论文网址:https://arxiv.org/pdf/1506.02640
训练集博客链接:目标检测实战篇1------数据集介绍(PASCAL VOC,MS COCO)-CSDN博客
代码文件:在我资源里,但是好像还在审核,大家可以先可以,如果没有的话就评论,我发给你。
0、作者
Joseph Redmon是发表这篇论文的作者,最著名的四篇论文为YOLOv1,YOLO9000(YOLOV2)、YOLOv3和Xron-Net(与轻量化相关),作者毕业于华盛顿大学。很厉害的一位人。大家可以去了解一下。
一、前言和预备知识
之前我所发布的,都是分类问题,解决的概念就是输入一张图片,然后输出这个图片中的内容是什么类别,这种方法在很多问题上以及能够解决了,但是要清楚这个物体在图片中那个位置,这还是很难解决的,所以就引入了目标检测的概念,目标检测就是做到不仅判断物体的类别还可以得出物体所在位置,而目前最热门的目标检测的模型也就是YOLO系列了。
YOLO系列的模型,是为了解决当时目标检测模型的帧率太低而提出来的模型。英文全称是You only look once。
深度学习目标检测算法分类:
(1)two-stage 两个阶段的检测,模型举例 Faster-RCNN Mask-Rcnn系列
(2) one-stage 一个阶段的检测:YOLO系列
这两个主要区别可以简单理解为,两个阶段有一个选择预选框和物体分类的一个过程,而单阶段的将检测问题转换为一个回归问题。
YOLO是目前比较流行的目标检测算法,速度快并且结构简单。
YOLOV1,是以Joseph Redmon为首的大佬们于2015年提出的一种新的目标检测算法。它与之前的目标检测算法如R-CNN等不同之处在于,R-CNN等目标检测算法是两阶段算法, 步骤为先在图片上生成候选框,然后利用分类器对这些候选框进行逐一的判断;而YOLOv1是一阶段算法,是端到端的算法,它把目标检测问题看作回归问题,将图片输入单一的神经网络,然后就输出得到了图片的物体边界框(boundingbox)以及分类概率等信息。
总结:YOLOv1直接从输入的图像,仅仅经过一个神经网络,直接得到一些bounding box(位置坐标)以及每个bounding box对所有类别的一个概率情况,因为整个的检测过程仅仅有一个网络,所以可以直接进行端到端的优化,而无需像Faster R-CNN的分阶段的优化。
end-to-end(端到端):指的是一个过程,输入原始数据,输出最后结果。之前的网络Fast RCNN等这种网络分为两个阶段,一个是预选框的生成和目标分类与边界框回归,具体内容大家可以自行理解。
YOLO的核心思想就是把目标检测转变为一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
二、网络结构
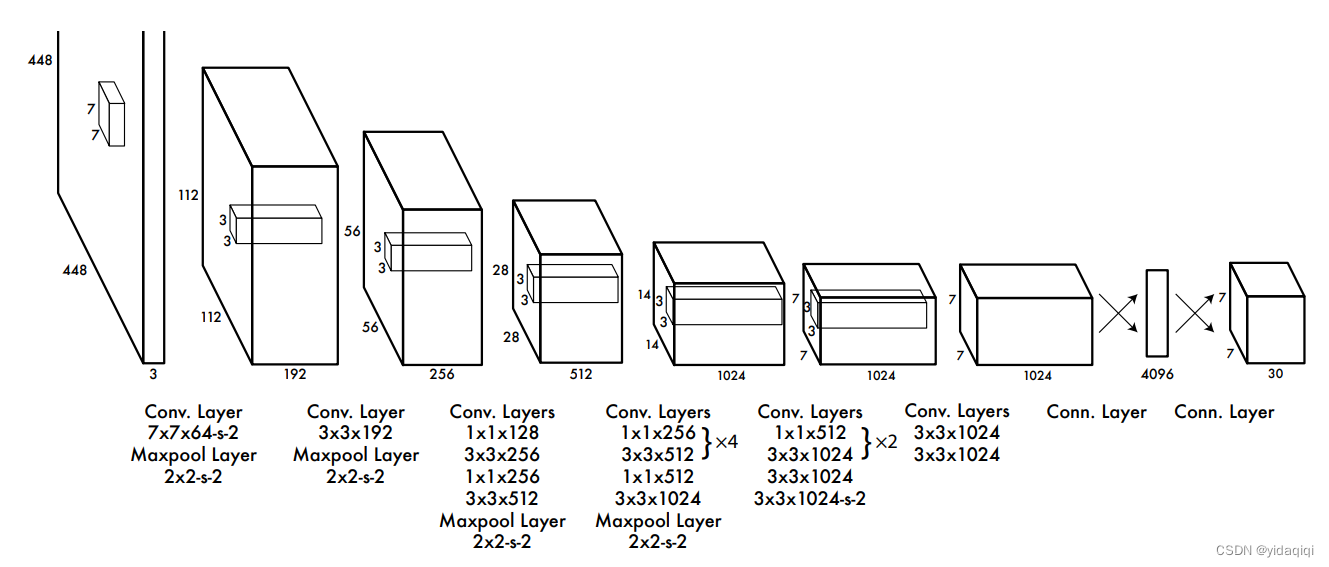
YOLOv1的网络结构简单清晰,是一个最传统的one-stage的卷积神经网络。
网络输入:448*448*3的彩色图片。
中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
网络输出:7*7*30的预测结果。
三、网络细节
YOLOv1采用的是"分而治之"的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。回忆一下,在Faster R-CNN中,是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。在YOLOv1中,通过划分得到了7×7个网格,这49个网格就相当于是目标的感兴趣区域。通过这种方式,我们就不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处!

