构建一个LangChain RAG应用
01. 外挂知识库的聊天机器人架构
在 RAG 应用中,会通过外部的检索器/知识库检索人类的提问,然后将检索到的信息填充到提示模板中,一起传递给大语言模型,让其生成特定的内容,无论 RAG 应用有多么复杂,底层一定少不了这个步骤,这也是 RAG 的基础架构。
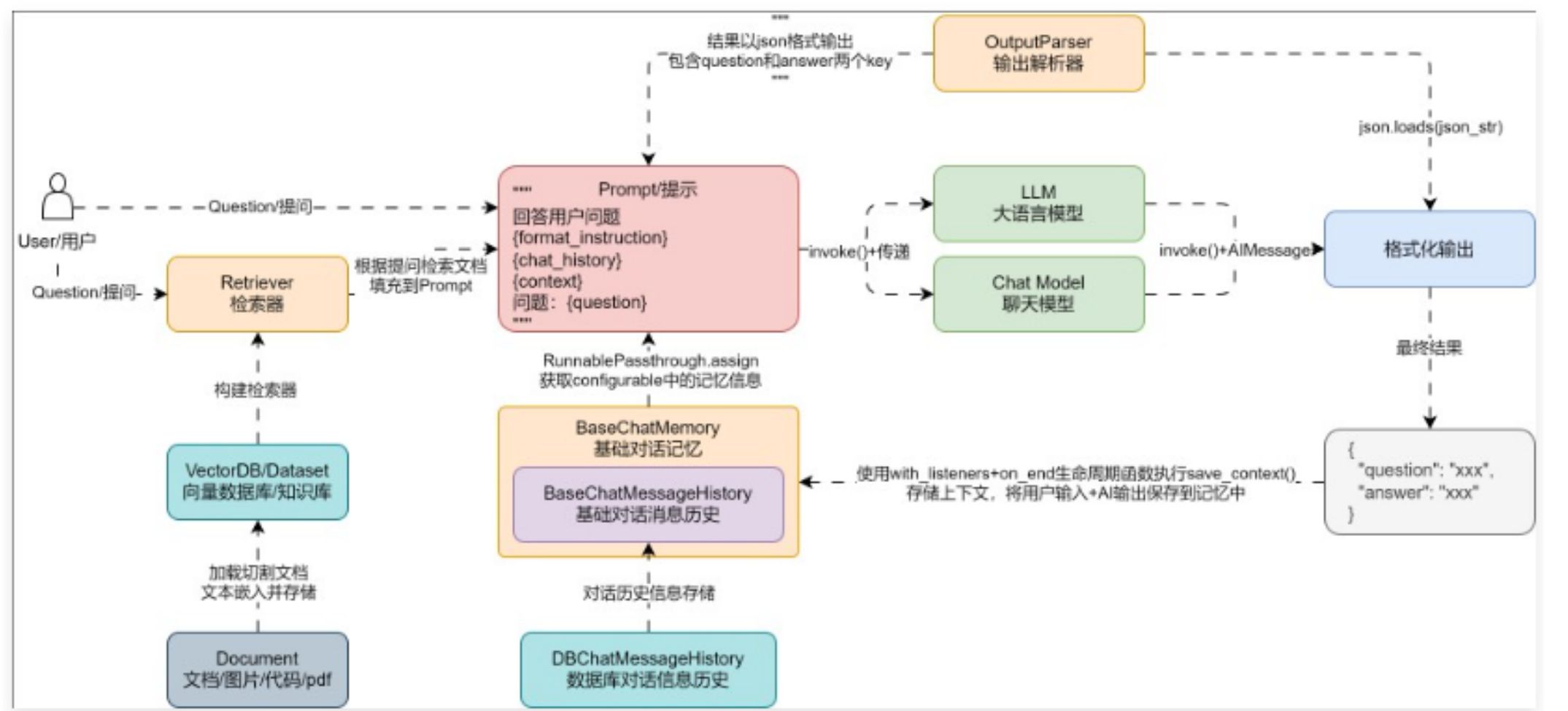
所以在 LangChain 中,也可以按照上述的流程图,将聊天机器人添加上知识库问答功能,思路其实非常简单:
- 和 Postgres 一样实例化一个全局的 Weaviate 向量数据库,避免每次调用时才进行连接,提升效率。
- 在聊天应用中,将 Weaviate 转换成检索器,并将生成的 Document 列表转换成字符串。
- 将处理好的检索器拼接到 LCEL 链输入字典中,用户提问时,检索对应内容并填充到 Prompt 模板中,从而实现知识外挂。
02. 外挂知识库的聊天机器人示例
在 LLMOps 项目中,我们对接的是 Weaviate 向量数据库,可以使用云端的向量数据库,也可以使用 Docker 搭建的向量数据库,两者并没有使用差异,修改后的代码如下。
集成的向量数据库服务
internal/service/vector_database_service.py
import os
import weaviate
from injector import inject
from langchain_core.documents import Document
from langchain_core.vectorstores import VectorStoreRetriever
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from weaviate import WeaviateClient
@inject
class VectorDatabaseService:
"""向量数据库服务"""
client: WeaviateClient
vector_store: WeaviateVectorStore
def init(self):
"""构造函数,完成向量数据库服务的客户端+LangChain向量数据库实例的创建"""
1.创建/连接weaviate向量数据库
self.client = weaviate.connect_to_local(
host=os.getenv("WEAVIATE_HOST"),
port=int(os.getenv("WEAVIATE_PORT"))
)
2.创建LangChain向量数据库
self.vector_store = WeaviateVectorStore(
client=self.client,
index_name="Dataset",
text_key="text",
embedding=OpenAIEmbeddings(model="text-embedding-3-small")
)
def get_retriever(self) -> VectorStoreRetriever:
"""获取检索器"""
return self.vector_store.as_retriever()
@classmethod
def combine_documents(cls, documents: listDocument) -> str:
"""将对应的文档列表使用换行符进行合并"""
return "\n\n".join(document.page_content for document in documents)
配置信息:
Weaviate向量数据库配置
WEAVIATE_HOST=192.168.2.120
WEAVIATE_PORT=8080
聊天机器人处理器:
def debug(self, app_id: UUID):
4.创建链应用
retriever = self.vector_database_service.get_retriever() | self.vector_database_service.combine_documents
chain = (RunnablePassthrough.assign(
history=RunnableLambda(self._load_memory_variables) | itemgetter("history"),
context=itemgetter("query") | retriever
) | prompt | llm | StrOutputParser()).with_listeners(on_end=self._save_context)