有一个Task OOM:
-
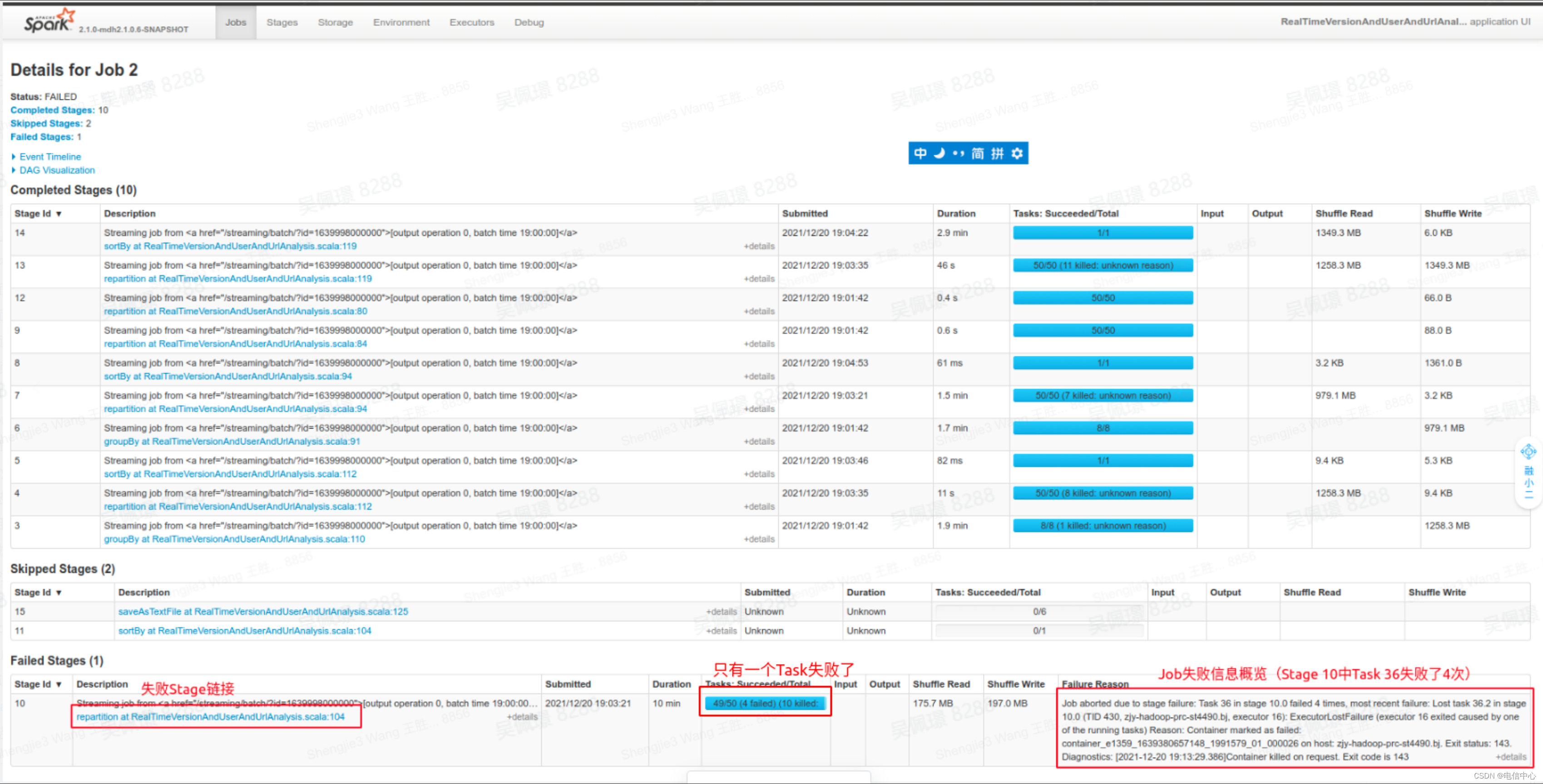
通过概览信息,发现Stage 10的Task 36失败了4次导致Job失败。概览信息中显示最后一次失败的退出代码(exit code)是143 ,意味着发生了内存溢出(OOM,即Out of Memory)。
可以点击Stage链接,查看为什么导致了Executor OOM(Out of Memory)。
-