四、预测阶段讲解(前向推断)
就是模型训练完后,向训练好的模型输入图片,然后得到最后结果的一个过程。
YOLOv1训练完后,是一个深度卷积神经网络,网络结构如下图所示

将网络当成一个黑箱子,输入的是一个448*448*3的RGB图像,输出的是一个7*7*30的向量。
网络结构很简单,大概就是卷积、池化、全连接层,一目了然。
而最后输出的向量,包含了类别、框、置信度等结果,而我们只需要解释这个向量就得到最后的结果了。
下面对最后输出的向量,进行一个分析,当我们输入一张图片的时候,最后会生成7*7*30的向量,如何去理解呢,可以将这个向量看做成7*7个1*30的向量,也就是49个1*30的向量,这里的每个1*30的向量,对应于前面的一个grid cell,将向量拆分为两个预测框的坐标以及预测框包含物体的置信度,和20个类别的条件概率。其中每个gridcell只会预测一个物体,也因此暴露出YOLOv1在小目标上检测的缺陷。然后预测中又引入了NMS向量对上述的98个框进行筛选,最后才可以得出我们的结果,大家读到这里,可能还是有一些不能理解的,所以请大家观看代码,代码都有注释。
python
import numpy as np
import torch
from PIL import ImageFont, ImageDraw
from cv2 import cv2
from matplotlib import pyplot as plt
# import cv2
from torchvision.transforms import ToTensor
from draw_rectangle import draw
from new_resnet import resnet50
# voc数据集的类别信息,这里转换成字典形式 键是真名 后面是值
classes = {"aeroplane": 0, "bicycle": 1, "bird": 2, "boat": 3, "bottle": 4, "bus": 5, "car": 6, "cat": 7, "chair": 8, "cow": 9, "diningtable": 10, "dog": 11, "horse": 12, "motorbike": 13, "person": 14, "pottedplant": 15, "sheep": 16, "sofa": 17, "train": 18, "tvmonitor": 19}
# 测试图片的路径
img_root = r"D:\\program\\Object_detection\\YOLOV1-pytorch-main\\test.jpg"
# 网络模型
model = resnet50()
# 加载权重,就是在train.py中训练生成的权重文件yolo.pth
model.load_state_dict(torch.load(r"D:\\program\\Object_detection\\YOLOV1-pytorch-main\\yolo.pth"))
# 测试模式
model.eval()
# 设置置信度 超参数设置
confident = 0.2
# 设置iou阈值
iou_con = 0.4
# 类别信息,这里写的都是voc数据集的,如果是自己的数据集需要更改
VOC_CLASSES = (
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
# 类别总数:20
CLASS_NUM = len(VOC_CLASSES) # 获得元组长度
"""
注意:预测和训练的时候是不同的,训练的时候是有标签参考的,在测试的时候会直接输出两个预测框,
保留置信度比较大的,再通过NMS处理得到最终的预测结果,不要跟训练阶段搞混了
"""
# target 7*7*30 值域为0-1
class Pred():
# 参数初始化
def __init__(self, model, img_root): # 传入预测模型,以及需要预测图片的路径
self.model = model
self.img_root = img_root
def result(self):
# 读取测试的图像
img = cv2.imread(self.img_root)
# 获取高宽信息
h, w, _ = img.shape # 行数 列数
# 调整图像大小
image = cv2.resize(img, (448, 448)) # cv2.resize(img,(448,448)) 第一个参数是需要调整的图像,第二个是需要调整到的大小
# CV2读取的图像是BGR,这里转回RGB模式
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 图像均值
mean = (123, 117, 104) # RGB 训练数据集上,得到的图象均值
# 减去均值进行标准化操作 OPENCV读入的图片,默认是numpy数组的类型,
img = img - np.array(mean, dtype=np.float32)
# 创建数据增强函数
transform = ToTensor()
# 图像转为tensor,因为cv2读取的图像是numpy格式
img = transform(img)
# 输入要求是BCHW,加一个batch维度 输入一般要求都是四个维度,不管什么代码中,也就是增加一个batchsize 的维度
img = img.unsqueeze(0)
# 图像输入模型,返回值为1*7*7*30的张量
Result = self.model(img)
# 获取目标的边框信息
bbox = self.Decode(Result)
# 非极大值抑制处理
bboxes = self.NMS(bbox) # n*6 bbox坐标是基于7*7网格需要将其转换成448
# draw(image, bboxes, classes)
if len(bboxes) == 0:
print("未识别到任何物体")
print("尝试减小 confident 以及 iou_con")
print("也可能是由于训练不充分,可在训练时将epoch增大")
for i in range(0, len(bboxes)): # bbox坐标将其转换为原图像的分辨率
bboxes[i][0] = bboxes[i][0] * 64
bboxes[i][1] = bboxes[i][1] * 64
bboxes[i][2] = bboxes[i][2] * 64
bboxes[i][3] = bboxes[i][3] * 64
