打开深交所公募REITs公开说明书页面,F12查看网络,找到真实地址:https://reits.szse.cn/api/disc/announcement/annList?random=0.3555675437003616

{
"announceCount": 39,
"data": [
{
"id": "80bc99a7-8a04-4803-b42a-d9cca1e6c5d5",
"annId": 1220300147,
"title": "华夏华润商业REIT:华夏华润商业资产封闭式基础设施证券投资基金招募说明书更新",
"content": null,
"publishTime": "2024-06-08 00:00:00",
"attachPath": "/disc/disk03/finalpage/2024-06-08/a77d6a34-c4eb-4dcf-9b16-7c2ce856ebdd.PDF",
"attachFormat": "PDF",
"attachSize": 6265,
"secCode": [
"180601"
],
"secName": [
"华夏华润商业REIT"
],
"bondType": null,
"bigIndustryCode": null,
"bigCategoryId": null,
"smallCategoryId": null,
"channelCode": null,
"_index": "ows_disclosure-20180825"
},
返回的是json数据,PDF地址在这里:"/disc/disk03/finalpage/2024-06-08/a77d6a34-c4eb-4dcf-9b16-7c2ce856ebdd.PDF",
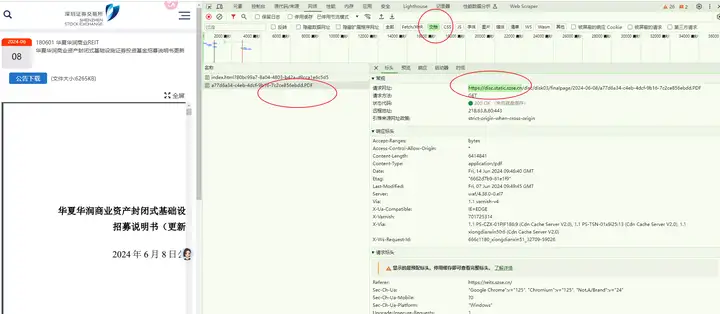
打开下载页面,查看网站URL:https://disc.static.szse.cn/disc/disk03/finalpage/2024-06-08/a77d6a34-c4eb-4dcf-9b16-7c2ce856ebdd.PDF
那么,开头要添加的是"https://disc.static.szse.cn"
在deepseek中输入提示词:
你是一个Python编程专家,写一个Python脚本,具体步骤如下:
请求网址:
https://reits.szse.cn/api/disc/announcement/annList?random=0.3555675437003616
请求方法:
POST
状态代码:
200 OK
远程地址:
58.251.50.138:443
引荐来源网址政策:
strict-origin-when-cross-origin
请求载荷:
{"seDate":"","","channelCode":"reits-xxpl","bigCategoryId":"directions","pageSize":50,"pageNum":1}
请求标头:
Accept:
application/json, text/javascript, */*; q=0.01
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Connection:
keep-alive
Content-Length:
104
Content-Type:
application/json
Host:
Origin:
Referer:
https://reits.szse.cn/disclosure/index.html
Sec-Ch-Ua:
"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
empty
Sec-Fetch-Mode:
cors
Sec-Fetch-Site:
same-origin
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
X-Request-Type:
ajax
X-Requested-With:
XMLHttpRequest
获取网页返回的响应,这是一个嵌套的json数据;
定位到 "data"键下"title"键对应的值,这是PDF文件的标题;
定位到 "data"键下 "attachPath"键对应的值,这是PDF文件URL,前面加上"https://disc.static.szse.cn",构成一个完整的PDF下载URL;
下载PDF文件,保存到文件夹:F:\AI自媒体内容\AI炒股\REITs
注意:每一步都要输出信息
PDF文件标题中可能包括一些不符合window系统命名规则的特殊符号,在重命名PDF文件前要先进行处理;
每下一个PDF文件,就随机暂停3-6秒;
源代码:
import requests
import json
import os
import time
import random
import re
定义请求URL和请求头
url = "https://reits.szse.cn/api/disc/announcement/annList?random=0.3555675437003616"
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Type": "application/json",
"Host": "http://reits.szse.cn",
"Origin": "https://reits.szse.cn",
"Referer": "https://reits.szse.cn/disclosure/index.html",
"Sec-Ch-Ua": '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
"X-Request-Type": "ajax",
"X-Requested-With": "XMLHttpRequest"
}
定义请求载荷
payload = {
"seDate": "", "",
"channelCode": "reits-xxpl",
"bigCategoryId": "directions",
"pageSize": 50,
"pageNum": 1
}
发送POST请求
response = requests.post(url, headers=headers, json=payload)
检查响应状态码
if response.status_code == 200:
print("请求成功,状态码: 200 OK")
else:
print(f"请求失败,状态码: {response.status_code}")
exit()
解析JSON响应
data = response.json()
检查是否有数据
if "data" in data and isinstance(data"data", list):
for item in data"data":
获取PDF标题
pdf_title = item.get("title", "unknown_title")
print(f"PDF标题: {pdf_title}")
获取PDF URL
pdf_url = item.get("attachPath", "")
if pdf_url:
pdf_url = "https://disc.static.szse.cn" + pdf_url
print(f"PDF URL: {pdf_url}")
处理PDF标题中的非法字符
pdf_title = re.sub(r'\<\>:"/\\\\\|?\*', '_', pdf_title)
定义保存路径
save_path = f"F:\\AI自媒体内容\\AI炒股\\REITs\\{pdf_title}.pdf"
下载PDF文件
pdf_response = requests.get(pdf_url)
if pdf_response.status_code == 200:
with open(save_path, 'wb') as f:
f.write(pdf_response.content)
print(f"PDF文件已保存到: {save_path}")
else:
print(f"下载PDF文件失败,状态码: {pdf_response.status_code}")
随机暂停3-6秒
time.sleep(random.uniform(3, 6))
else:
print("没有找到数据")
