论文:https://arxiv.org/abs/2310.04672
文章目录
- 摘要
- Introduction
- [Training Process](#Training Process)
- [3 推理过程](#3 推理过程)
-
- [3.1 面部预处理](#3.1 面部预处理)
- [3.3 第二扩散阶段](#3.3 第二扩散阶段)
- [3.4 多用户ID](#3.4 多用户ID)
- [4 任意ID](#4 任意ID)
- [5 实验](#5 实验)
- [6 结论](#6 结论)
下篇文章进行实战。
摘要
稳定扩散Web UI(Stable Diffusion Web UI,简称SD-WebUI)是一个综合项目,它基于Gradio库为稳定扩散模型提供了一个浏览器界面。本文提出了一款新颖的WebUI插件------EasyPhoto,旨在实现AI人像生成。通过使用5到20张相关图片对特定用户ID的数字替身进行训练,根据训练得到的LoRA模型进行微调后,该模型能够利用任意模板生成AI照片。当前实现支持多人的修改及不同照片风格的应用。此外,我们允许用户利用强大的SDXL模型生成奇幻的模板图像,从而增强EasyPhoto生成结果的多样性和满意度。EasyPhoto的源代码可于sd-webui-EasyPhoto获取。我们正持续努力拓展EasyPhoto的工作流程,使其适用于任何识别需求(不仅限于面部),并热烈欢迎各种有趣的想法或建议。
Introduction
Stable Diffusion (Rombach et al., 2021)确实是一种流行的基于扩散的生成模型,广泛用于根据文本描述生成逼真的图像。它在诸如图像对图像翻译、图像修补、图像外延等各个领域都有应用。
与其他模型如DALL-E 2和Midjourney 3不同,Stable Diffusion是开源的,这使得它非常灵活,便于进一步开发。Stable Diffusion最著名的应用之一是Stable Diffusion web UI。它包括一个浏览器界面,建立在Gradio库上,为Stable Diffusion模型(SD模型)提供了用户友好的界面。它集成了各种SD应用程序、预处理函数,以增强图像生成的可用性和控制性。