x1 = bboxes[i][0].item() # 后面加item()是因为画框时输入的数据不可一味tensor类型
x2 = bboxes[i][1].item()
y1 = bboxes[i][2].item()
y2 = bboxes[i][3].item()
class_name = bboxes[i][5].item()
print(x1, x2, y1, y2, VOC_CLASSES[int(class_name)])
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (144, 144, 255)) # 画框
plt.imsave('test_001.jpg', image)
# cv2.imwrite("img", image)
# cv2.imshow('img', image)
# cv2.waitKey(0)
# 接受的result的形状为1*7*7*30
def Decode(self, result): # 接受模型输出结果
# 去掉batch维度 从1*7*7*30的张量变成7*7*30
result = result.squeeze() # 函数作用,将张量中所有维度为1的都给去掉
# 提取置信度信息,并在取出的置信度信息向量的最后一个维度增加一维,跟后面匹配result[:, :, 4]的形状为7*7,最后变为7*7*1
grid_ceil1 = result[:, :, 4].unsqueeze(2)
# 同上
grid_ceil2 = result[:, :, 9].unsqueeze(2)
# 两个置信度信息按照维度2拼接
grid_ceil_con = torch.cat((grid_ceil1, grid_ceil2), 2)
# 按照第二个维度进行最大值求取,一个grid ceil两个bbox,两个confidence,也就是找置信度比较大的那个,形状都是7*7
grid_ceil_con, grid_ceil_index = grid_ceil_con.max(2)
# 找出一个gird cell中预测类别最大的物体的索引和预测条件类别概率
class_p, class_index = result[:, :, 10:].max(2)
# 计算出物体的真实概率,类别最大的物体乘上置信度比较大的那个框得到最终的真实物体类别概率
class_confidence = class_p * grid_ceil_con
# 定义一个张量,记录位置信息
bbox_info = torch.zeros(7, 7, 6)
for i in range(0, 7):
for j in range(0, 7):
# 获取置信度比较大的索引位置
bbox_index = grid_ceil_index[i, j]# 第一个面存储的是
# 把置信度比较大的那个框的位置信息保存到bbox_info中,另一个直接抛弃
bbox_info[i, j, :5] = result[i, j, (bbox_index * 5):(bbox_index+1) * 5]
# 真实目标概率
bbox_info[:, :, 4] = class_confidence
# 类别信息
bbox_info[:, :, 5] = class_index
# 返回预测的结果,7*7*6 6 = bbox4个信息+类别概率+类别代号
return bbox_info
# 非极大值抑制处理,按照类别处理,bbox为Decode获取的预测框的位置信息和类别概率和类别信息
def NMS(self, bbox, iou_con=iou_con):
for i in range(0, 7):
for j in range(0, 7):
# xc = bbox[i, j, 0]
# yc = bbox[i, j, 1]
# w = bbox[i, j, 2] * 7
# h = bbox[i, j, 3] * 7
# Xc = i + xc
# Yc = j + yc
# xmin = Xc - w/2
# xmax = Xc + w/2
# ymin = Yc - h/2
# ymax = Yc + h/2
# 注意,目前bbox的四个坐标是以grid ceil的左上角为坐标原点,而且单位不一致中心点偏移的坐标是归一化为(0-7),宽高是(0-7),,单位不一致,全部归一化为(0-7)
# 计算预测框的左上角右下角相对于7*7网格的位置
xmin = j + bbox[i, j, 0] - bbox[i, j, 2] * 7 / 2 # xmin
xmax = j + bbox[i, j, 0] + bbox[i, j, 2] * 7 / 2 # xmax
ymin = i + bbox[i, j, 1] - bbox[i, j, 3] * 7 / 2 # ymin
ymax = i + bbox[i, j, 1] + bbox[i, j, 3] * 7 / 2 # ymax
bbox[i, j, 0] = xmin
bbox[i, j, 1] = xmax
bbox[i, j, 2] = ymin
bbox[i, j, 3] = ymax
# 调整形状,bbox本来就是(49*6),这里感觉没必要
bbox = bbox.view(-1, 6)
# 存放最终需要保留的预测框
bboxes = []
# 取出每个gird cell中的类别信息,返回一个列表
ori_class_index = bbox[:, 5]
# 按照类别进行排序,从高到低,返回的是排序后的类别列表和对应的索引位置,如下:
"""
类别排序
tensor([ 1., 1., 1., 1., 1., 1., 1., 2., 2., 2., 2., 2., 2., 2.,
3., 3., 3., 4., 4., 4., 4., 5., 5., 5., 6., 6., 6., 6.,
6., 6., 6., 6., 7., 8., 8., 8., 8., 8., 14., 14., 14., 14.,
14., 14., 14., 15., 15., 16., 17.], grad_fn=<SortBackward0>)
位置索引
tensor([48, 47, 46, 45, 44, 43, 42, 7, 8, 22, 11, 16, 14, 15, 24, 20, 1, 2,
6, 0, 13, 23, 25, 27, 32, 39, 38, 35, 33, 31, 30, 28, 3, 26, 10, 19,
9, 12, 29, 41, 40, 21, 37, 36, 34, 18, 17, 5, 4])
"""
class_index, class_order = ori_class_index.sort(dim=0, descending=False)
# class_index是一个tensor,这里把他转为列表形式
class_index = class_index.tolist() # .tolist()转成一个列表
# 根据排序后的索引更改bbox排列顺序
bbox = bbox[class_order, :]
a = 0
for i in range(0, CLASS_NUM):
# 统计目标数量,即某个类别出现在grid cell中的次数
num = class_index.count(i)
# 预测框中没有这个类别就直接跳过
if num == 0:
continue
# 提取同一类别的所有信息
x = bbox[a:a+num, :]
# 提取真实类别概率信息
score = x[:, 4]
# 提取出来的某一类别按照真实类别概率信息高度排序,递减
score_index, score_order = score.sort(dim=0, descending=True)
# 根据排序后的结果更改真实类别的概率排布
y = x[score_order, :]
# 先看排在第一位的物体的概率是否大有给定的阈值,不满足就不看这个类别了,丢弃全部的预测框
if y[0, 4] >= confident:
for k in range(0, num):
# 真实类别概率,排序后的
y_score = y[:, 4]
# 对真实类别概率重新排序,保证排列顺序依照递减,其实跟上面一样的,多此一举
_, y_score_order = y_score.sort(dim=0, descending=True)
y = y[y_score_order, :]
# 判断概率是否大于0
if y[k, 4] > 0:
# 计算预测框的面积
area0 = (y[k, 1] - y[k, 0]) * (y[k, 3] - y[k, 2])
for j in range(k+1, num):
# 计算剩余的预测框的面积
area1 = (y[j, 1] - y[j, 0]) * (y[j, 3] - y[j, 2])
x1 = max(y[k, 0], y[j, 0])
x2 = min(y[k, 1], y[j, 1])
y1 = max(y[k, 2], y[j, 2])
y2 = min(y[k, 3], y[j, 3])
w = x2 - x1
h = y2 - y1
if w < 0 or h < 0:
w = 0
h = 0
inter = w * h
# 计算与真实目标概率最大的那个框的iou
iou = inter / (area0 + area1 - inter)
# iou大于一定值则认为两个bbox识别了同一物体删除置信度较小的bbox
# 同时物体类别概率小于一定值也认为不包含物体
if iou >= iou_con or y[j, 4] < confident:
y[j, 4] = 0
for mask in range(0, num):
if y[mask, 4] > 0:
bboxes.append(y[mask])
# 进入下个类别
a = num + a
# 返回最终预测的框
return bboxes
if __name__ == "__main__":
Pred = Pred(model, img_root)
Pred.result()上述就是预测的代码,通过阅读代码的方式,能够清晰地理解到位,YOLOv1模型的预测过程,生成一个7*7*30的向量,对应于98个框,然后通过系列算法如NMS,进行筛选出我们最后结果。
五、训练阶段
训练阶段,我首先主要解释一下几个问题,首先是YOLOv1是端到端的一个网络,也就是输入的是原图,输出的是一个向量,而训练的过程包括两个过程,一个是前向传播,另一个就是反向传播,通过不断迭代,使梯度下降,进而使损失函数最小化,这个过程。训练的流程大致为,输入batchsize张图片,得出batchsize*7*7*30的一个张量,将该张量与标签(batchsize*7*7*30的向量)计算出损失为多少,然后根据这个损失对网络的参数进行梯度计算,不断迭代,不断优化参数,这样的一个过程。我觉得这样理解好理解的多。
这个代码大致流程可以分为以下部分
1、超参数初始化
2、数据初始化,构造数据迭代器,因为原本一张图片对应的标签并不是7*7*30的一个向量,因此要对数据进行预处理,把每一个图片的标签变成7*7*30的一个格式。
3、网络初始化,我这里给的代码使ResNet50的网络,这个网络也叫做backbone大家以后会经常看到的,网络结构差不多,然后输入是1*7*7*30,输出就是1*7*7*30的这样一个结构
4、上述都可以看成初始化过程,然后就开始训练,也就是前向传播,反向传播,参数优化这样迭代的一个过程,最后保存参数。
这块的代码如下图所示,都带有注释的。
python
from yoloData import yoloDataset # 数据集处理
from yoloLoss import yoloLoss # YOLOv1的损失函数
from new_resnet import resnet50 # backbone采用的是resnet
from torchvision import models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader # 这四个torch
import torch
"""
voc------------------.txt 第一个为图片的路径 ,后边的五个数字依次是 位置坐标和该框所属于的类别。
"""
device = 'cuda' # 设备名称
file_root = r'D:\cv\第三章\YOLO\yolov1-main\VOCtrainval_11-May-2012\VOCdevkit\VOC2012\JPEGImages\\' # 最后两个\\十分重要
batch_size = 4 # batch_size
learning_rate = 0.001 # 学习率
num_epochs = 100
# 自定义训练数据集
train_dataset = yoloDataset(img_root=file_root, list_file='voctrain.txt', train=True, transform=[transforms.ToTensor()]) # 对txt标签数据处理
# 加载自定义的训练数据集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
# 自定义测试数据集
test_dataset = yoloDataset(img_root=file_root, list_file='voctest.txt', train=False, transform=[transforms.ToTensor()])
# 加载自定义的测试数据集
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
print('the dataset has %d images' % (len(train_dataset)))
"""
下面这段代码主要适用于迁移学习训练,可以将预训练的ResNet-50模型的参数赋值给新的网络,以加快训练速度和提高准确性。
"""
# 创建改编的ResNet50
net = resnet50()
# 放到GPU上
net = net.cuda()
# 直接使用pytorch加载resnet50,带预训练权重
resnet = models.resnet50(pretrained=True) # torchvison库中的网络
# 获取resnet的训练参数
new_state_dict = resnet.state_dict()
# 获取刚创建的改编的resnet50()的参数
op = net.state_dict()
# 无论名称是否相同都可以使用
for new_state_dict_num, new_state_dict_value in enumerate(new_state_dict.values()):
# op.keys()表示获取模型参数字典中的所有键值
for op_num, op_key in enumerate(op.keys()):
# 320个key中不需要最后的全连接层的两个参数
if op_num == new_state_dict_num and op_num <= 317:
op[op_key] = new_state_dict_value
# 将预训练好的参数放入改编的ResNet的网络中,加快训练速度
net.load_state_dict(op)
print('cuda', torch.cuda.current_device(), torch.cuda.device_count()) # 确认一下cuda的设备
# 创建损失函数
criterion = yoloLoss(7, 2, 5, 0.5)
# 放到GPU上
criterion = criterion.to(device)
# 训练前需要加入的语句,一般有Dropout()的时候要加
net.train()
# 里面存字典
params = []
# net.named_parameters()是一个PyTorch函数,它返回一个包含模型中所有需要学习的参数(即权重和偏置项)及其名称的迭代器。
params_dict = dict(net.named_parameters())
for key, value in params_dict.items():
# 把字典放到列表中,这个"+"可以理解为append
params += [{'params': [value], 'lr':learning_rate}]
# 定义优化器 "随机梯度下降"
optimizer = torch.optim.SGD(
# 上面已经将模型参数打包成字典了,这里不需要用net.parameters()了
params,
# 学习率
lr=learning_rate,
# 动量
momentum=0.9,
# 正则化
weight_decay=5e-4)
# Windows环境下使用多进程时需要调用的函数,我训练的时候没用。在Windows下使用多进程需要先将Python脚本打包成exe文件,而freeze_support()的作用就是冻结可执行文件的代码,确保在Windows下正常运行多进程。
# torch.multiprocessing.freeze_support() # 多进程相关 猜测是使用多显卡训练需要
"""
这里解释下自己定义参数列表和直接使用net.parameter()的区别:
在大多数情况下,直接使用net.parameters()和将模型参数放到字典中是没有区别的,
因为net.parameters()本身就是一个包含模型所有参数的列表。
但是,如果我们想要对不同的参数设置不同的超参数,那么将模型参数放到字典中会更加方便。
使用net.parameters()的话,我们需要手动区分不同的参数,
再分别进行超参数的设置。而将模型参数放到字典中后,我们可以直接对每个参数设置对应的超参数,更加简洁和灵活。
举个例子,如果我们想要对卷积层和全连接层设置不同的学习率,使用net.parameters()的话,
我们需要手动区分哪些参数属于卷积层,哪些参数属于全连接层,
然后分别对这两部分参数设置不同的学习率。而将模型参数放到字典中后,
我们可以直接对卷积层和全连接层的参数分别设置不同的学习率,更加方便和清晰。
"""
# 开始训练
for epoch in range(num_epochs):
# 这个地方形成习惯,因为网络可能会用到Dropout和batchnorm
net.train()
# 调整学习率
if epoch == 60:
learning_rate = 0.0001
if epoch == 80:
learning_rate = 0.00001
# optimizer.param_groups 返回一个包含优化器参数分组信息的列表,每个分组是一个字典,主要包含以下键值:
# params:当前参数分组中需要更新的参数列表,如网络的权重,偏置等。
# lr:当前参数分组的学习率。就是我们要提取更新的
# momentum:当前参数分组的动量参数。
# weight_decay:当前参数分组的权重衰减参数。
for param_group in optimizer.param_groups:
param_group['lr'] = learning_rate # 更改全部的学习率
print('\n\nStarting epoch %d / %d' % (epoch + 1, num_epochs))
print('Learning Rate for this epoch: {}'.format(learning_rate))
# 计算损失
total_loss = 0.
