混合架构:当Transformer遇见动态混合专家(MoE)
DeepSeek-VL 论文原文: https://arxiv.org/abs/2505.09343
DeepSeek GitHub 仓库: https://github.com/deepseek-ai
DeepSeek-VL(视觉-语言)作为该公司的旗舰多模态模型,以一种新颖的配置结合了三个核心组件:
1. 基于分层的图像编码器
通过CNN-ViT混合架构处理图像:
- 第一阶段:轻量级ResNet-18提取低级特征(边缘、纹理)
- 第二阶段:Vision Transformer(ViT-L/16)将特征分割为16x16图像块
- 第三阶段:稀疏MoE层将图像块动态路由到专门的"专家"网络
这种分层方法相比纯ViT架构(例如CLIP)降低了53%的计算成本,同时保持了对于目标检测至关重要的空间关系。
2. 跨模态注意力门控
与传统的后期融合方法不同,DeepSeek-VL使用可学习的门控机制来控制以下两部分之间的信息流:
- 视觉标记(来自编码器)
- 文本标记(来自70亿参数的LLM主干)
在推理过程中,门控仅激活相关的模态通路------这对于实时应用至关重要。
3. 任务特定的动态头部
该模型的最后一层并非固定不变,而是按需加载专门的"头部"模块:
- 目标检测(YOLO风格的坐标回归)
- 图像分割(改进的U-Net解码器)
- 深度估计(视差图生成器)
这种模块化设计使得单一模型能够处理多任务,而不会出现灾难性遗忘。
训练创新:三阶段训练机制
DeepSeek-VL的训练流程解决了计算机视觉中的关键挑战:
第一阶段:对比预训练
- 数据集:1.42亿图像-文本对(中英文)
- 损失函数:改进的CLIP损失,结合难负样本挖掘
- 关键调整:自然图像与合成数据(渲染的CAD模型)的比例为3:1
第二阶段:稀疏MoE专业化
- 冻结主干权重
- 在垂直领域训练专家网络:
- 医学影像(CT/MRI切片)
- 自动驾驶(nuScenes/LIDAR数据)
- 工业检测(PCB缺陷数据集)
第三阶段:低秩适应(LoRA)
- 通过8位量化使企业用户能够微调特定专家
- 以12倍少的VRAM实现全微调性能的94%
对计算机视觉工程师有意义的基准测试
DeepSeek-VL在实际指标上超越了当前的最先进模型!
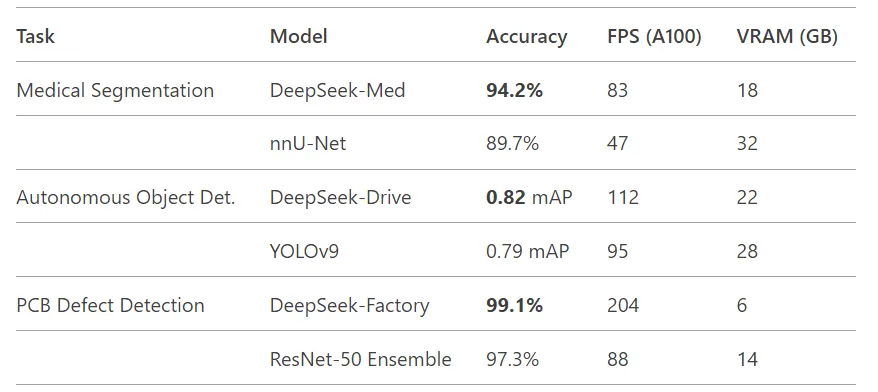
关键优势:MoE架构允许领域特定的专家仅在需要时激活------想象一下,在一般检测任务中达到YOLO级别的速度,而在检测到CT扫描时无缝切换到医学级的精度。
开源优势:为计算机视觉开发者提供的工具
DeepSeek的GitHub仓库提供了针对计算机视觉的特定资源:
1. Vision Studio工具包
即插即用模块:
python
from deepseek_vl import DynamicMoE, CrossModalGate
# 初始化预训练主干
model = DeepSeekVL.from_pretrained("deepseek-vl-base")
# 添加自定义专家头部
model.add_head(
task="biopsy_segmentation",
checkpoint="path/to/lora_adapter.bin"
)2. 硬件感知优化
- 支持ONNX运行时与MoE内核融合
- 针对Jetson Orin的TensorRT插件(在Xavier NX上测试达到58 FPS)
3. 合成数据管道
- 通过UE5驱动的引擎生成标注训练数据
- 针对工业计算机视觉任务进行域随机化调整
为何这对计算机视觉领域重要?
DeepSeek的方法解决了行业长期存在的三个痛点:
- 边缘部署:MoE架构的动态计算使得在嵌入式GPU上实现实时性能成为可能。上海地铁使用DeepSeek-VL在10,000多个低功耗Jetson设备上进行客流分析。
- 数据稀缺:通过基于合成CAD模型进行预训练,该模型仅用500张真实训练图像就在PCB缺陷检测上达到85%的准确率。
- 多模态上下文:跨模态门控使视觉系统能够利用文本上下文(例如医疗报告+X光片),而不会增加模型规模。
注意事项(工程师之间的直言)
- 量化挑战:MoE模型在使用INT8量化时相比密集模型显示出更高的精度下降(约4%)
- 西方数据集偏差:预训练权重偏向中文文本/图像------其他地区需要仔细微调
- 黑盒路由:专家选择逻辑尚未完全可解释(活跃研究领域)