针对导出数据库表结构通常有 3 种方法:
使用 DTS 导出
打开 DTS 迁移工具,选择【DM-->SQL】并链接到数据库中,如下图所示:

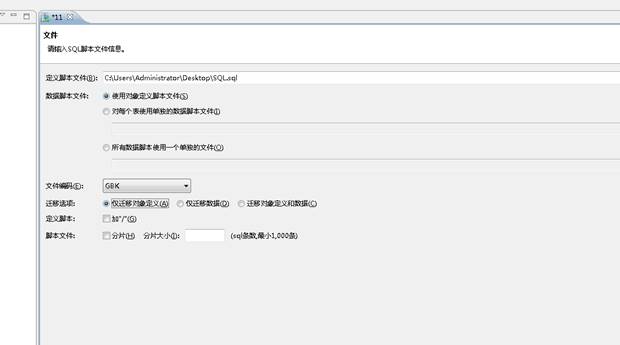
添加定义脚本,并选择【迁移范围】(仅迁移对象定义),如下图所示:
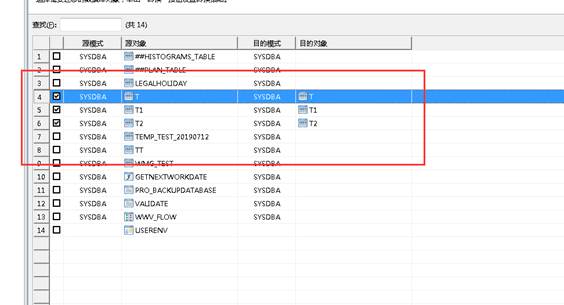
选择需要导出结构的表,如下图所示:
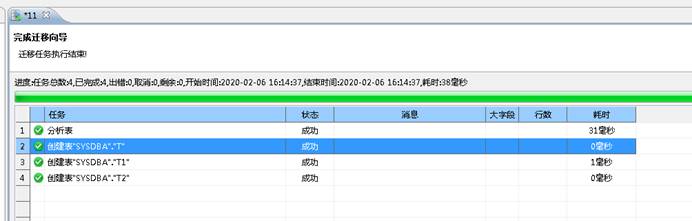
迁移完成,表结构已经导出,如下图所示:
DTS 同样可以将表结构迁移至其他数据库中或者从其他数据库迁移至 DM 数据库中。
使用 DMP 方式导出
打开 manager.exe,DM 管理工具链接至数据库中,如下图所示:
右键选择你想要导出的模式,点击【导出】,如下图所示:如下图所示:
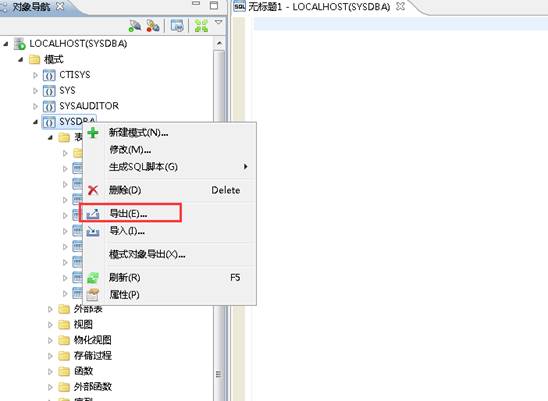
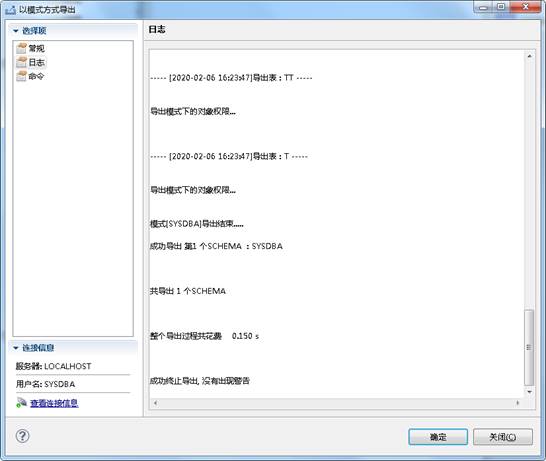
勾选掉数据行选项,点击【确定】完成导出,如下图所示:

完成导出,包含表结构的 DMP 文件生成,如下图所示:
使 Disql 命令行方式导出
参考《DM_dexp 和 dimp 使用手册》(手册位于数据库安装路径 /dmdbms/doc/special 文件夹下)。-dexp 参数 -ROWS- 导出数据行 - 改为 ROWS=N。
CopySELECT DBMS_METADATA.GET_DDL('TABLE',表名,模式名);//参考 DBMS_METADATA 系统包
CALL SP_TABLEDEF('模式名', '表名');//SQL 语句调用系统过程 SP_TABLEDEF可以通过 SP_TABLEDEF 系统过程查看表的定义。
6092 数据大小已超过可支持范围
- 方法一
一般情况下,此问题由于实际数据超过了 DM 数据库支持的大小范围,重点分析被迁移数据的数字类型字段 (INT、BIGINT、NUMBER),找到造成引起报错的字段后,观察数据可以考虑将字段改为 BIGINT 或者 VARCHAR 字符字段以规避错误。
各数据类型范围详情可以参考《DM_SQL 语言使用手册》第一章 1.4.1 节内容(手册位于数据库安装路径 /dmdbms/doc 文件夹下)。
CopyINTEGER 类型:-2147483648 (-2^31)~ +2147483647(2^31-1)。
BIGINT 类型: -9223372036854775808(-2^63)~9223372036854775807(2^63-1)。- 方法二
默认 8 KB 的页大小情况下,字符类型无法创建超过 3900 长度的表。需要重新初始化数据库实例,对页大小进行调整。需要注意的是:这个限制长度只针对建表的情况,在定义变量的时候,可以不受这个限制长度的限制。
| 页大小 | 字符类型实际最大长度 |
|---|---|
| 4k | 1900 |
| 8k | 3900 |
| 16k | 8000 |
| 32k | 8188 |
两个建库参数有影响,一个字符集,一个"长度以字符为单位"。
比如 Oracle 中的 nvarchar2(50) 这个类型,表示该字段类型为 nvarchar2,长度为 50,不论英文、数字、中文都能存 50 个。在 DM 数据库中,如果长度以字符为单位这个参数建库的时候选了否,UNICODE 字符集,nvarchar2(50) 还是只能存 16 个中文。
- 方法三
在有表结构的基础上,将报错的表【启用超长记录】打开。
如何使用管理工具导入 SQL 数据
- 方法一
将将 SQL 语句粘贴到查询窗口,然后执行。这种方式适合 SQL 不多的情况下使用,如果 SQL 比较多,比如几万条,那么在复制粘贴的时候就会受性能影响了,可能会导致管理工具卡死。
- 方法二
将 SQL 保存到 SQL 类型的文件中,然后用管理工具打开 SQL 文件,如下图所示:
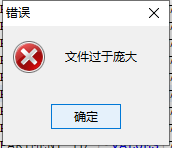
这种方式也相对简单,但是如果文件大小不能超过 20 MB,当超过 20 MB 时会报 文件过于庞大 错误,如下图所示:
- 方法三
使用管理工具的【执行脚本】功能,如下图所示:

这种方式适合导入比较大的脚本,测试导入 3.42 GB 的 SQL 也是可以的,但还是不建议直接这样导入很大的 SQL,如果不能及时提交会使用大量的内存资源。
另外:如果要导入比较大的 SQL 还可以考虑使用迁移工具将数据 SQL 导入 DM 数据库,使用迁移工具还可以设置一次性提交的语句条数和缓存批次,这样可以提高数据导入的效率。


DM 如何导出数据为 SQL 格式
无论使用"管理工具"还是"迁移工具"都可以远程连接数据库进行操作,所以只要本机安装 DM 数据库客户端即可操作,不需要登录服务器本机操作。
- 使用管理工具
方法一:
使用生成 SQL 脚本方式生成建表语句,并保存为 SQL 文件,或直接生成文件,如下图所示:


方法二:
查看表属性中的 DDL,复制语句并保存为 SQL 文件,如下图所示:

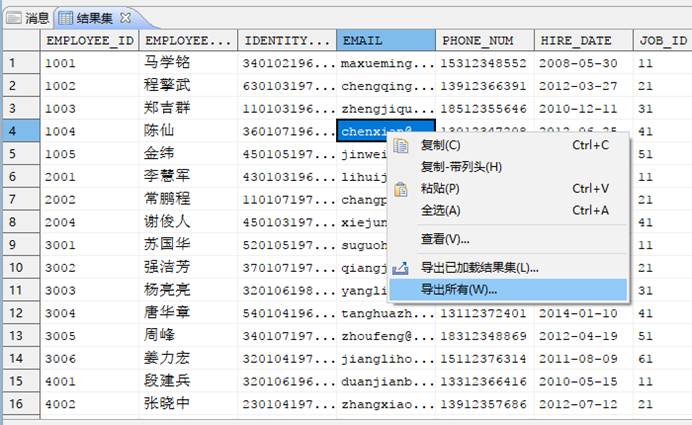
导出数据,此方法在数据量不大的情况下可以使用。查询出表数据,在结果中右键选择【导出所有】,选路径然后选要保存的类型为 SQL 并输入文件名。如下图所示:

方法三:
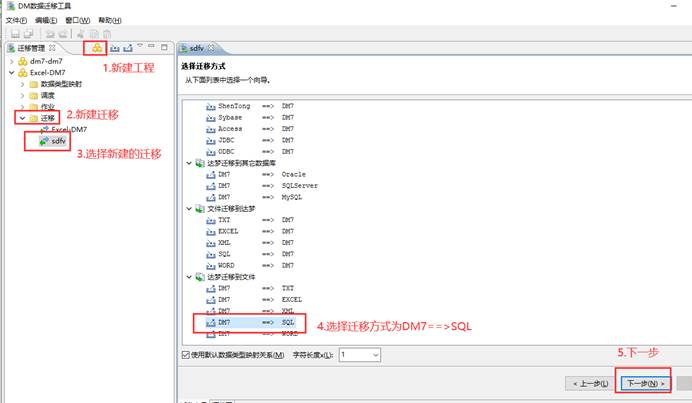
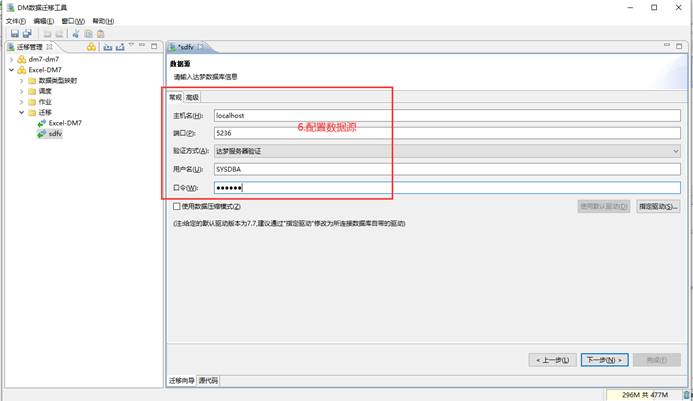
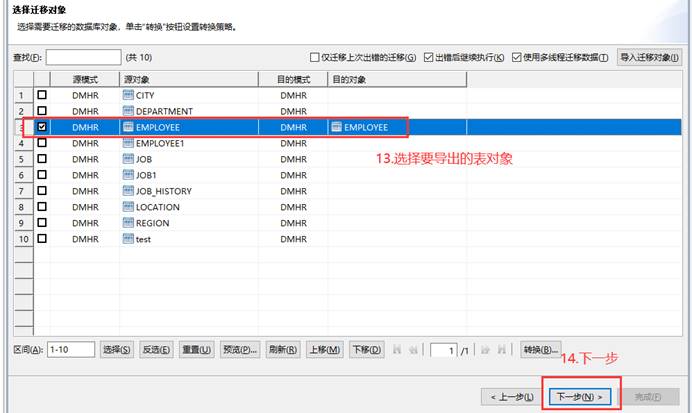
使用 DM 数据迁移工具 DTS。该方法适合导出比较大的表,如下图所示:


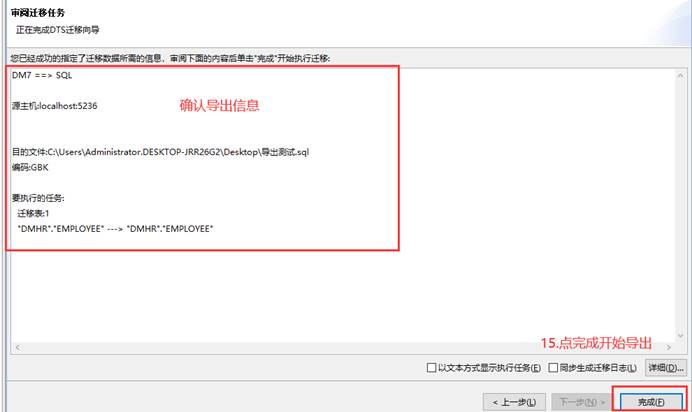
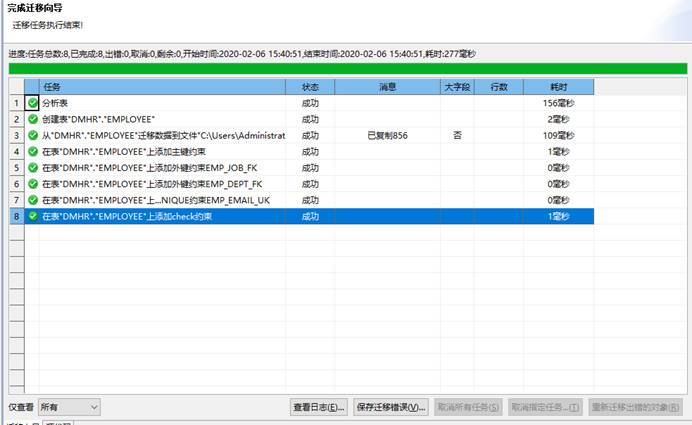
迁移过程和结束会显示迁移的情况,如有错误可以点击【查看日志】和【重新迁移出错对象】,有报错时在列表中也可以点击查看具体的报错信息。
将 Excel 数据导入 DM
DM 提供了两种方法导入 Excel 数据。
方法一: DTS 工具导入
使用 DM 数据迁移工具 DTS(以下简称"DTS")可将不同数据或数据类型的文件数据导入到 DM 数据库中,其中 Excel 就可以使用迁移工具进行导入。
无论 Windows 或 Linux,在安装好 DM 数据库后,都会在安装后的 dmdbms/tool 目录下安装一系列的客户端工具,如 Windows 下迁移工具名称为 dts.exe,如下图所示:

如果试用图形化安装的 DM 数据库,同时会桌面或开始菜单生产一个【达梦数据库】的文件夹,可以在文件夹中快速的启动【DM 数据迁移工具】,如下图所示:
- 如何使用迁移工具导入 Excel
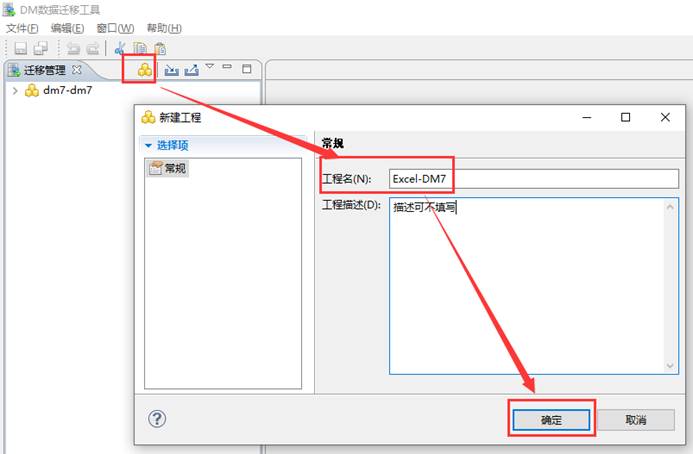
打开迁移工具,点击【新建工程】按钮,新建工程,如下图所示:
展开新建的工程,选择【迁移】-点击【新建迁移】,如下图所示:

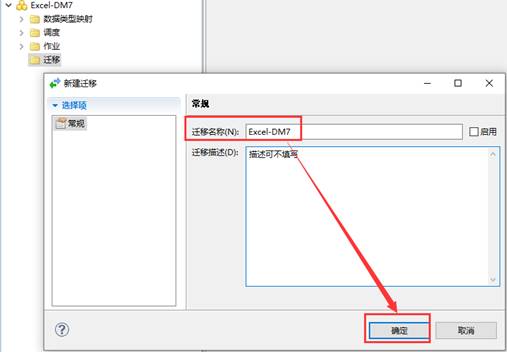
开始配置迁移(导入)Excel 数据,点击【下一步】,如下图所示:
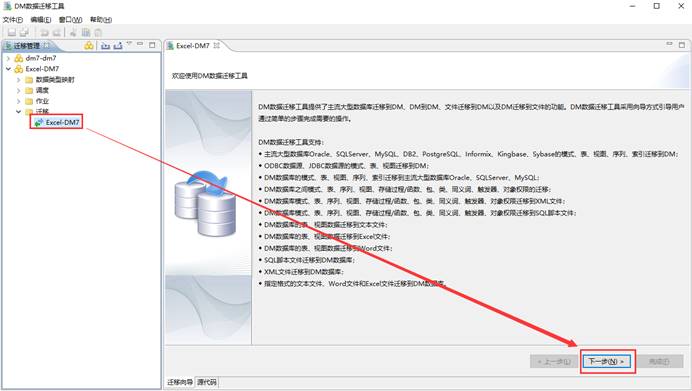
在列表中选择【文件迁移到达梦】中【Excel-->DM】,如下图所示:
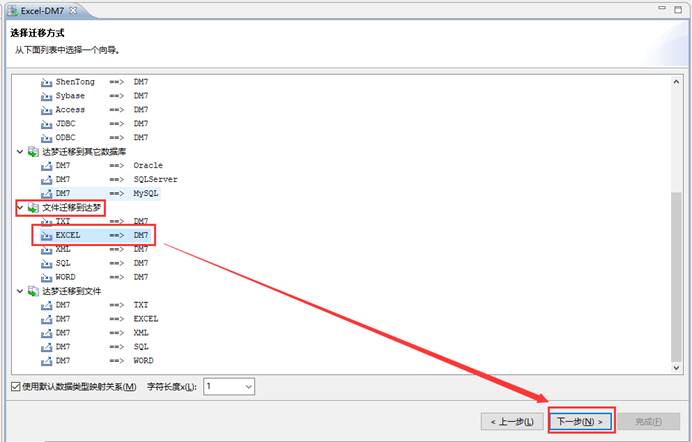
选择要导入的 Excel 文件,如下图所示:
注意:选择数据读取方式时,要考虑 Excel 文件首行是否为列名。
(1)如果 Excel 文件中第一行为列名,则选择"按照设定的数据格式读取"。
(2)如 Excel 文件中第一行不是列名,则选择"全部按字符集读取",但是需要注意 Excel 文件中每列的数据要与表中的列一一对应,否则会报错。建议在 Excel 表中添加第一行作为列名。

配置要导入的目的端数据库,如下图所示:
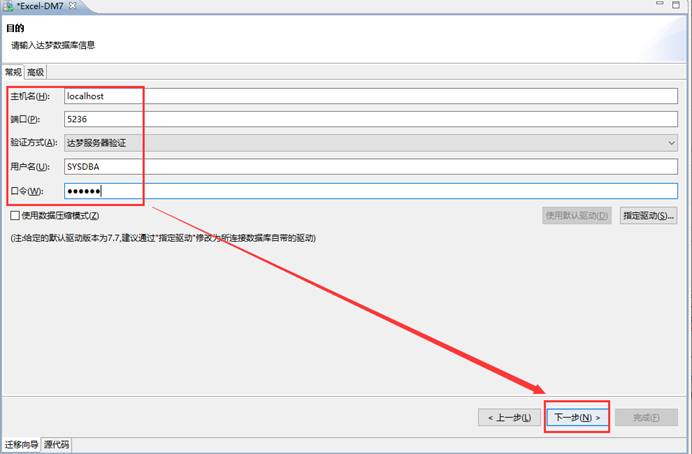
选择要导入到的模式,如下图所示:
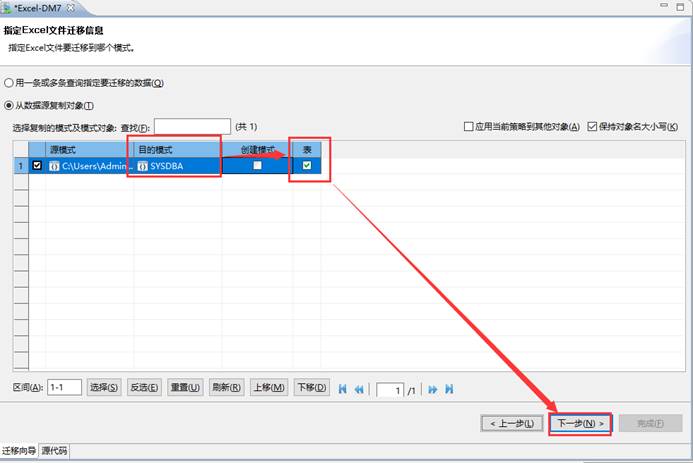
选择要导入的模式对应的目的表,如果有没有新建,可输入表名,导入过程中会自动创建相应的表,如下图所示:
需要注意:
(1)如果 Excel 中第一行作为列名,列名大小写与数据库表中列名大小写完全相同,则迁移工具会自动匹配相同列名。可以在右下方"转换"--"列映射选项"查看;
(2)如果 Excel 中第一行作为列名,列名大小写与数据库表中列名大小写不相同或者不完全相同,则需要在右下方"转换"--"列映射选项"中手动进行映射匹配。
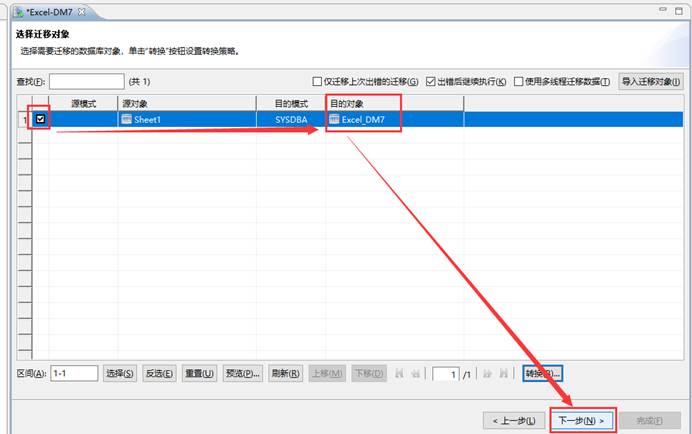
点击【完成】开始迁移,如下图所示:
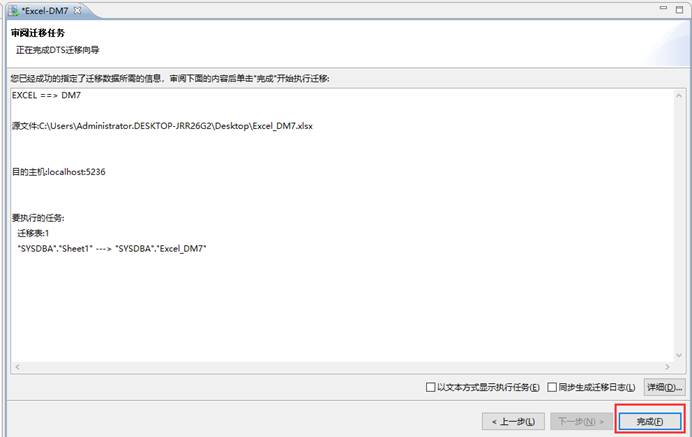
完成迁移,如下图所示:
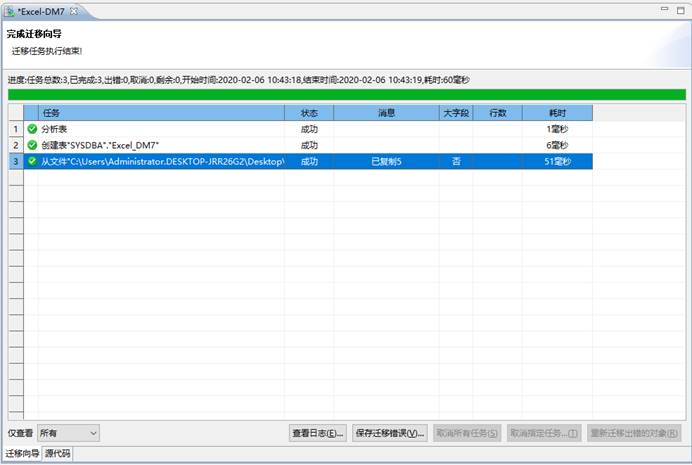
检查数据,如下图所示:
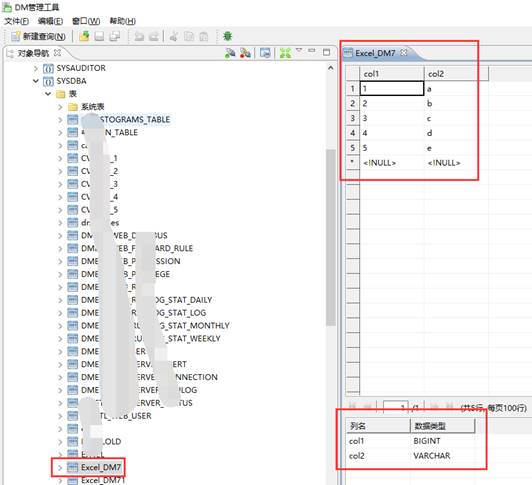
至此,数据已经导入到 DM 数据库中了,如果需要设置导入的列的数据类型,可以在导入前先将对应的数据表进行创建,然后再导入过程中的【目的对象】输入表名即可。
同样的,还可以将不同类型的数据库(如 Oracle、DB2、MySQL 等)和文件(如 TXT、XML 等)数据导入到 DM 数据库中。另外达梦公司还有 DMETL 软件,也可以通过 DMETL 进行导入,此处不进行详细介绍。
方法二: DMFLDR 工具导入
使用 dmfldr 工具无法直接将 excel 文件导入到数据库表中,需要将 excel 文件转换为 csv 格式,如果出现中文乱码,可以使用 Windows 记事本等工具将文件编码改为 UTF-8。转换为 CSV 格式之后,CSV 格式默认每列以逗号','分割,文件内容如下:
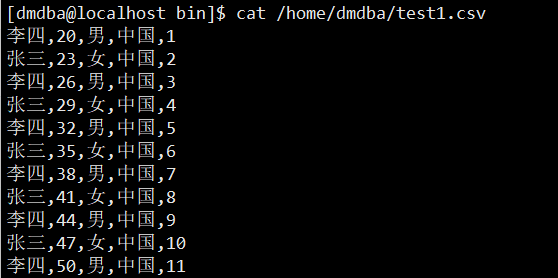
需要注意:Windows 上的 excel 或者 csv 文件拷贝到 Linux 上之后,Windows 格式的空格会变为"^M",需要在 vim 中使用 set ff=unix 将文件格式修改为 unix 格式。
DMFLDR 工具导入具体步骤如下:
创建表:
CopyCREATE TABLE TEST1
(ID INT ,
NAME VARCHAR(100),
SEX VARCHAR(3),
AGE NUMBER,
ADDR VARCHAR(100));使用 DMFLDR 将 CSV 文件内容装载到表中,创建 dmfldr 控制文件:
Copy[dmdba@localhost bin]$ cat /home/dmdba/test1.ctl
OPTIONS
(
SKIP = 0
ROWS = 50000
DIRECT = TRUE
INDEX_OPTION = 2
CHARACTER_CODE='UTF-8' /*指定数据文件中数据的编码格式,即下面的test1.csv中数据的编码格式*/
)
LOAD DATA
INFILE '/home/dmdba/test1.csv'
BADFILE '/home/dmdba/test1.bad'
INTO TABLE test1
FIELDS ',' /*下面列名与csv文件中对应数据相匹配,否则会报错*/
(NAME,
AGE,
SEX,
ADDR,
ID
)使用 dmfldr 装载数据:
Copy[dmdba@localhost bin]$ ./dmfldr userid=SYSDBA/SYSDBA@localhost:5238 control=\'/home/dmdba/test1.ctl\'注意
注意:使用 dmfldr 工具导入 excel 数据,涉及到文件格式转换,要注意中文编码以及 Windows 文件与 Linux 文件格式兼容的问题(比如空格)。
DM 如何导出 SQL 脚本/导出对象定义的 DDL 语句
方法一: 在管理工具中导出
- 导出单个对象的 DDL 语句
选中单个对象,如具体的表或者视图,单击右键选择【生成 SQL 脚本】,如下图所示:

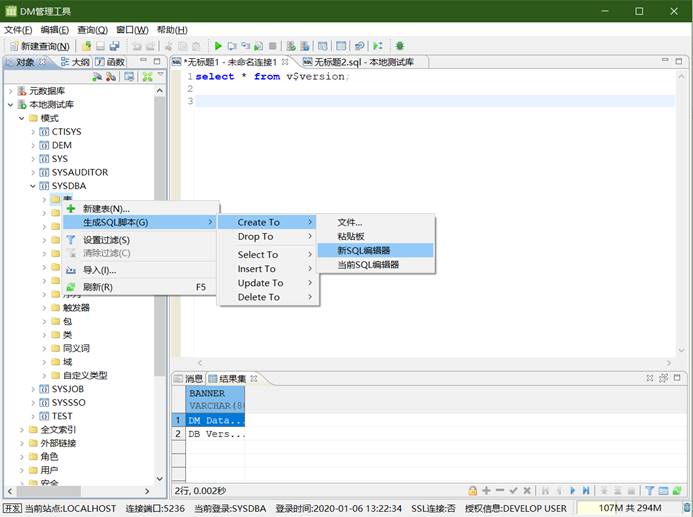
- 导出一类对象的 DDL 语句
选中表节点或者视图节点,右键,生成 SQL,会生成下面所有表的 SQL,如下图所示:
- 导出所有对象的 DDL 语句