# 开始迭代训练
for i, (images, target) in enumerate(train_loader):
images, target = images.cuda(), target.cuda()
pred = net(images)
# 创建损失函数
loss = criterion(pred, target)
total_loss += loss.item()
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if (i + 1) % 5 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f, average_loss: %.4f' % (epoch +1, num_epochs, i + 1, len(train_loader), loss.item(), total_loss / (i + 1)))
# 开始测试
validation_loss = 0.0
net.eval()
for i, (images, target) in enumerate(test_loader):
images, target = images.cuda(), target.cuda()
# 输入图像
pred = net(images)
# 计算损失
loss = criterion(pred, target)
# 累加损失
validation_loss += loss.item()
# 计算平均loss
validation_loss /= len(test_loader)
best_test_loss = validation_loss
print('get best test loss %.5f' % best_test_loss)
# 保存模型参数
torch.save(net.state_dict(), 'yolo.pth')六、损失函数
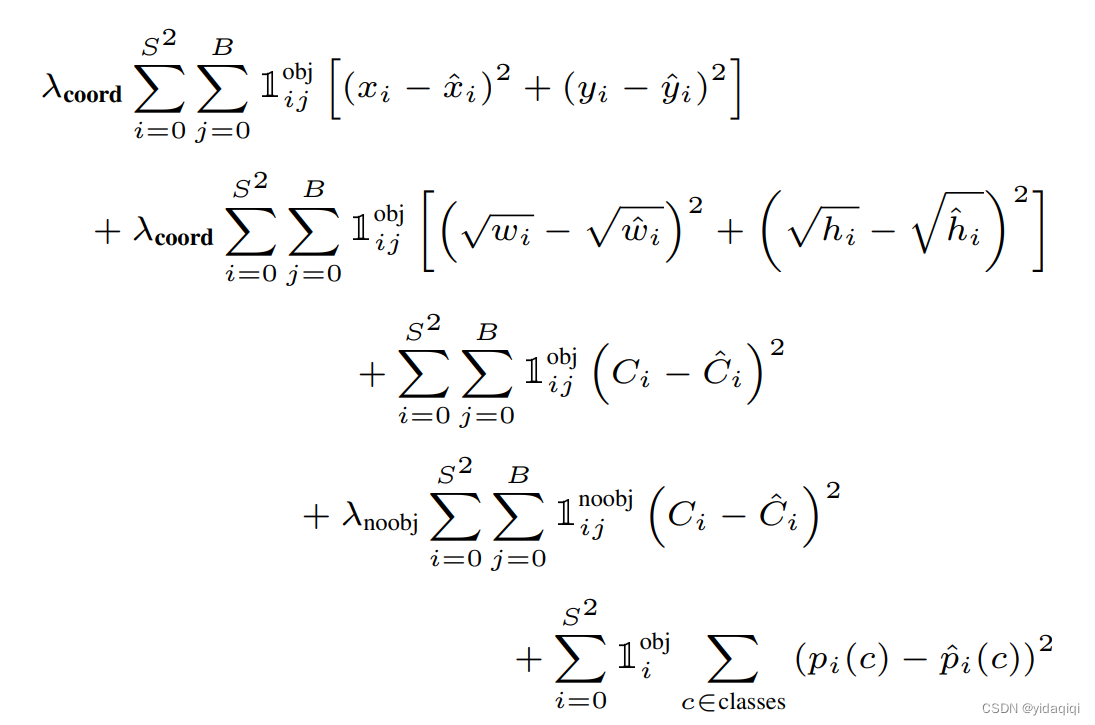
可以大致看成四个部分,
第一部分表示负责检测物体的bounding box中心点定位误差,要和ground truth尽可能拟合,x xx带上标的是标注值,不带上标的是预测值。
第二表示表示负责检测物体的bounding box的宽高定位误差,加根号是为了使得对小框的误差更敏感。
第三部分:

第四部分是负责检测物体的grid的分类误差。
损失函数的代码:带注释
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import warnings
warnings.filterwarnings('ignore') # 忽略警告消息
CLASS_NUM = 20 # (使用自己的数据集时需要更改)
class yoloLoss(nn.Module):
def __init__(self, S, B, l_coord, l_noobj):
# 一般而言 l_coord = 5 , l_noobj = 0.5
super(yoloLoss, self).__init__()
# 网格数
self.S = S # S = 7
# bounding box数量
self.B = B # B = 2
# 权重系数
self.l_coord = l_coord
# 权重系数
self.l_noobj = l_noobj
def compute_iou(self, box1, box2): # box1(2,4) box2(1,4)
N = box1.size(0) # 2
M = box2.size(0) # 1
lt = torch.max( # 返回张量所有元素的最大值
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, :2].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, :2].unsqueeze(0).expand(N, M, 2),
)
rb = torch.min(
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, 2:].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, 2:].unsqueeze(0).expand(N, M, 2),
)
wh = rb - lt # [N,M,2]
wh[wh < 0] = 0 # clip at 0
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] 重复面积
area1 = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1]) # [N,]
area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1]) # [M,]
area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M]
iou = inter / (area1 + area2 - inter)
# iou的形状是(2,1),里面存放的是两个框的iou的值
return iou # [2,1]
def forward(self, pred_tensor, target_tensor):
'''
pred_tensor: (tensor) size(batchsize,7,7,30)
target_tensor: (tensor) size(batchsize,7,7,30),就是在yoloData中制作的标签
'''
# batchsize大小
N = pred_tensor.size()[0]