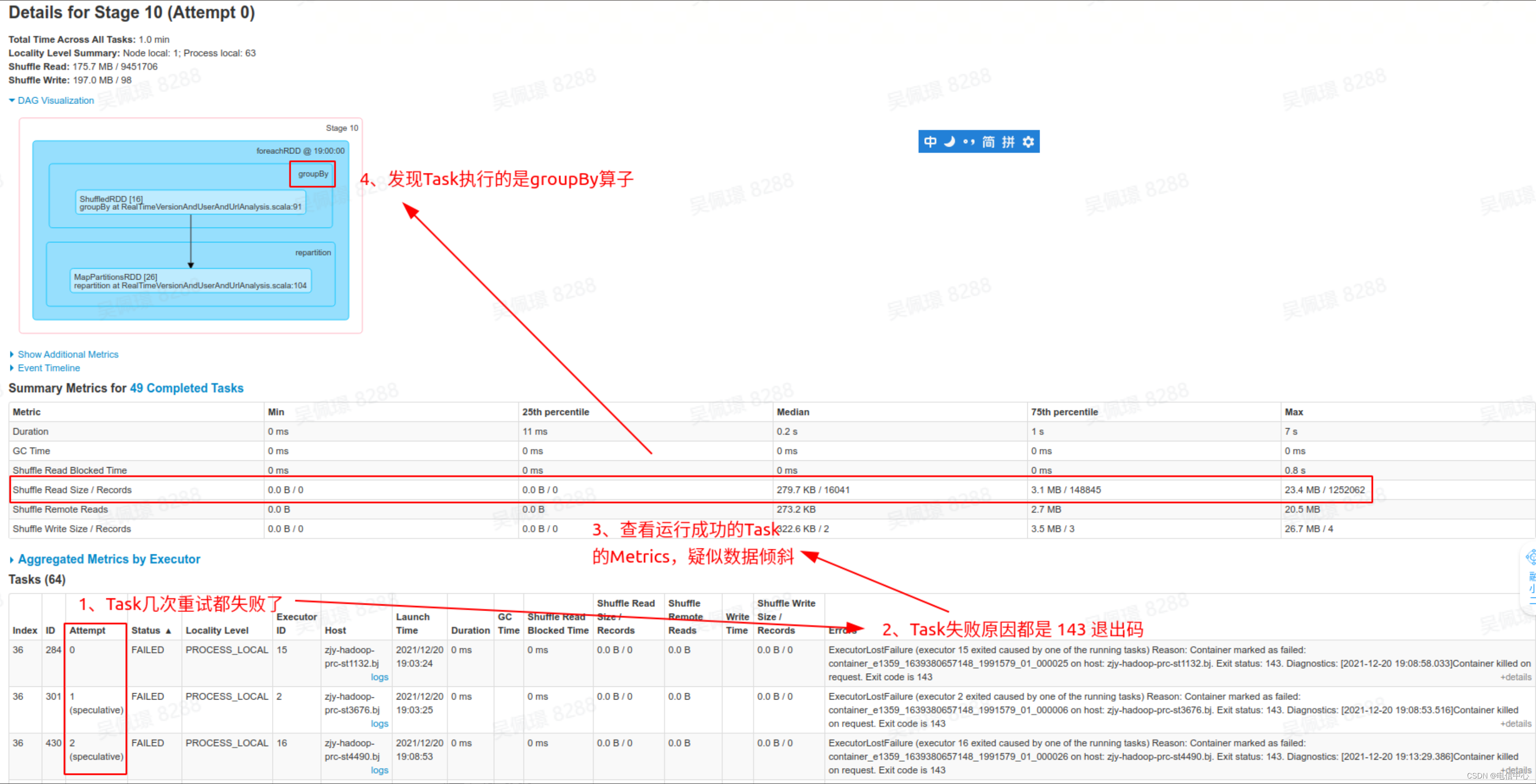
通过上述图片发现,大部分Task都成功了,只有一个失败了,这高度怀疑是数据倾斜问题。
- 如果是Driver逻辑失败导致App失败(例如输入路径不存在、Driver OOM等),应直接查看Driver日志。
- 如果Driver OOM,可能需要查看Yarn UI。
-
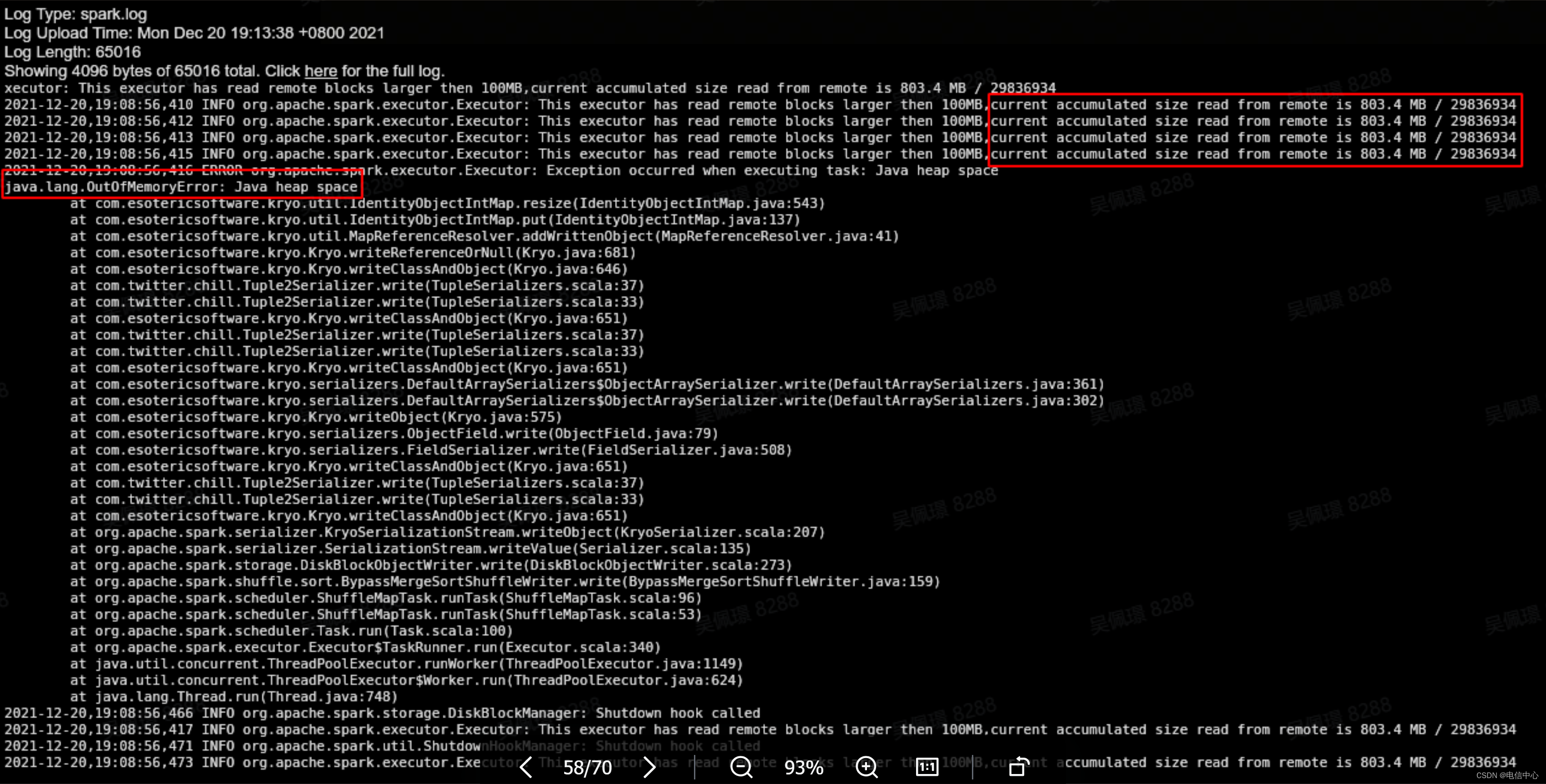
通过Task日志进一步确认,发现日志中打印的这个Task拉取远程的Shuffle数据远超过上述成功的Task的最大值。明确失败原因为数据倾斜。
Driver fail
-
Driver逻辑导致失败的可能原因包括:
- 路径没有权限
- 读取路径为空
- SparkContext初始化失败
- 作业代码自己抛出异常等
-
首先,Spark UI上没有显示失败的Job。
转而查看Driver log:
可以从Driver日志中看到访问目录没有权限:
