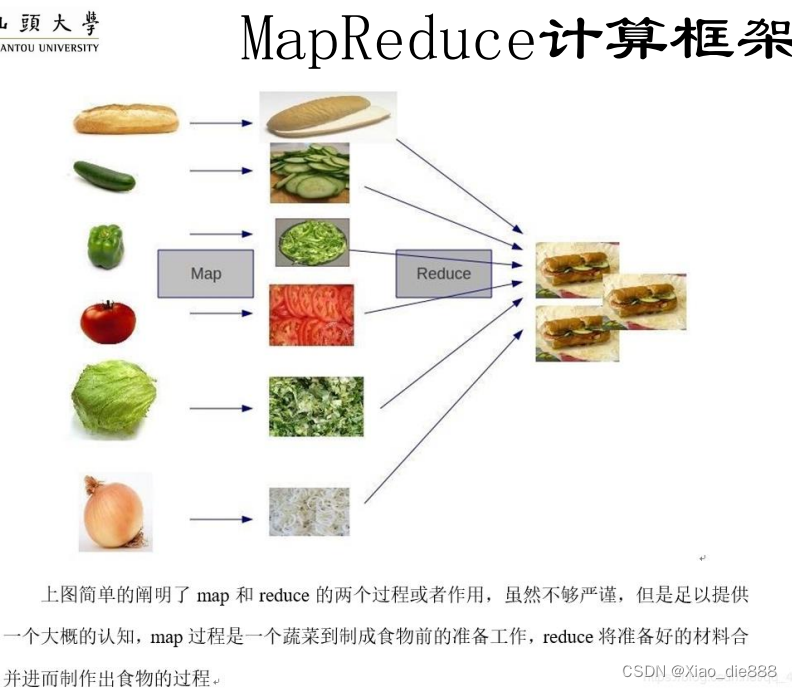
大数据处理框架概念
- 定义:由一系列组件构成,负责对数据系统中的数据进行计算。
- 组件 :
- 处理引擎:实际执行数据操作的独立组件。
- 处理框架:包含多个协同工作的组件。
框架与引擎的区别
- 引擎:单一的,专门执行任务。
- 框架:由多个引擎和辅助组件组成,提供更广泛的功能。
框架示例
- Apache Hadoop:以MapReduce作为默认处理引擎的框架。
- Apache Spark:可以整合进Hadoop,取代MapReduce的框架。
互操作性
- 引擎和框架:可以相互替换或同时使用,增加了系统的灵活性。
目标
- 提高理解能力:通过对数据执行操作来增强对数据的理解。
- 揭示模式:发现数据中蕴含的模式。
- 获得见解:针对复杂互动提供深刻的洞察。
数据处理分类
- 批处理:处理静态的、存储在系统中的数据集。
- 流处理:处理实时生成并流入系统的数据流。
- 混合处理:一些系统能够同时处理批数据和流数据。
大数据计算框架
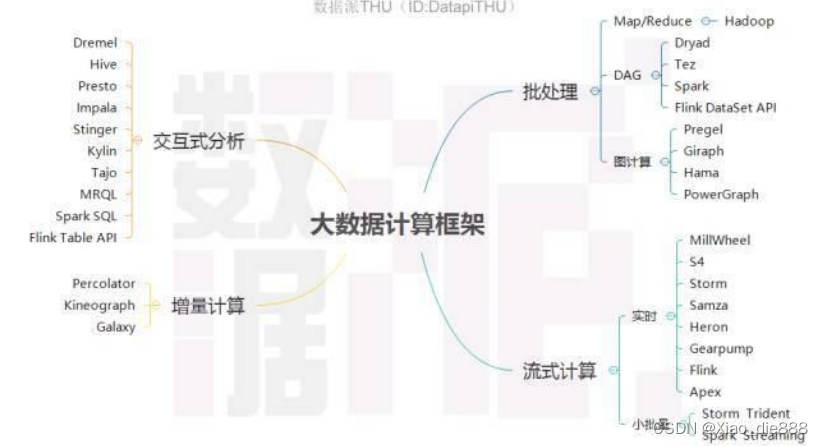
批处理系统特点
操作对象 :大容量静态数据集。
- 计算方式 :计算完成后返回结果。
- 数据特征 :
- 有界:处理有限的数据集合。
- 持久:数据存储在持久化介质。
- 大量 :适合处理大规模数据集。
批处理适用性
- 计算需求 :需要访问全套记录的计算工作。
- 实例:计算总数和平均数,要求数据集整体处理。
- 状态维持:计算过程中数据需保持状态。
批处理系统设计
- 处理资源 :需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
- 适用场景:常用于历史数据分析。
- 局限性 :大量数据的处理需要付出大量时间,因此批处理不适合对处
理时间要求较高的场合。
MapReduce框架
- 功能:按特征归并杂乱数据,处理得到结果。
- 复杂问题:通过多个MapReduce组合表达复杂计算问题。
- 设计 :组合过程需人工设计,比较麻烦。另外,每个阶段都需要所有的计算机同步,影响了执
行效率。
DAG计算模型
- 定义 :有向无环图,核心思想是把任务在内部分解为若干存在先后顺序的子任务。
- 灵活性:更灵活地表达复杂依赖关系。
- 模型示例 :
- Microsoft Dryad
- Google FlumeJava
- Apache Tez
Dryad定义了串接、全连接、融合等若干简单的DAG模型,通过组合这些简单结构来描述复杂的任务,FlumeJava、Tez则通过组合若干MapReduce形成DAG任务。
MapReduce的另一个不足之处 是使用磁盘存储中间结果,严重影响了系统的性能。Spark 对早期的DAG模型作了改进 ,提出了基于内存的分布式存储抽象模型RDD,把中间数据有选择地加载并驻留到内存中,减少磁盘IO开销。
流处理系统基础
- 定义:实时处理动态产生数据的系统。
- 目的:快速处理数据,适用于大数据时代。
流处理系统的必要性
- 实时需求:数据迅速处理,响应时间短。