# 判断目标在哪个网格,输出B*7*7的矩阵,有目标的地方为True,其他地方为false,这里就用了第4位,第9位和第4位一样就没判断
coo_mask = target_tensor[:, :, :, 4] > 0
# 判断目标不在那个网格,输出B*7*7的矩阵,没有目标的地方为True,其他地方为false
noo_mask = target_tensor[:, :, :, 4] == 0
# 将 coo_mask tensor 在最后一个维度上增加一维,并将其扩展为与 target_tensor tensor 相同的形状,得到含物体的坐标等信息,大小为batchsize*7*7*30
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor)
# 将 noo_mask 在最后一个维度上增加一维,并将其扩展为与 target_tensor tensor 相同的形状,得到不含物体的坐标等信息,大小为batchsize*7*7*30
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)
# 根据label的信息从预测的张量取出对应位置的网格的30个信息按照出现序号拼接成以一维张量,这里只取包含目标的
coo_pred = pred_tensor[coo_mask].view(-1, int(CLASS_NUM + 10))
# 所有的box的位置坐标和置信度放到box_pred中,塑造成X行5列(-1表示自动计算),一个box包含5个值
box_pred = coo_pred[:, :10].contiguous().view(-1, 5)
# 类别信息
class_pred = coo_pred[:, 10:] # [n_coord, 20]
# pred_tensor[coo_mask]把pred_tensor中有物体的那个网格对应的30个向量拿出来,这里对应的是label向量,只计算有目标的
coo_target = target_tensor[coo_mask].view(-1, int(CLASS_NUM + 10))
box_target = coo_target[:, :10].contiguous().view(-1, 5)
class_target = coo_target[:, 10:]
# 不包含物体grid ceil的置信度损失,这里是label的输出的向量。
noo_pred = pred_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
noo_target = target_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
# 创建一个跟noo_pred相同形状的张量,形状为(x,30),里面都是全0或全1,再使用bool将里面的0或1转为true和false
noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size()).bool()
# 把创建的noo_pred_mask全部改成false,因为这里对应的是没有目标的张量
noo_pred_mask.zero_()
# 把不包含目标的张量的置信度位置置为1
noo_pred_mask[:, 4] = 1
noo_pred_mask[:, 9] = 1
# 跟上面的pred_tensor[coo_mask]一个意思,把不包含目标的置信度提取出来拼接成一维张量
noo_pred_c = noo_pred[noo_pred_mask]
# 同noo_pred_c
noo_target_c = noo_target[noo_pred_mask]
# 计算loss,让预测的值越小越好,因为不包含目标,置信度越为0越好
nooobj_loss = F.mse_loss(noo_pred_c, noo_target_c, size_average=False) # 均方误差
# 注意:上面计算的不包含目标的损失只计算了置信度,其他的都没管
"""
计算包含目标的损失:位置损失+类别损失
"""
# 先创建两个张量用于后面匹配预测的两个编辑框:一个负责预测,一个不负责预测
# 创建一跟box_target相同的张量,这里用来匹配后面负责预测的框
coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool()
# 全部置为False
coo_response_mask.zero_() # 全部元素置False
# 创建一跟box_target相同的张量,这里用来匹配不负责预测的框
no_coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool()
# 全部置为False
no_coo_response_mask.zero_()
# 创建一个全0张量,匹配后面的预测框的iou
box_target_iou = torch.zeros(box_target.size()).cuda()
# 遍历每一个标注框,每次遍历两个是因为一个标注框对应有两个预测框要跟他匹配,box1 = 预测框 box2 = ground truth
# box_target.size()[0]:有多少bbox,并且一次取两个bbox,因为两个bbox才是一个完整的预测框
for i in range(0, box_target.size()[0], 2): #
# 第i个grid ceil对应的两个bbox
box1 = box_pred[i:i + 2]
# 创建一个和box1大小(2,5)相同的浮点型张量用来存储坐标,这里代码使用的torch版本可能比较老,其实Variable可以省略的
box1_xyxy = Variable(torch.FloatTensor(box1.size()))