由于SD-WebUI的便利,我们开发了EasyPhoto作为一个WebUI插件来生成AI肖像。与现有方法不同,可能引入不真实的光照或遭受身份丢失的困扰,EasyPhoto利用了SD模型的图像对图像能力来确保真实和准确的结果。EasyPhoto可以轻松安装为WebUI的扩展,使其用户友好且适用于广泛的用户。通过利用SD模型的力量,EasyPhoto使用户能够生成高质量、以身份为导向的AI肖像,这些肖像与输入身份密切相似。
首先,我们允许用户上传几张图像来在线训练一个面部LoRA模型作为用户的数字替身。LoRA(低秩适应(Hu et al., 2022))模型使用低秩适应技术进行训练,以快速微调扩散模型,使基础模型能够理解特定用户ID信息。然后,这些训练好的模型被整合并合并到基础SD模型中进行推理。
在推理阶段,我们打算通过稳定扩散模型重新绘制推理模板中的面部区域。使用了几个ControlNet(Zhang et al.)单元来验证输入和输出图像之间的相似性。为了克服诸如身份丢失和边界伪影等问题,采用了两阶段扩散过程。这确保了生成的图像保持用户的身份,同时最小化视觉上的不一致性。此外,我们认为推理管道不仅限于面部,还可以扩展到与用户ID有关的任何事物。这意味着一旦我们训练了一个ID的LoRA模型,我们就可以生成各种AI照片。它可以用于各种应用,例如虚拟试穿。我们正在不断努力实现更加真实的结果。
- 我们提出了一种新颖的方法来训练EasyPhoto中的LoRA模型,即集成多个LoRA模型以保持生成结果的面部保真度。
- 我们结合强化学习方法来优化LoRA模型以获得面部身份奖励,从而进一步提高生成结果与训练图像之间的身份相似性。
- 我们在EasyPhoto中提出了一个两阶段修补式扩散过程,旨在生成具有高相似度和美学的AI照片。图像预处理经过深思熟虑地设计,为ControlNet创建适当的指导。EasyPhoto使用户能够获得具有各种风格或多个个体的个性化AI肖像。此外,我们利用强大的SDXL模型生成模板,从而产生各种多样且逼真的输出。
Training Process
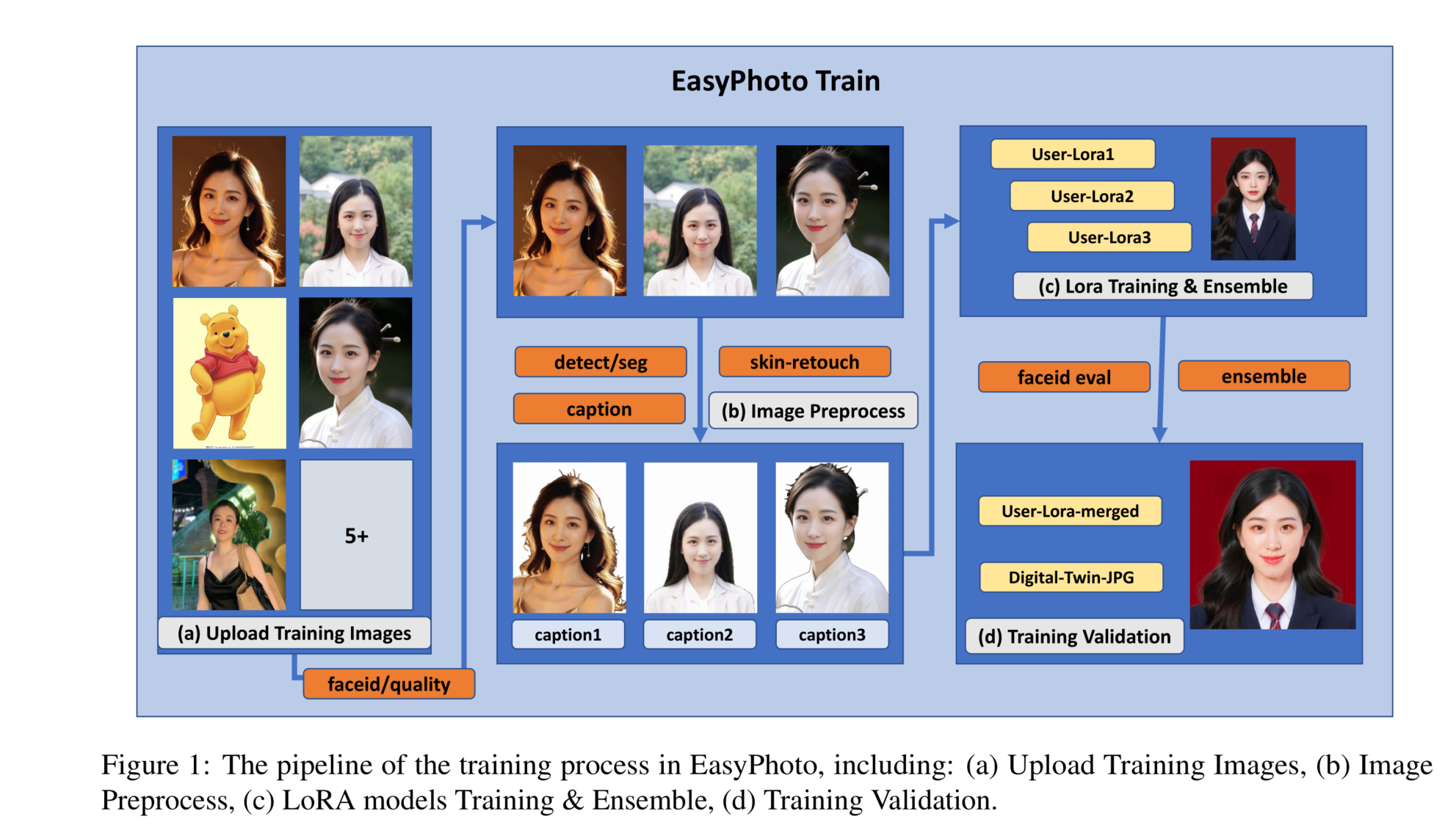
EasyPhoto的训练过程流程如图1所示。
首先,我们对输入的用户图像进行人脸检测(Serengil和Ozpinar,2020年,2021年),以确定人脸的位置。一旦检测到人脸,根据特定比例裁剪输入图像,只关注人脸区域。然后,利用显著性检测模型4(Qin等人,2020年)和皮肤美化模型5(Lei等人,2022年)获取干净的人脸训练图像。这些模型有助于增强人脸的视觉质量,并确保所得的训练图像主要包含人脸(即,背景信息已被移除)。输入提示被固定为"easyphoto_face,easyphoto,1person"。实验表明,即使使用固定的输入提示,训练的LoRA模型也可以令人满意。最后,使用这些处理过的图像和输入提示来训练LoRA模型,使其能够有效地理解用户特定的面部特征。
在训练过程中,我们引入了一个关键的验证步骤,即计算验证图像(由训练好的LoRA模型和基于训练模板的Canny控制网络生成的图像)与用户图像之间的人脸id差距。这个验证过程对于实现LoRA模型的融合至关重要,最终确保训练好的LoRA模型成为用户高度准确的数字化表示,或者说用户的"替身"。此外,具有最佳人脸id分数的验证图像将被选择为人脸id图像,该图像将用于增强推理生成的身份相似性。
基于模型集成过程,LoRA模型使用最大似然估计作为目标进行训练,而下游目标是保持面部身份相似性。为了弥补这一差距,我们利用强化学习技术直接优化下游目标。具体而言,我们将奖励模型定义为训练图像与LoRA模型生成结果之间的面部身份相似性。我们使用DDPO(Black等人,2023年)来微调LoRA模型,以最大化这一奖励。因此,LoRA模型学习的面部特征得到了改善,导致模板生成的结果与模板之间的相似性得到了提高,并展示了它们在不同模板之间的普适性。
基于模型集成过程,LoRA模型使用最大似然估计作为目标进行训练,而下游目标是保持面部身份相似性。为了弥合这一差距,我们利用强化学习技术直接优化下游目标。具体而言,我们将奖励模型定义为LoRA模型生成结果与训练图像之间的面部身份相似性。我们采用DDPO(Black等人,2023年)来微调LoRA模型,以最大化这一奖励。因此,LoRA模型学到的面部特征得到了改进,从而提高了模板生成结果之间的相似性,并展示了它们在不同模板之间的通用性。
3 推理过程
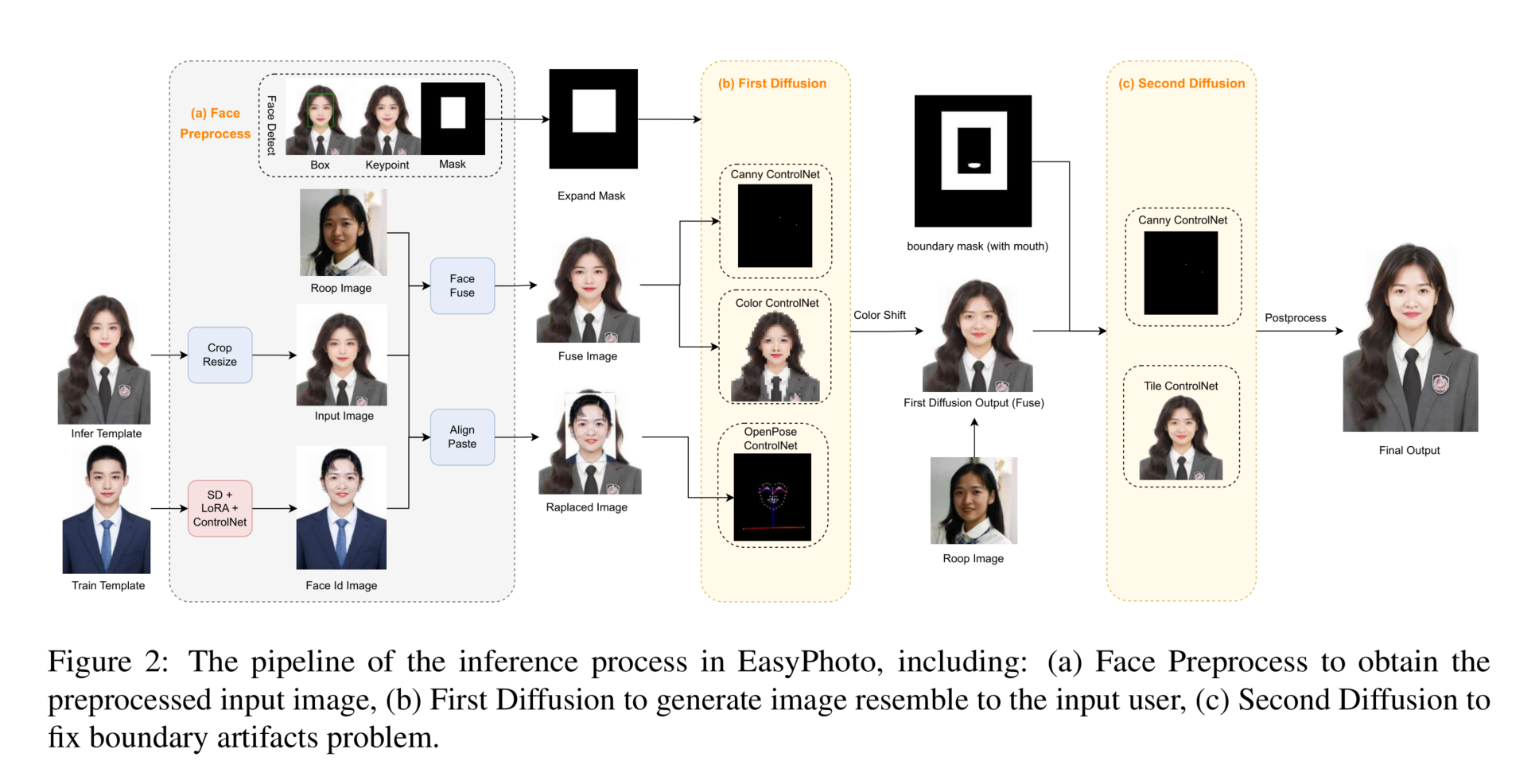
在EasyPhoto中,单个用户ID的推理过程如图2所示。它包括三个部分,(a)面部预处理以获取预处理的输入图像和ControlNet参考,(b)第一扩散以生成类似于用户输入的粗略结果,(c)第二扩散以修复使结果更真实的边界伪影。它以推理模板和面部ID图像作为输入,该图像是在训练验证中具有最佳面部ID分数时生成的。结果是输入用户的高度详细的AI肖像,与用户的独特外观和身份密切相似,基于推理模板。我们将在本节中详细说明每个过程。
3.1 面部预处理
