导读:
随着金融市场的深度演进,传统信贷风险评估模式已难以适配复杂金融环境下的精准风险管控需求。机器学习技术凭借其强大的数据挖掘能力与复杂关系建模优势,为商业银行信贷风险评估提供了创新性解决方案。本文首先通过深度解构商业银行信贷风险评估的业务逻辑,明确系统的核心功能与非功能需求;其次融合机器学习算法与软件工程技术,设计包含数据层、算法层、服务层及可视化层的分层架构体系,并划分为用户管理、风险评估、数据分析三大功能模块;继而以德国银行信贷数据集为基础,采用K-Means聚类算法实现客户分群,结合随机森林算法构建信贷风险预测模型,通过重采样技术解决样本不平衡问题,并基于网格搜索完成模型超参数调优。实证结果表明,所构建系统的风险评估模型测试准确率较高,在高风险客户识别与低风险客户精准判定方面表现优异,具有较强的实践应用价值。
作者信息:
魏晓光, 仝青山:河北金融学院河北省科技金融重点实验室,河北 保定
论文详情
当前,学界关于机器学习在信贷风险中的研究多聚焦于单一技术环节(如模型优化、数据预处理),尚未形成"数据--模型--系统"一体化的解决方案,导致技术成果难以直接落地应用。因此,构建覆盖需求分析、架构设计、模型训练、系统实现的全流程信贷风险评估系统,具有重要的理论创新价值与实践指导意义。
总体来看,信贷风险评估研究正步入多技术融合、多数据协同、多价值平衡的新阶段。未来的探索将不仅局限于预测准确率的提升,更在于构建安全、可信、高效且具备良好泛化能力的新型风控生态系统。
系统设计
1. 系统需求分析
- 用户管理功能
该模块负责用户身份认证与操作权限管控,核心流程包括注册、登录、历史记录管理,具体如表1所示。模块采用SHA256哈希算法对用户密码实施不可逆加密存储,通过会话(Session)机制实现登录状态管理,保障用户数据安全。
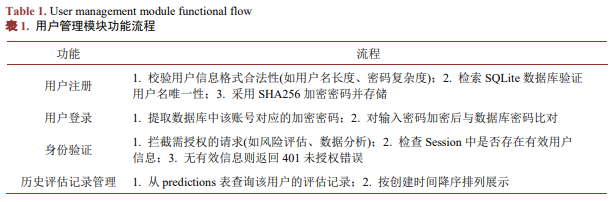
- 信贷风险评估模块
该模块是系统核心,负责接收客户多维特征变量,通过预训练模型输出风险评估结果,具体如表2所示。模块需对输入数据进行合法性校验(如数值范围、字段完整性),确保模型输入的有效性。
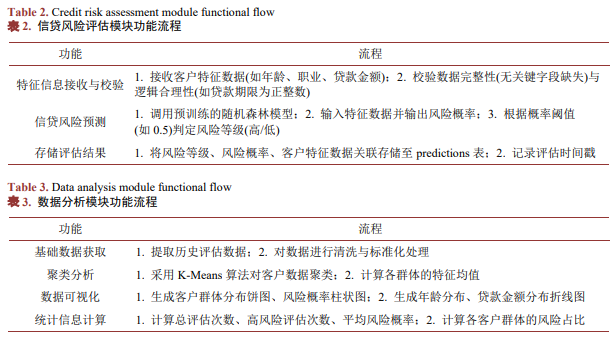
- 数据分析模块
该模块基于历史评估数据开展客户分群与风险特征分析,核心流程如表3所示。模块采用K-Means聚类算法实现客户群体划分,通过Chart.js生成可视化图表(柱状图、饼图),直观呈现客户分布与风险特征,为决策提供支撑。
本系统的非功能性需求涵盖了性能、安全与易用性三大维度。
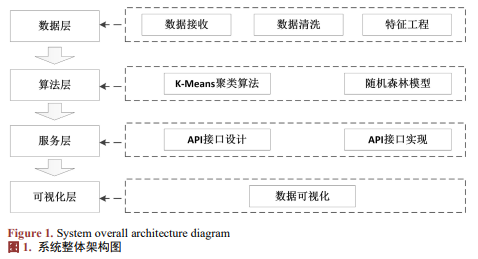
2. 系统架构设计
系统采用分层架构设计,实现功能模块解耦与可扩展性,架构分为数据层、算法层、服务层、可视化层,各层功能与交互逻辑如图1所示。
系统设计与模型架构
1. 数据预处理与特征工程
系统采用德国银行信贷数据集,该数据集包含1000条客户样本,每条样本涵盖9个特征变量,具体如表4所示。该数据集无天然风险标签,需通过K-Means聚类算法生成风险标签,作为随机森林模型的训练标签。

系统的数据加载功能由predictor.py文件中的load_and_preprocess_data方法实现,该方法通过pandas库读取CSV格式数据,同时调用数据清洗与特征工程函数,输出预处理后的特征矩阵与原始数据框,为后续模型训练提供数据输入。
进行特征编码,特征选择与标准化,模型选择和K-Means聚类模型训练,详情见原文链接。
聚类客群定性画像分析结果如表5所示。
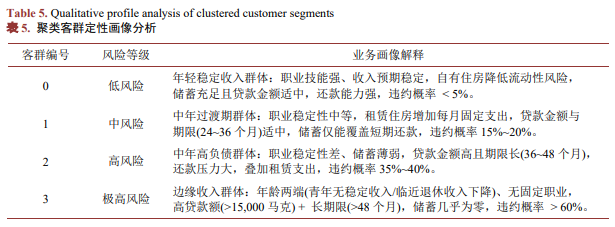
由定性分析可见,各客群的特征与风险等级高度匹配,符合商业银行对客户风险的认知逻辑,进一步证明K-Means生成的风险标签具有业务合理性。
进行随机森林预测模型训练,性能对比结果如表6所示。

2. 模型评估与调优
评估结果如表7所示。
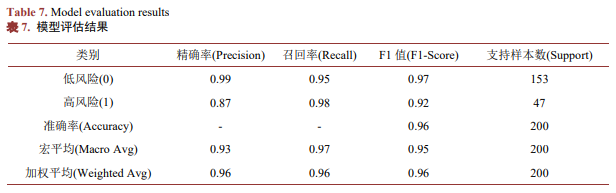
结果分析:
模型整体准确率达96%,说明系统对多数客户(约96%)的风险预测准确,可满足商业银行日常信贷评估需求;
高风险客户召回率达0.98,意味着仅2%的高风险客户被误判为低风险,能有效识别潜在违约客户,大幅降低银行坏账风险;
低风险客户精确率达0.99,表明仅1%的低风险客户被误判为高风险,可精准定位优质客户,减少优质客户流失,提升信贷服务效率;
高风险客户精确率(0.87)相对较低,存在13%的低风险客户被误判为高风险的情况,可能导致部分优质客户信贷申请被拒,需在后续优化中改进(如调整模型阈值、增加特征维度)。
综合来看,随机森林模型在本系统的信贷风险评估任务中表现优异,核心指标均达到业务要求,可有效支撑商业银行信贷决策;但高风险客户精确率仍有优化空间,需通过后续调优进一步提升模型性能。
结论
信贷业务作为商业银行核心业务,其风险评估精度对银行稳健运营至关重要。本文结合机器学习技术,构建了融合K-Means聚类算法与随机森林模型的商业银行信贷风险评估系统,主要工作与成果如下:
技术与理论梳理:系统梳理信贷业务核心概念、机器学习关键算法(K-Means聚类、随机森林)及系统开发技术栈(FastAPI, SQLite, Chart.js),明确各技术模块的适配逻辑,为系统构建奠定坚实的理论基础;
系统设计与架构搭建:通过需求分析明确系统的功能需求(用户管理、风险评估、数据分析)与非功能需求(性能、安全、易用性),设计"数据层--算法层--服务层--可视化层"分层架构,实现功能模块解耦与可扩展性,同时划分三大功能模块,确保系统贴合商业银行实际业务流程;
系统实现与模型训练:完成全流程技术落地,包括数据预处理(缺失值填充、特征编码、标准化)、双模型协同训练(K-Means生成风险标签、随机森林预测风险)及模型调优(网格搜索提升性能),解决样本不平衡、特征适配性等关键技术问题;
实证验证与价值体现:系统测试结果显示,随机森林模型准确率达96%,高风险客户召回率0.98,低风险客户精确率0.99,相较于传统人工评估模式(准确率约70%~80%),显著提升风险评估的准确性与效率,为银行信贷决策提供可靠的数据驱动支撑,降低坏账风险的同时,提升优质客户服务体验。
基金项目:
河北省科技金融协同创新中心、河北省科技金融重点实验室开放基金项目(课题号:STFCIC202404)。
原文链接: