背景
OceanBase 4.0版本新增了单日志流架构,使得OBServer单机突破了原有的分区数限制,支持更大数量的分区。
很多业务环境为了处理单机数据量过大的问题,通常采取分库分表的方法,这一方法会导致业务需要创建数十万乃至百万级别的表。然而,当这些业务迁移到OceanBase时,由于OceanBase集群内部DDL操作是串行执行的,使得通过OMS进行结构导入的过程变得异常耗时,经常需要数十小时才能完成,这无疑对迁移的效能造成了影响。
结构迁移的DDL以建表语句为主,所以要解决OMS结构导入的速度,关键就是要提升建表语句的吞吐。OceanBase v4.2.1对建表方案进行并发化改造,使无冲突的建表语句之间能并发执行,通过提高OMS结构导入DDL语句的吞吐,降低整体执行耗时。
实现原理
下面通过分别介绍串行DDL和并行DDL的实现原理,直观的从流程上感受DDL执行过程中耗时的地方,了解并行DDL功能改造的价值。
串行DDL
每个集群都有一个唯一的RootService服务,RootService服务所在的节点有一个DDL线程,集群内所有的DDL都会路由到RootService服务所在节点上串行执行。
如下图所示,两个不同的client的DDL请求路由到OBServer上,会内部路由到RootService服务所在的节点排队执行,客户端同步等待DDL的执行结果。视DDL请求的复杂度而定,执行单个DDL耗时一般在100ms以上;多个DDL请求按到达RootService服务所在节点的顺序,排队串行执行。
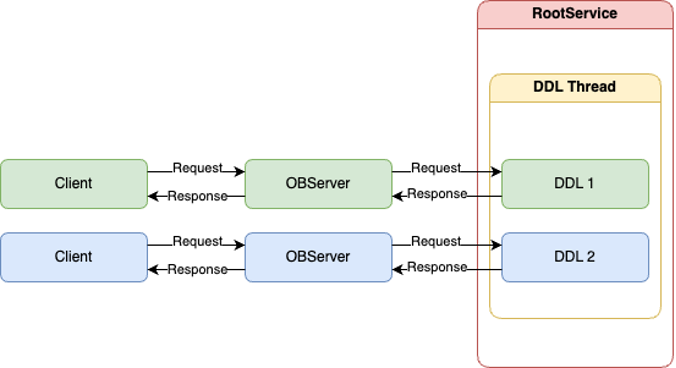
不论集群与租户的规格有多大,始终只有一个线程执行DDL。在高并发DDL场景下,受限于DDL集群内串行执行的限制,绝大多数DDL都在队列中等待执行,整体DDL的吞吐很低。但实际上集群有很多空闲资源有待利用。
并发DDL
OceanBase v4.1.0 版本初次提供了并发DDL执行的能力。如下图所示,通过扩展RootService服务所在节点的DDL线程数目,将单一DDL的实现拆分成不同阶段,同时将其中的部分阶段进行并行化改造。使得RootService服务所在的节点有一定的并发执行能力处理多个无冲突的DDL请求,有效提高整体DDL的吞吐。
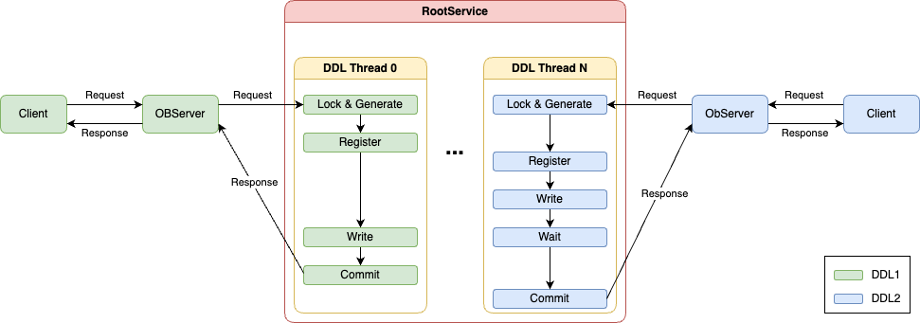
上述改造使得RootService可以将所在节点中更多的空闲资源利用起来,进行DDL服务。RootService所在节点扩展出来的DDL线程数目跟集群的规格相关,因此当集群与租户的规格扩展时,DDL的执行能力也能随之扩展。
目前具备并发执行能力的DDL有:
truncate table:OceanBase 4.1.0版本 版本开放相关能力。create table:OceanBase 4.2.1版本 版本开放相关能力。
使用说明
当集群以OceanBase 4.2.1之后的版本部署起来,或者升级到4.2.1之后的版本,并发建表的功能就会自动开启,无需用户额外进行配置。租户下可以执行以下语句查看当前租户的版本,当版本 >= 4.2.1,用户可以通过起多个并发执行建表语句启用并发建表的功能。
MySQL [oceanbase]> show parameters like "compatible";
+------+----------+----------------+----------+------------+-----------+---------+---------------------------------------+--------------+--------+---------+-------------------+
| zone | svr_type | svr_ip | svr_port | name | data_type | value | info | section | scope | source | edit_level |
+------+----------+----------------+----------+------------+-----------+---------+---------------------------------------+--------------+--------+---------+-------------------+
| z2 | observer | 100.88.107.209 | 3025 | compatible | NULL | 4.2.1.0 | compatible version for persisted data | ROOT_SERVICE | TENANT | DEFAULT | DYNAMIC_EFFECTIVE |
| z1 | observer | 100.88.107.223 | 3024 | compatible | NULL | 4.2.1.0 | compatible version for persisted data | ROOT_SERVICE | TENANT | DEFAULT | DYNAMIC_EFFECTIVE |
| z3 | observer | 100.88.107.212 | 3026 | compatible | NULL | 4.2.1.0 | compatible version for persisted data | ROOT_SERVICE | TENANT | DEFAULT | DYNAMIC_EFFECTIVE |
+------+----------+----------------+----------+------------+-----------+---------+---------------------------------------+--------------+--------+---------+-------------------+
3 rows in set (0.07 sec)注意事项
- 并发DDL和串行DDL逻辑整体互斥,要想并发DDL整体达到最大吞吐,需要避免并发DDL执行过程中集群有其它的串行DDL执行。
- 由于DDL请求总是由RootService所在节点执行,为了减少DDL执行过程中的网络消耗,需要尽可能的保证RootService和租户leader在同一个节点上。
- 由于提高了建表的并发度,并发执行的DDL对系统会有额外的负载,需要消耗额外的资源。
- 系统租户需要有足够的线程响应DDL请求,想要达到DDL最大吞吐,系统租户需要额外的6C(CPU)。
- 用户租户需要有足够的线程响应DDL请求及写内部表的请求,想要达到DDL最大吞吐,用户租户需要额外的14C(CPU)。
同时,由于并发执行的建表语句吞吐量较大,短时间内会往内部表写入大量数据,对租户的内存、磁盘有额外的要求。租户磁盘较小内存难以转储落盘,而内存紧张的情况下会触发写入限速,影响并发DDL执行速度以及已有业务流量。
性能对比
OBSERVER建表性能测试
在以下部署方式下,使用不同方式创建不同数目的非分区表,有如下测试结果及结论。
环境部署
- 1:1:1部署,RS和租户leader部署在一起,压力起在备节点。
- sys租户规格:16C32G
- 普通租户规格:8C80G
建表语句
DDL1:
create table t1 (c1 int primary key, c2 int, c3 varchar(20), c4 int, c5 timestamp, c6 int, c7 int, c8 int, c9 int, c10 varchar(20));
DDL2:
create table t1 (c1 int primary key, c2 int, c3 varchar(20), c4 int, c5 timestamp, c6 int, c7 int, c8 int, c9 int, c10 varchar(20), key i1(c4));
测试结果
|------------|--------|--------|----------|--------|---------------|----------|---------|---------------------------------|
| DDL类型 | DDL1 || DDL1 || DDL1 || DDL1 | DDL2 |
| 表数目 | 3,200 || 100,000 || 1,000,000 || 683680 | 683,678 (table)+683,678 (index) |
| 并发数 | 32 || 32 || 32 || 32 | 32 |
| 方式 | 串行 | 并发 | 串行 | 并发 | 串行 | 并发 | 并发 | 并发 |
| 总耗时(s) | 488.63 | 16.38 | 15928.64 | 549.61 | 159286.4(理论值) | 13775.08 | 6433.12 | 11441.5 |
| QPS(req/s) | 6.55 | 195.38 | 6.28 | 181.95 | 6.28(理论值) | 72.59 | 106.28 | 119.5 |
由于串行创建100W张表耗时过长,暂以10W表的性能为准,考虑到性能衰减,实际QPS会更低,仅用于与并发建表性能进行对比。
基于上述测试结果有以下结论:
- 随着建表数目的增加,受限于实时内存使用情况,串行建表和并发建表的性能都有所衰减。并发建表由于在较短时间内写入大量数据,衰减程度较为显著;串行建表总耗时较长,QPS较为稳定。
- 建表语句较为简单的情况下,并发建表性能较串行建表性能有10~30倍性能提升。
- 建表语句带索引,索引表相比用户表构建耗时更短,同等表(含索引)数目量级QPS会有所提升。
- 经测试,租户leader和RS不在同一个节点,DDL会涉及远程执行以及分布式执行,同等量级性能约衰减为原来的50%。
需要注意的是,该场景验证的相对简单的创建非分区表的性能,建表语句越复杂(是否分区、是否含索引/外键、是否带索引等),单个建表语句耗时越长,并发DDL的吞吐也会相应下降。但即便如此,并发建表的性能较串行建表也有10倍以上性能提升。
实际OMS导入场景实例
|-----|--------|-----------------|------|
| 集群规格: 8C32G 租户规格: 4C16GB mysql库表统计:Table:9101(非分区表)版本:4.2.1 ||||
| 模式 | 串行建表 | 串行建表+schema异步刷新 | 并行建表 |
| 总耗时 | 17 min | 13min | 5min |
该场景集群规格为8c,能够分配四个并行DDL工作线程进行并行建表任务。在同样尽力确保多机schema同步刷新的条件下,可以看到并行建表速度相比于串行建表速度提升了三倍多。而串行建表过程中将schema异步刷新的优化打开,并行建表也比串行建表速度提升了两倍多。