基于推理模板生成AI肖像的直观方法是使用SD模型(经过LoRA微调)对模板的面部区域进行修补。此外,将ControlNet纳入此过程可以显著增强生成图像中用户身份和相似性的保留。然而,直接将ControlNet应用于修补区域可能会引入潜在的伪影或问题,其中包括:
- 模板图像与输入图像之间的不一致性。显然,模板图像中的关键点与面部ID图像的关键点不兼容。因此,将面部ID图像作为ControlNet的参考将不可避免地导致最终结果的不一致性。
- 修补区域的缺陷。对区域进行掩模并用新的面孔修补它将导致明显的缺陷,特别是沿着修补边界。这将对生成的结果的逼真度和真实性产生负面影响。
- ControlNet导致的身份丢失。由于ControlNet在训练过程中未被使用,在推理过程中纳入ControlNet可能会损害训练后的LoRA模型保留输入用户ID身份的能力。
为了解决上述问题,我们提出了三个面部预处理过程,以获取第一扩散阶段的输入图像、掩模和参考图像。
-
对齐与粘贴。为了解决模板和面部ID之间的面部关键点不匹配的问题,我们提出了一个仿射变换和面部粘贴算法。首先,我们计算模板图像和面部ID图像的面部关键点。接下来,我们确定所需的仿射变换矩阵M,将面部ID图像的面部关键点与模板图像的关键点对齐。然后,我们直接将这个矩阵M应用于将面部ID图像粘贴到模板图像上。生成的替换图像保留了与面部ID图像相同的关键点,同时与模板图像对齐。因此,使用这个替换图像作为OpenPose ControlNet的参考,可以确保同时保留面部身份和面部ID图像以及模板图像的面部结构。
-
面部融合。为了纠正掩模修补引起的边界伪影,我们提出了一种新颖的方法,即通过使用Canny ControlNet进行伪影矫正。这使我们能够引导图像生成过程,并确保保持和谐的边缘。然而,模板脸部的Canny边缘与目标ID之间可能存在兼容性问题。为了克服这一挑战,我们采用FaceFusion 6算法来融合模板和roop图像(地面实况用户图像之一)。通过融合图像,生成的融合输入图像展现了所有边界边缘的改进稳定性,从而在第一扩散阶段取得更好的结果。这种方法有助于缓解边界伪影,提高生成图像的整体质量。
-