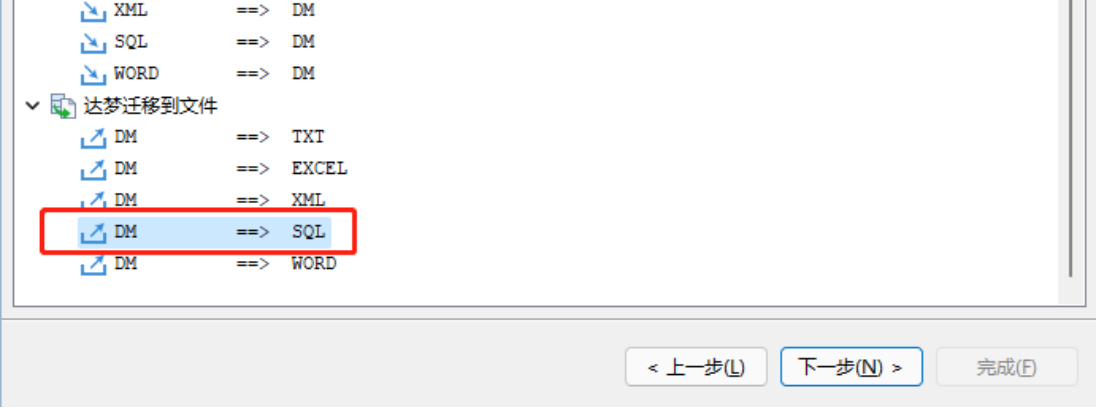
方法二: 利用 DTS 工具导出
新建迁移,选择迁移方式为"DM==>SQL"
配置达梦数据库信息
选择输出的 SQL 脚本文件名称,并选择"仅迁移对象定义"
选择迁移模式及对象类型,根据需求选择表、视图、存储过程等对象类型

选择要导出的对象
迁移任务概述
迁移导出完成

导入 dmp 的正确方式
导出备份文件,如下图所示:
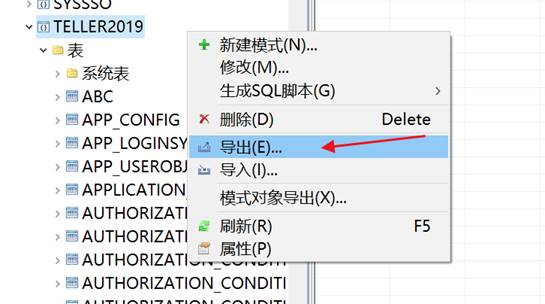
选择导出 dmp 存放的路径,如下图所示:

导出成功,如下图所示:

在选择的路径下会生成 dmp 文件和导出日志,如下图所示:
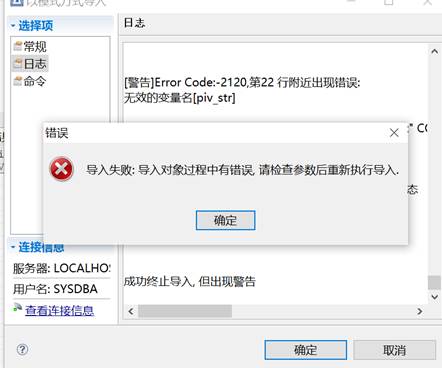
使用管理工具导入,如原表还存在,则报错,如下图所示:
- 如果只是一个表的导出 dmp 文件,则清空表
truncate table,再导入即可。
(为了防止清空表而导致数据丢失,可以重命名表如:alter table tab1 rename to tab2;再创建表和 tab2 一样表结构的 tab1 如:create table tab1 as select * from tab2 where 1=2;)
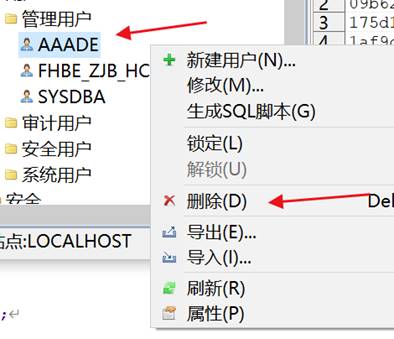
- 如果是模式导出的 dmp 文件,则先删除模式下的全部表。如表太多了,可以直接删除用户。重新创建用户,再模式导入 dmp 文件。
删除 drop、user 用户,如下图所示:
执行以下语句,创建用户(创建用户前,需先创建表空间):
Copycreate user "TELLER2019" identified by "TELLER2019"
default tablespace "HCSTTB"--指定数据表空间
default index tablespace "HCSTTB";--指定索引表空间
grant "PUBLIC","RESOURCE" to "TELLER2019"; --用户权限导入 dmp 备份文件,如下图所示:
选择 dmp 存放路径,如下图所示:

导入成功,如下图所示:

如果表已经存在了,使用默认方式导入 dmp 时会报错【表或视图已存在】,我们分以下不同情况讨论:
- 如果需要导入少量表且只表定义并未发生过变化,我们可以在导入命令增加参数 ignore=y 即可,导入时忽略创建错误;
- 如果需要导入的表定义已经发生过变化,则我们需要删除数据库中的表后再导入;
- 如果需要导入少量表且数据需要重新灌入,则可以将表数据备份之后,将此表 truncate,再进行导入操作,同时增加参数 ignore=y;
导入 dmp 文件时出现乱码、问号
一般是由于导出与导入时的字符集的环境变量不同。使用命令行 dimp 命令导入,并在执行 dimp 前先执行 export LANG=... 将当前字符集调整的和导出时的一样。
读取 DM 数据库中文乱码,则可能是使用的应用软件和 DM 数据库的应用软件字符集不一致,调整两个字符集为一致状态。另外,在 DM 数据库中,字符集一旦确定好则不可以修改,需要在创建 DM 数据库实例之前确定好字符集,保证不会出现此类问题。
导入 dmp 文件提示初始化参数不一致
警告信息如下:
Copy页大小不匹配,restore error code : -8210。
CASE_SENSIVE 参数不匹配、大小写参数不一致,大小写区分属性不匹配,restore error code : -8212。
LENGTH_IN_CHAR 属性不匹配,restore error code : -8266;编码不一致。- 页大小不匹配
【问题原因】:
这是因为产生备份文件的数据库数据文件使用页大小与还原备份文件的数据库数据文件所使用的页大小不同,必须保证两边的数据文件使用的页大小一致才能正常还原。
注意
数据文件使用的页大小 page_size,可以为 4 KB、8 KB、16 KB 或 32 KB,选择的页大小越大,则 DM 支持的元组长度也越大,但同时空间利用率可能下降,缺省使 8 KB。
【解决方法】:
使用数据库配置助手 dbca 重现初始化一个库,在设置参数时注意保证两边的页大小一致。
或者在命令行中使用 dminit 重现初始化一个库,在设置参数时注意保证两边的页大小一致。
- 大小写区分属性不匹配,restore error code : -8212
【解决方法】:
这是因为产生备份文件的数据库的标识符大小写 (case_sensitive) 的敏感程度与还原备份文件的数据库对标识符大小写的敏感程度不同,必须保证两边对标识符大小写敏感程度一致才能正常还原。
注意
标识符大小写敏感,默认值为 Y。当大小写敏感时,小写的标识符应用双引号括起,否则被转换为大写;当大小写不敏感时,系统不自动转换标识符的大小写,在标识符比较时也不区分大小写。
- LENGTH_IN_CHAR 属性不匹配
【解决方法】:
这是因为产生备份文件的数据库的 LENGTH_IN_CHAR 属性(默认为 0)与还原备份文件的数据库的 LENGTH_IN_CHAR 属性不一致,必须保证两边数据库的 LENGTH_IN_CHAR 属性一致才能正常还原。
注意
LENGTH_IN_CHAR 属性设置为 1 时,所有 VARCHAR 类型对象的长度以字符为单位,否则以字节为单位。
- 编码不一致
【解决方法】:
这是因为产生备份文件的数据库的字符集编码属性(默认为 GB18030)与还原备份文件的数据库的字符集编码属性不一致,必须保证两边数据库的字符集编码属性一致才能正常还原。
注意
只有初始化实例的时候可以选择以上属性,一经启用无法修改。需要重新初始化实例保持导出和导入的初始化设置一样。