
如果要向面试官或领导汇报,可以这样说:
"从分类评估报告看,模型整体准确率有 76%,但这个指标被多数类(不流失)拉高了。真正的业务短板在于对流失客户的召回率只有 40%,这意味着 60% 即将流失的客户没有被识别出来。主要原因是样本不平衡,且目前使用的特征较少。下一步需要针对这些问题进行优化。"我觉得分析的很到位!!!
后续优化方向:
-
增加特征:引入更多与流失相关的特征,如消费金额、使用时长、投诉次数等。
-
处理样本不平衡:
-
调整模型权重 :在
LogisticRegression中设置class_weight='balanced'。 -
重采样:对少数类(流失)进行过采样(如SMOTE),或对多数类进行欠采样。
-
-
调整分类阈值:模型默认用 0.5 作为判断流失/不流失的阈值。为了提高召回率,可以适当降低阈值(如 0.3),让模型对流失更敏感(但这会增加误报,需要权衡)。
以上就是该分类评估报告的整体情况汇总了!!!