# box1_xyxy[:, :2]为预测框中心点坐标相对于所在grid cell左上角的偏移,前面在数据处理的时候讲过label里面的值是归一化为(0-7)的,
# 因此这里得反归一化成跟宽高一样比例,归一化到(0-1),减去宽高的一半得到预测框的左上角的坐标相对于他所在的grid cell的左上角的偏移量
box1_xyxy[:, :2] = box1[:, :2] / float(self.S) - 0.5 * box1[:, 2:4]
# 计算右下角坐标相对于预测框所在的grid cell的左上角的偏移量
box1_xyxy[:, 2:4] = box1[:, :2] / float(self.S) + 0.5 * box1[:, 2:4]
# target中的两个框的目标信息是一模一样的,这里取其中一个就行了
box2 = box_target[i].view(-1, 5)
box2_xyxy = Variable(torch.FloatTensor(box2.size()))
box2_xyxy[:, :2] = box2[:, :2] / float(self.S) - 0.5 * box2[:, 2:4]
box2_xyxy[:, 2:4] = box2[:, :2] / float(self.S) + 0.5 * box2[:, 2:4]
# 计算两个预测框与标注框的IoU值,返回计算结果,是个列表
iou = self.compute_iou(box1_xyxy[:, :4], box2_xyxy[:, :4])
# 通过max()函数获取与gt最大的框的iou和索引号(第几个框)
max_iou, max_index = iou.max(0)
# 将max_index放到GPU上
max_index = max_index.data.cuda()
# 保留IoU比较大的那个框
coo_response_mask[i + max_index] = 1 # IOU最大的bbox
# 舍去的bbox,两个框单独标记为1,分开存放,方便下面计算
no_coo_response_mask[i + 1 - max_index] = 1
# 将预测框比较大的IoU的那个框保存在box_target_iou中,
# 其中i + max_index表示当前预测框对应的位置,torch.LongTensor([4]).cuda()表示在box_target_iou中存储最大IoU的值的位置。
box_target_iou[i + max_index, torch.LongTensor([4]).cuda()] = max_iou.data.cuda()
# 放到GPU上
box_target_iou = Variable(box_target_iou).cuda()
# 负责预测物体的预测框的位置信息(含物体的grid ceil的两个bbox与ground truth的IOU较大的一方)
box_pred_response = box_pred[coo_response_mask].view(-1, 5)
# 标注信息,拿出来一个计算就行了,因为两个信息一模一样
box_target_response_iou = box_target_iou[coo_response_mask].view(-1, 5)
# IOU较小的一方
no_box_pred_response = box_pred[no_coo_response_mask].view(-1, 5)
no_box_target_response_iou = box_target_iou[no_coo_response_mask].view(-1, 5)
# 不负责预测物体的置信度置为0,本来就是0,这里有点多此一举
no_box_target_response_iou[:, 4] = 0
# 负责预测物体的标注框对应的label的信息
box_target_response = box_target[coo_response_mask].view(-1, 5)
# 包含物的体grid ceil中IOU较大的bbox置信度损失
contain_loss = F.mse_loss(box_pred_response[:, 4], box_target_response_iou[:, 4], size_average=False)
# 不包含物体的grid ceil中舍去的bbox的置信度损失
no_contain_loss = F.mse_loss(no_box_pred_response[:, 4], no_box_target_response_iou[:, 4], size_average=False)
# 负责预测物体的预测框的位置损失
loc_loss = F.mse_loss(box_pred_response[:, :2], box_target_response[:, :2], size_average=False) + F.mse_loss(
torch.sqrt(box_pred_response[:, 2:4]), torch.sqrt(box_target_response[:, 2:4]), size_average=False)
# 负责预测物体的所在grid cell的类别损失
class_loss = F.mse_loss(class_pred, class_target, size_average=False)
# 计算总损失,这里有个权重
return (self.l_coord * loc_loss + contain_loss + self.l_noobj * (nooobj_loss + no_contain_loss) + class_loss) / N有很多地方不是写的很好,后续会不断更改完善,大家有问题可以一起商讨。有不足希望大家批评指正,谢谢给我观众老爷。