- 容错性:系统稳定,处理数据时避免遗漏或重复。
- 拥塞控制:有效管理数据流,防止系统过载。
流处理系统操作特点
- 即时计算:对流入系统的每个数据项进行实时处理。
- 无边界数据集:数据持续到达,没有固定结束点。
流处理的影响
- 数据集理解 :
- 完整数据集:代表已处理的数据总量。
- 工作数据集:特定时间点,只关注单个数据项。
- 事件驱动:处理基于数据到达的事件,持续进行。
- 结果更新:处理结果随新数据到来而实时更新。
流处理系统能力
流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条 (真正的流处理)或很少量 (微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。
交互式分析框架概述
- 需求背景 :在大数据存储和计算基础上,提供数据分析便利。
- 核心优势:交互式查询,提高数据分析效率。
交互式分析技术发展
- 快速发展:近年来,交互式分析技术迅速进步。
- 多样化平台:出现多个知名交互式分析平台。
主要交互式分析平台
- Google Dremel:快速处理大规模数据,3秒内处理1PB数据。
- PowerDrill:Google开发的高效数据分析工具。
- Presto:Facebook开发,适用于多种数据源的交互式查询。
- Impala:Cloudera开发,提供Hadoop的SQL查询。
- Stinger:HortonWorks开发,提高Hive的交互式查询性能。
- Apache项目:包括Hive、Drill、Tajo、Kylin、MRQL等。
交互式分析特点
- 处理速度 :快速分析海量数据,兼顾速度和精度。
- 用户体验:提供便利的数据分析方式,提高工作效率。
增量计算框架
- 定义 :仅对部分新增或更新数据进行计算,提升效率。
- 应用场景:数据增量更新或周期性更新。
- 代表框架 :
- Google Percolator
- Microsoft Kineograph
- 阿里 Galaxy
高性能事务处理框架
- Apache Ignite:提供高性能的事务处理能力。
- Apache Geode:GemFire的开源版本,适用于分布式数据管理。
图计算框架
- 模型:基于图论的迭代式计算模型。
- 应用:PageRank计算、社交网络分析、推荐系统、机器学习。
- 代表框架 :
- Google Pregel
- Apache Giraph
- Apache Hama
- PowerGraph(领域杰出代表)
以下是对MapReduce基本设计思想的总结:
MapReduce设计思想总结(概述)
分而治之策略
- 核心理念: MapReduce采用分而治之的方法,将大数据集分解成独立、可并行处理的数据块。
- 独立性: 数据块之间无依赖关系,允许同时进行计算,提高处理速度。
数据分片与并行处理
- 数据划分: 将大数据集逻辑上划分为多个数据分片。
- 节点分配: 每个数据分片由集群中的不同节点负责处理。
- 汇总结果: 所有节点处理完成后,汇总各节点的计算结果。
MapReduce抽象模型
- Map函数: 对每个数据分片执行的函数,生成中间键值对。
