ChatGPT输入提示词:
你是一个Python编程专家,要完成一个Python脚本编写任务,具体步骤如下:
读取视频:"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.mkv";
读取文本文档里面的每一行:"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.srt"
定位到内容为数字的那些行;
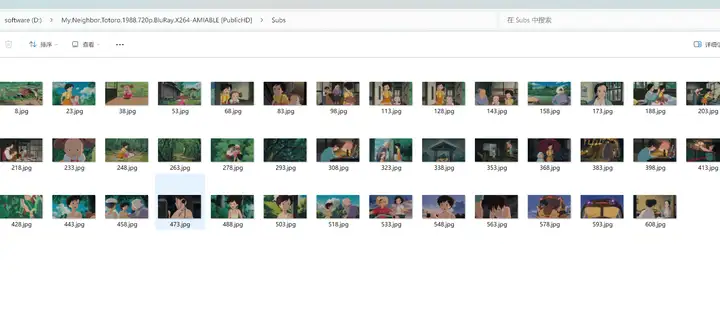
然后读取数字后面的时间轴,在这个时间轴开始的时间点截取视频中的图片,截图保存在文件夹"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\Subs",图片的格式为jpg,图片的文件名为这个数字;
从数字8开始,以15递增,一直到1056;
举个例子:
Srt文档中读取到下面内容:
"""
8
00:00:55,018 --> 00:00:58,419
We'll run across the bridge
"""
那么,就在视频的时间点:00:00:55,018,进行截图,图片名称为8.jpg
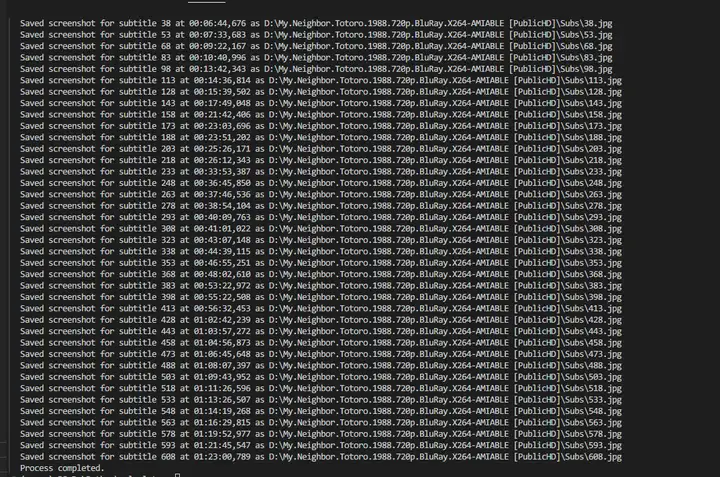
注意:每一步都要输出信息到屏幕
源代码:
import re
import os
import cv2
from datetime import datetime, timedelta
文件路径
video_path = r"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.mkv"
srt_path = r"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE.srt"
output_dir = r"D:\My.Neighbor.Totoro.1988.720p.BluRay.X264-AMIABLE PublicHD\Subs"
创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
打开视频文件
cap = cv2.VideoCapture(video_path)
def timestamp_to_seconds(timestamp):
将 '00:00:55,018' 转换为秒
time_obj = datetime.strptime(timestamp, '%H:%M:%S,%f')
seconds = timedelta(hours=time_obj.hour, minutes=time_obj.minute, seconds=time_obj.second, microseconds=time_obj.microsecond).total_seconds()
return seconds
读取字幕文件
with open(srt_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
提取时间戳和数字
regex = re.compile(r'^(\d+)\n(\d{2}:\d{2}:\d{2},\d{3}) --> \d{2}:\d{2}:\d{2},\d{3}')
timestamps = {}
for i in range(len(lines)):
match = regex.match(''.join(linesi:i+2))
if match:
index = int(match.group(1))
start_time = match.group(2)
timestampsindex = start_time
控制截图频率
for num in range(8, 1057, 15):
if num in timestamps:
timestamp = timestampsnum
seconds = timestamp_to_seconds(timestamp)
cap.set(cv2.CAP_PROP_POS_MSEC, seconds * 1000) # 设置视频时间
ret, frame = cap.read()
if ret:
保存截图
output_filename = os.path.join(output_dir, f"{num}.jpg")
cv2.imwrite(output_filename, frame)
print(f"Saved screenshot for subtitle {num} at {timestamp} as {output_filename}")
cap.release()
print("Process completed.")