基于ControlNet的验证。由于LoRA模型在没有ControlNet的情况下进行了训练,在推理过程中使用ControlNet可能会影响LoRA模型的身份保留。为了解决这个问题,我们引入了在训练流程中使用ControlNet进行验证的方法。验证图像是通过将LoRA模型和ControlNet模型应用于标准训练模板来生成的。然后,我们比较验证图像和相应训练图像之间的面部ID分数,以有效地整合LoRA模型。通过整合不同阶段的模型并考虑ControlNet的影响,我们大幅增强了模型的泛化能力。这种基于验证的方法确保了改进的身份保留,并促进了在模型推理过程中ControlNet的无缝集成。
第一扩散
第一扩散阶段旨在基于模板图像生成具有特定ID(类似于输入用户ID)的图像。输入图像是模板图像和用户图像的融合,而输入掩模是模板图像的校准面部掩模(扩展以包括耳朵)。
为了增强对图像生成过程的控制,集成了三个ControlNet单元。第一个单元专注于对融合图像的Canny控制。通过利用融合图像作为Canny边缘的参考,实现了模板和面部ID图像的更精确的整合。与原始模板图像相比,融合图像自然地提前将ID信息组合在一起,从而使边界伪影最小化。第二个ControlNet单元是对融合图像的颜色控制。它验证了修补区域内的颜色分布,确保一致性和连贯性。第三个ControlNet单元是对替换图像的openpose控制,其中包含用户的面部身份和模板图像的面部结构。这保证了生成图像的相似性和稳定性。通过这些ControlNet单元的整合,第一扩散过程可以成功生成一个与用户指定的ID密切相似的高保真度结果。
3.3 第二扩散阶段
第二扩散阶段致力于微调和精细化靠近面部边界的伪影。此外,我们提供了掩盖口部区域的选项,以增强该特定区域内的生成效果。与第一扩散阶段类似,我们将用户图像(roop图像)的结果与第一扩散阶段的输出图像融合,以获取第二扩散阶段的输入图像。这个融合图像也作为Canny ControlNet的参考,使得对生成过程有更好的控制。此外,我们还加入了瓷片ControlNet,以在最终输出中实现更高的分辨率。增强细节和生成图像整体质量有益。
在最后一步,我们对生成的图像进行后处理,将其调整为与推理模板相同的大小。这确保了生成图像与模板之间的一致性和兼容性。此外,我们还应用了皮肤修饰算法(Lei等人,2022年)和肖像增强算法(Tao Yang和张,2021年)来进一步提高最终结果的质量和外观。这些算法有助于精细化皮肤纹理和整体视觉吸引力,从而产生更好、更精致的图像。
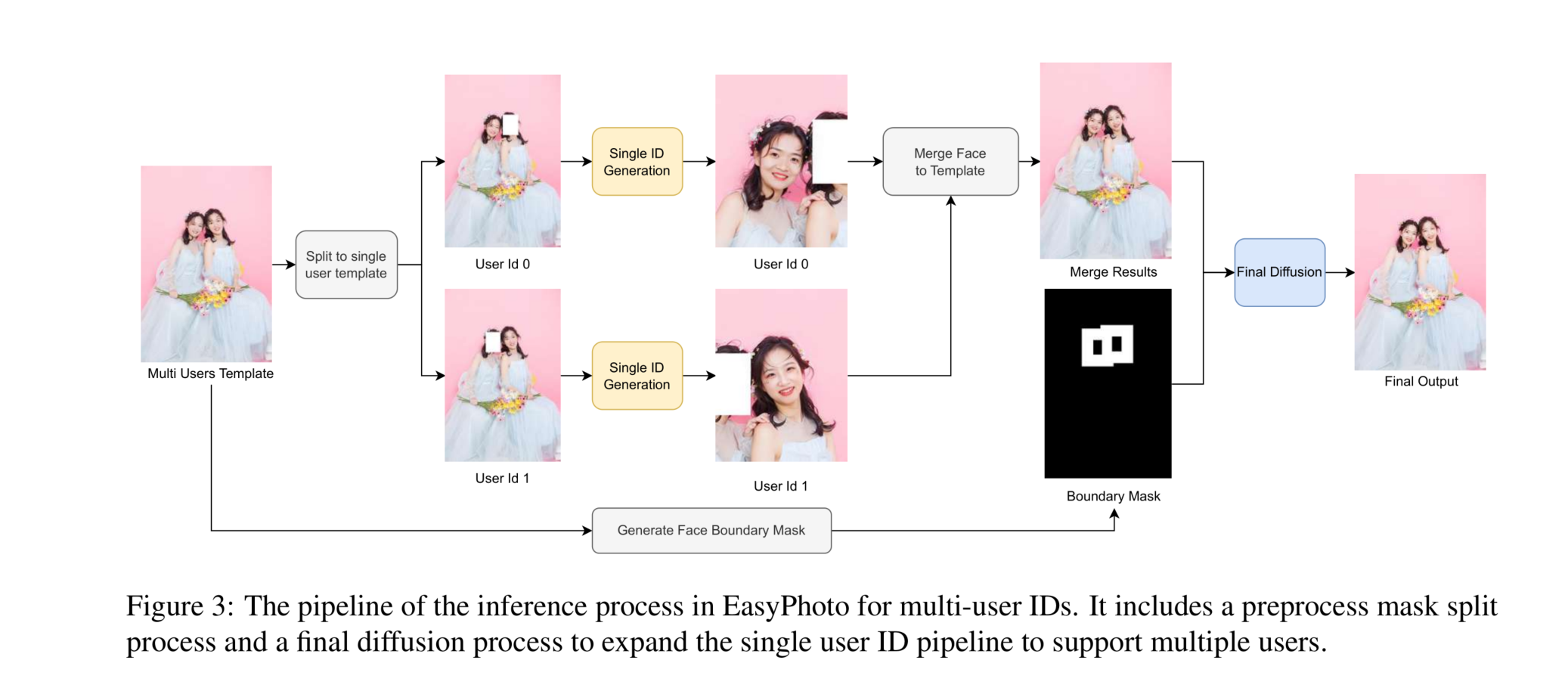
3.4 多用户ID
EasyPhoto还支持多个用户ID的生成,这是单个用户ID生成过程的扩展,如图3所示。
