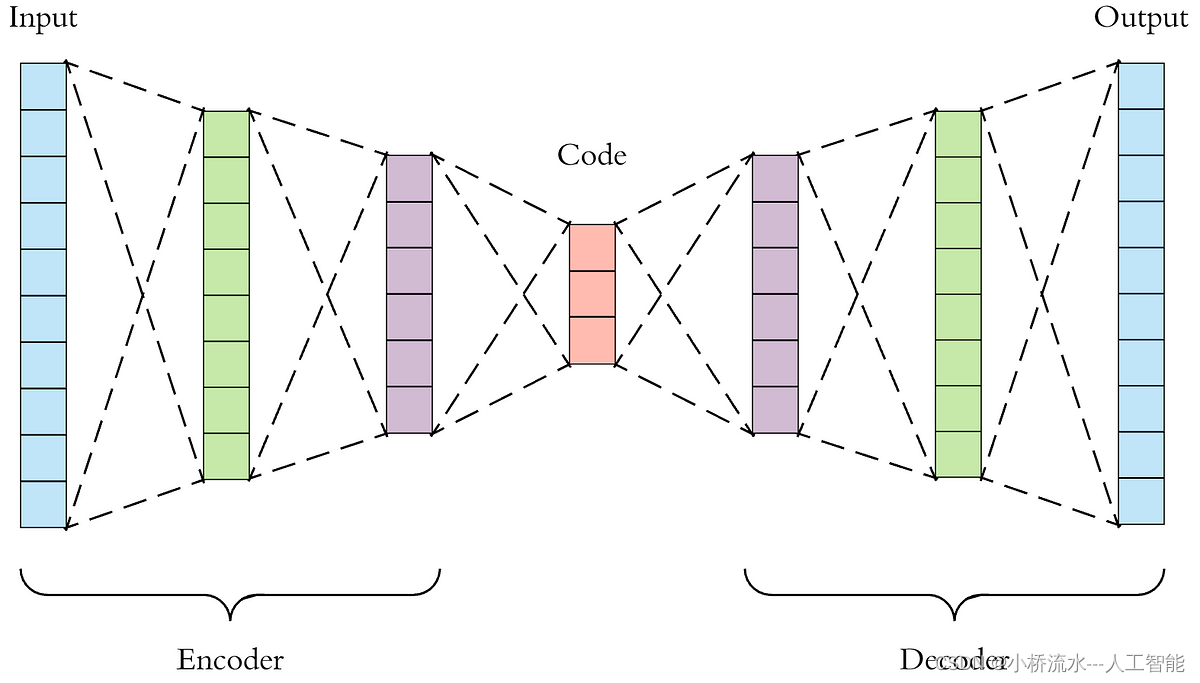
堆叠自编码器(Stacked Autoencoders, SAE)相对于卷积神经网络(CNN)在某些情况下具有更高的解释性,主要原因在于其结构和特性使其在特征提取和表示上具有一定的透明度和可解释性。以下是具体原因:
-
特征表示的透明性:
- 低维特征表示:自编码器通过压缩输入数据,将高维数据映射到低维特征空间。这些低维特征表示保留了输入数据的主要信息,并且这种映射是显式的,易于分析和理解。
- 逐层特征提取:堆叠自编码器通过逐层训练,每一层的编码器学习不同层次的特征,逐步构建起对数据的高级表示。这种逐层特征提取过程相对透明,可以更容易地解释每一层所学到的特征。
-
特征重建能力:
- 重建输入数据:自编码器不仅学习到数据的特征表示,还能够通过解码器重建输入数据。通过比较原始数据和重建数据之间的差异,可以更直观地理解模型所学到的特征及其对输入数据的重构能力。这种重建能力使得特征表示更加透明和可解释。
- 去噪能力:在训练过程中引入噪声的去噪自编码器(Denoising Autoencoders)可以学习到对输入数据的鲁棒表示,从而增强模型对数据特征的理解和解释。
-
层级结构的可解释性:
- 简单结构:自编码器的结构相对简单,由编码器和解码器组成。编码器将输入数据压缩到低维空间,解码器将其重建回高维空间。这种结构使得每一层的操作和功能更容易理解和解释。
- 显式特征提取:由于每一层的编码器学习到的特征表示是显式的,可以通过分析每一层的权重和激活值来理解模型如何提取和表示数据特征。
-
无监督学习的直观性:
- 无监督特征学习:自编码器通过无监督学习从数据中提取特征,这种学习过程不依赖于标签信息,更加专注于数据本身的结构和模式。这使得自编码器学习到的特征更加反映数据的内在性质,具有较高的解释性。
- 对数据分布的捕捉:自编码器能够捕捉数据的分布和结构,通过可视化低维特征空间中的数据分布,可以更直观地理解数据的聚类和分类特性。
相比之下,虽然CNN在处理具有空间结构的数据(如图像)时表现出色,但其特征提取过程相对复杂,卷积层和池化层的操作使得特征表示更加抽象和难以解释。CNN中的特征表示往往是高维的,并且受到卷积核和池化操作的影响,很难直观地理解每一层所学到的特征。因此,尽管CNN在性能上具有优势,但在解释性方面,堆叠自编码器由于其结构和训练方式的特点,往往具有更高的透明度和可解释性。