目录
- [1. Flip翻转](#1. Flip翻转)
- [2. Rotate旋转](#2. Rotate旋转)
- [3. scale缩放](#3. scale缩放)
- [4. crop裁剪](#4. crop裁剪)
- [5. 总结](#5. 总结)
- [6. 完整代码](#6. 完整代码)
1. Flip翻转

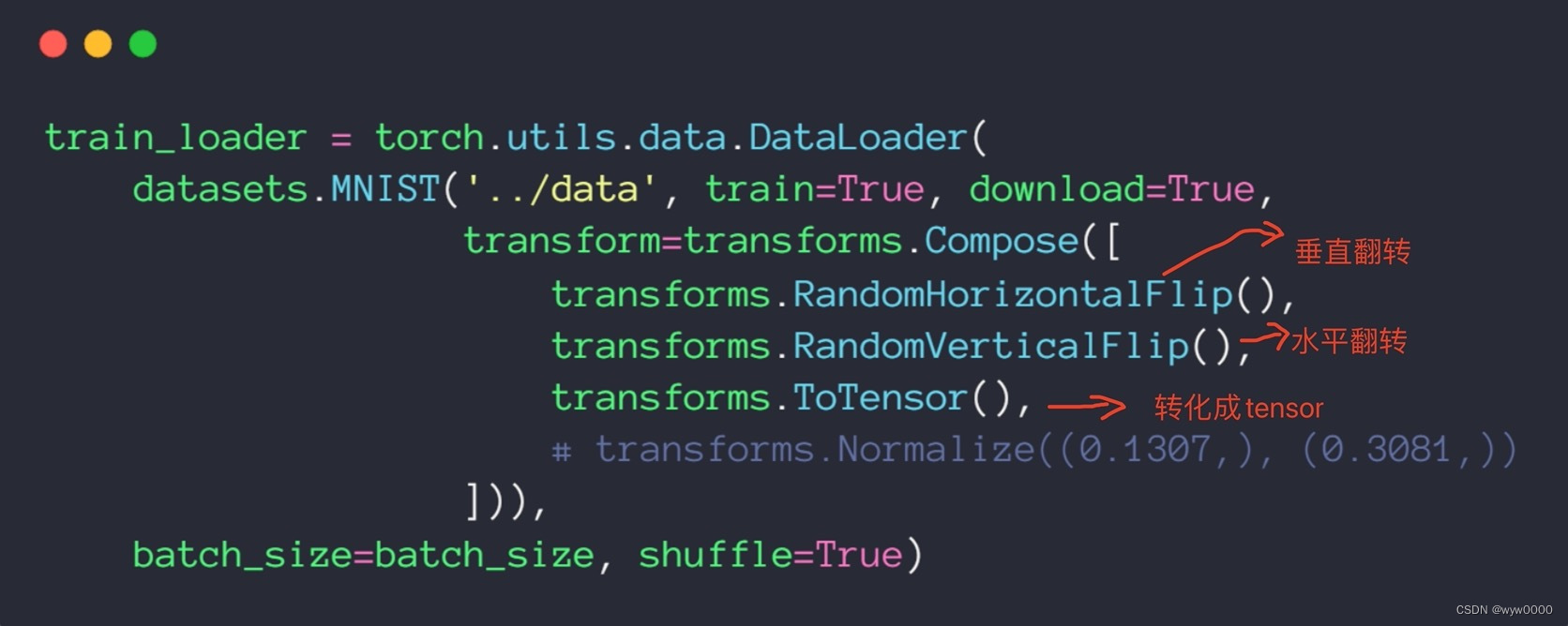
上图中做了随机水平翻转和随机垂直翻转,翻转完成后转化成tensor
2. Rotate旋转