为了实现这一点,我们首先对推理模板进行人脸检测。然后,模板被分割成几个掩模,每个掩模只包含一个面部,而图像的其余部分被掩膜掩盖成白色。这将任务简化为单个单用户ID生成问题。一旦用户ID图像生成,它们就会合并回推理模板中。为了解决在合并过程中可能出现的边界伪影,我们采用了基于扩散的图像修补技术,借助面部边界掩模。这有助于将生成的图像与模板图像无缝融合,产生高质量的集体照片。
4 任意ID
我们目前正在扩展EasyPhoto流水线,以适应任意ID。这意味着用户将能够为任何特定ID(包括目标对象的几个训练图像)训练一个LoRA模型,并利用训练好的模型生成该特定ID。与广泛研究的人脸相关任务不同,例如人脸检测和关键点检测,对于一般对象替换,存在有限的现有研究。主要挑战在于为替换过程生成一个合适的ControlNet参考。幸运的是,随着SAM(Kirillov等人,2023年)、LightGlue(Lindenberger等人,2023年)和Grounding Dino(Liu等人,2023年)等强大的通用模型的出现,定位和匹配一般关键对象变得可行。我们正在积极努力更新EasyPhoto以支持任意ID的生成,并将很快发布代码。
5 实验
在本节中,我们展示了EasyPhoto的一些生成结果,如图4至图7所示。EasyPhoto现在赋予用户生成具有各种风格的AI肖像、使用提供的模板生成多个用户ID,甚至使用SD模型生成模板的能力(也支持SDXL)。这些结果展示了EasyPhoto在生成高质量和多样化的AI照片方面的能力。
要自己尝试EasyPhoto,您可以在SD-WebUI中安装它作为扩展程序,或者使用PAI-DSW在短短3分钟内启动EasyPhoto。有关更详细的信息,您可以参考我们的存储库。



6 结论
在本文中,我们介绍了EasyPhoto,这是一个用于生成AI照片的WebUI插件。我们的方法利用了基本稳定扩散模型以及用户训练的LoRA模型,能够产生高质量且视觉上类似于照片的结果。该模型包括面部预处理技术和两个基于修补的扩散过程,以解决身份丢失和边界伪影的问题。值得注意的是,EasyPhoto现在允许用户生成带有多个用户的AI照片,并提供了选择不同风格的灵活性。SDXL模型也被采用以生成更真实和多样化的推理模板。在未来,我们将通过引入"任意ID"的概念来扩展所提出的算法。这意味着人脸预处理过程也可以应用于使用强大的通用模型的任何对象区域。我们正在积极努力使代码公开可用,以便无缝集成到EasyPhoto中。