- Reduce函数: 根据Map函数的输出,对具有相同键的值进行汇总。
编程接口
- 简化开发: 程序员仅需实现Map和Reduce两个接口。
- 灵活性: 通过这两个接口,MapReduce可以应用于多种数据处理场景。
顺序数据的处理
- 设计目标: 针对顺序组织的数据元素或记录设计。
- 实际应用: 适用于处理重复性数据,如Web访问日志。
处理流程
- 数据切分: 将数据集切分为多个数据块。
- Map操作: 对每个数据块应用Map函数。
- Shuffle过程: 对Map的输出进行排序和分组。
- Reduce操作: 对每个键的值进行汇总,生成最终结果。
== MapReduce主要功能==
数据划分与任务调度
- 自动化: 系统自动将大数据集划分为多个数据块,每个块对应一个任务。
- 资源分配: 计算节点(Map和Reduce节点)被自动分配任务。
- 监控与同步: 监控节点状态,同步Map任务执行。
数据/代码互定位
- 本地化原则: 优先在数据所在节点处理数据,减少通信开销。
- 代码迁移: 当本地化不可能时,数据通过网络发送到计算节点。
- 延迟减少: 尽可能在数据所在机架上找到可用节点。
系统优化
- 中间结果合并: 减少数据传输,提高效率。
- 数据相关性: 确保相关数据发送到同一Reduce节点。
- 性能优化: 对慢任务采用多备份执行,选择最快结果。
出错检测与恢复
- 常态处理: 硬件和软件错误视为常态。
- 错误隔离: 检测并隔离出错节点。
- 任务接管: 调度新节点接管计算任务。
- 数据可靠性: 多备份机制,及时恢复出错数据。
MapReduce框架组成
1. Client(客户端)
- 角色: 用户接口,提交作业到系统。
- 功能: 打包应用程序和配置成Jar文件。
- 操作: 将Jar上传到HDFS,提交作业路径给JobTracker。
2. JobTracker(作业跟踪器)
- 角色: 集群管理中枢,负责资源监控和作业调度。
- 功能 :
- 监控TaskTracker和作业状态。
- 任务失败时重新分配。
- 跟踪执行进度和资源使用。
- 与任务调度器协作。
3. TaskTracker(任务跟踪器)
- 角色: 集群中的工作节点。
- 功能: 执行来自JobTracker的任务。
- 通信: 通过心跳与JobTracker保持通信。
- 操作: 汇报资源使用和任务进度,响应JobTracker命令。
4. Task(任务)
- 类型: MapTask和ReduceTask。
- 启动: 由TaskTracker根据split信息启动。
- 处理单位: Split,包含数据的元数据信息。
核心概念
- Split: MapReduce的处理单元,由用户定义,决定MapTask数量。
- HDFS Block: HDFS的数据存储单元。
作业执行流程
- 客户端提交: 用户通过Client提交作业。
- Jar上传: 应用程序和配置信息上传到HDFS。
- JobTracker调度: 分配任务到TaskTracker。
- TaskTracker执行 : 根据split执行MapTask和ReduceTask。