python
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 登录参数
login_data = {
'log': 'codetime',
'pwd': 'shanbay520',
'wp-submit': '登录',
'redirect_to': 'https://wpblog.x0y1.com',
'testcookie': '1'
}
# 发请求登录
login_req = requests.post('https://wpblog.x0y1.com/wp-login.php', data=login_data, headers=headers)
# 获取登录后的 cookies
shared_cookies = login_req.cookies
# 将登录后的 cookies 传递给 cookies 参数用于获取文章页面内容
res = requests.get('https://wpblog.x0y1.com/?cat=2', cookies=shared_cookies, headers=headers)
# 解析页面
soup = BeautifulSoup(res.text, 'html.parser')
# 选择所有的代表标题的 a 标签
titles = soup.select('h2.entry-title a')
# 获取四篇文章的链接
links = [i.attrs['href'] for i in titles]
for link in links:
# 获取文章页面内容
res_psg = requests.get(link, cookies=shared_cookies, headers=headers)
# 解析文章页面
soup_psg = BeautifulSoup(res_psg.text, 'html.parser')
# 获取文章内容的标签
content = soup_psg.select('div.entry-content')[0]
# 打印文章内容
print(content.text)我们理解下代码中的东西
1.登录参数
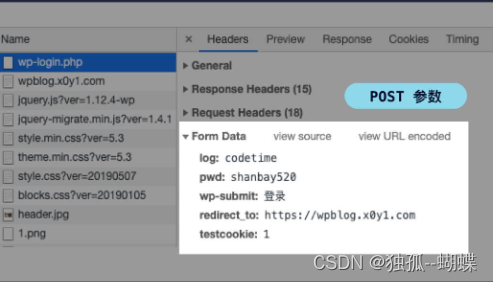
登录完成后,我们在右边的请求列表里点击第一条请求(wp-login.php),我们在请求详情里的 Form Data 中可以看到 POST 请求的参数,这些参数很容易看出代表什么:log 是用户名,pwd 是密码,wp-submit 是提交类型,redirect_to 是登录后的跳转地址,test_cookie 不知道,可以先不管
2.POST请求
GET 和 POST 本质上的区别是:
- GET 用于获取数据,比如刷微博;
- POST 用于提交数据,比如登录微博。
GET 和 POST 形式上的区别是:
- GET 的参数显示在请求地址里;
- POST 的参数隐藏在 Form Data 里。
通过 requests.post() 发送 POST 请求,而 POST 请求的参数通过字典的形式传递给 data 参数
3.cookie
cookie 是浏览器储存在用户电脑上的一小段文本文件。该文件里存了加密后的用户信息,过期时间等,且每次请求都会带上 cookie。所以,你登录过某网站后,下次再次打开该网站便不再需要登录。
python
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 登录参数
login_data = {
'log': 'codetime',
'pwd': 'shanbay520',
'wp-submit': '登录',
'redirect_to': 'https://wpblog.x0y1.com',
'testcookie': '1'
}
session = requests.Session()
session.headers.update(headers)
# 使用 session 登录
login_req = session.post('https://wpblog.x0y1.com/wp-login.php', data=login_data)
# 使用 session 获得 Python 分类文章
comment_req = session.get('https://wpblog.x0y1.com/?cat=2')
# 解析页面
soup = BeautifulSoup(comment_req.text, 'html.parser')
# 选择所有的代表标题的 a 标签
titles = soup.select('h2.entry-title a')
# 获取四篇文章的链接
links = [i.attrs['href'] for i in titles]
for link in links:
# 获取文章页面内容
res_psg = session.get(link)
# 解析文章页面
soup_psg = BeautifulSoup(res_psg.text, 'html.parser')
# 获取文章内容的标签
content = soup_psg.select('div.entry-content')[0]
# 打印文章内容
print(content.text)上面的代码中我们发现和最开始的代码有不同之处,就是使用了session
背景:
因为 HTTP 是无状态的,在一次请求、响应结束过后,连接就断开了。再次发起请求时,之前的状态全都丢失了,服务器也不再"认识你"。
有了 cookie 之后,我们可以将一些信息存到其中,比如用户身份信息等。但因为 cookie 容量有限,只有 4KB 。因此,不可能将所有的用户信息都存到里面。这时候,session 就出现了。
4.session
session 相当于在服务器上建立的一份用户档案,cookie 中只要存储用户的身份信息,服务器通过身份信息在 session 中查询用户的其他信息。这样一来,我们的所有操作都会被保留。比如我们添加到购物车的商品,重新打开页面后仍会被保留。
使用方法:
通过requests.Session() 创建一个session对象**,注意S是大写的。**get()、 post()等方法都有,只需要将原来的requests替换成创建的session即可。
有了 session ,多个请求之间就可以共享 cookie 了,后续请求便不再需要传 cookies 参数。
除了 cookies 参数每次都要传很麻烦,headers 参数每次都要传也很麻烦。如果想要共享 headers 的话,可以像下面这样写:
python
import requests
session = requests.Session()
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 设置 session 的全局 headers
session.headers.update(headers)
# 默认使用全局的 headers
session.get('https://wpblog.x0y1.com')
# 自定义 headers
custom_headers = { 'referer': 'https://wpblog.x0y1.com' }
session.get('https://wpblog.x0y1.com', headers=custom_headers)
# 既有全局的 user-agent 也有自定义的 referer