上图中作了2次旋转第一次旋转角度在-15<0<15范围内,随机出一个角度,第二次旋转角是从90,180,270中random出一个。
3. scale缩放

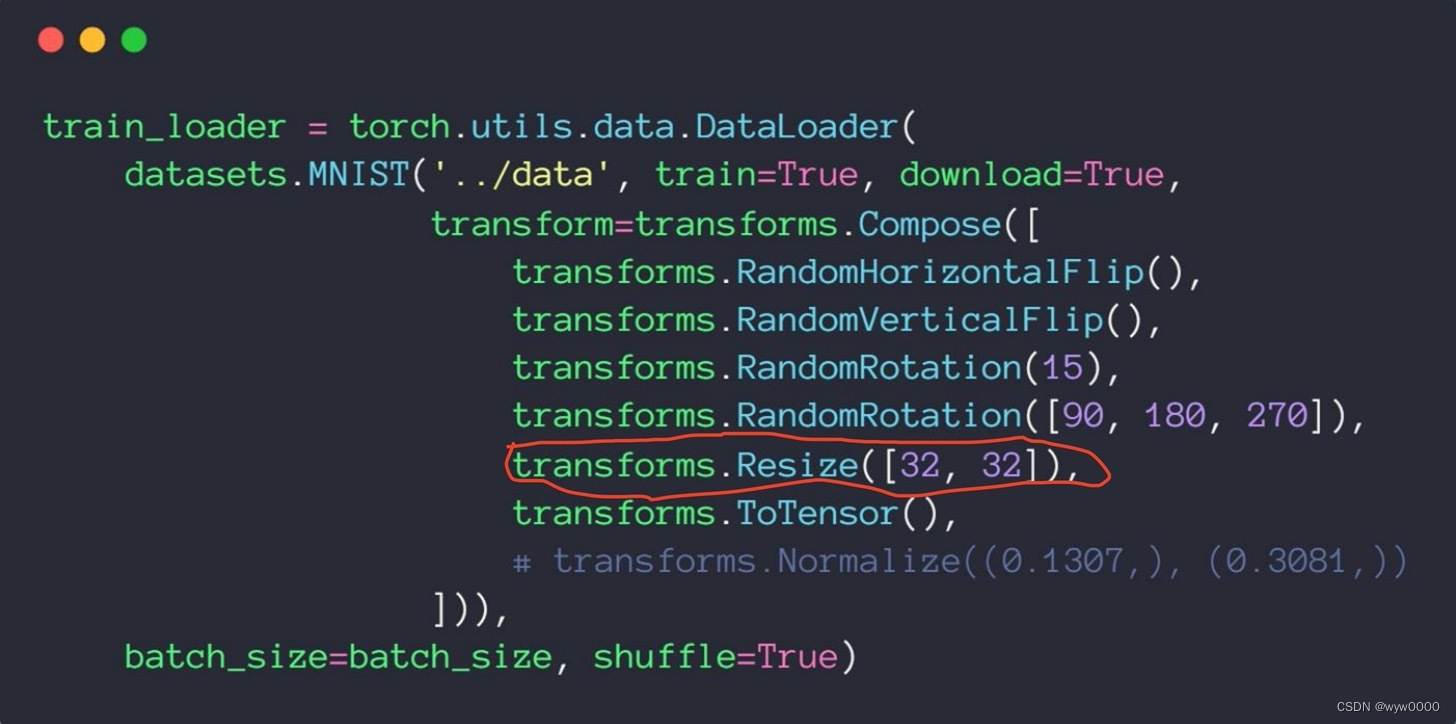
缩放通过Resize函数实现,注意传入参数宽高为list类型
4. crop裁剪


上图中的RandomCrop就是随机裁剪方法,一般与RandomRotation一起使用。
transforms.Compose类似nn.Sequential,是将各种操作打包成一个操作
5. 总结
数据增加理论上可以扩充出无数张图片数据,但是如果原数据集比较小的话,也不会得到很好的效果,只能改善一些,意思就是说数据增加对机器学习改善比较有限。
6. 完整代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(15),
transforms.RandomRotation([90, 180, 270]),
transforms.Resize([32, 32]),
transforms.RandomCrop([28, 28]),
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))