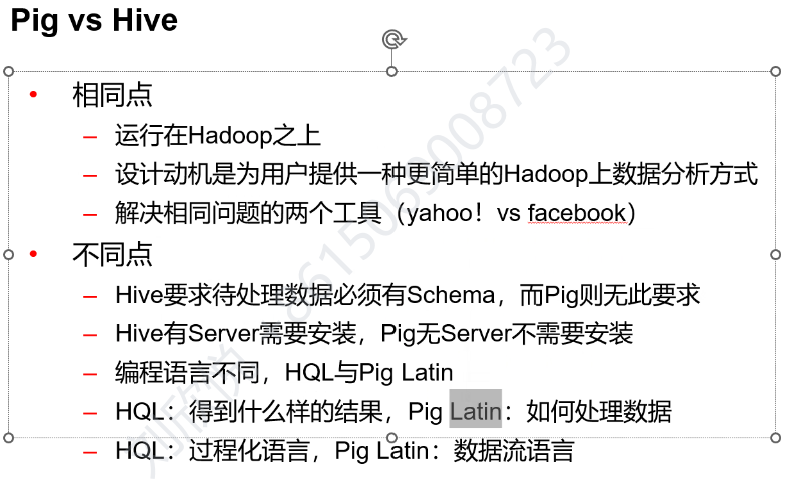
YARN
YARN是 Hadoop 的资源管理和作业调度层。
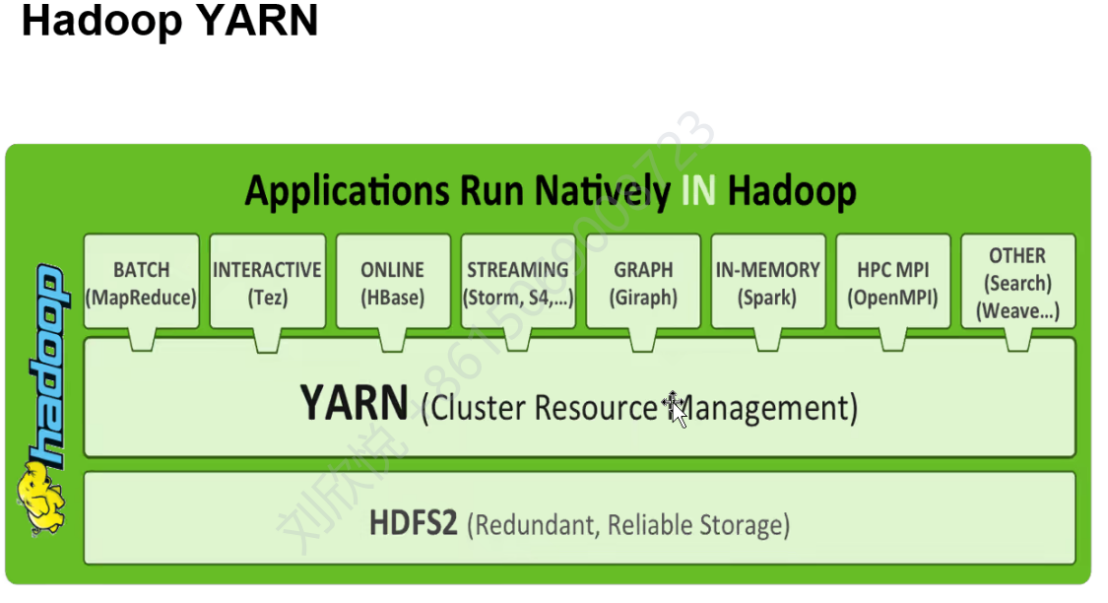
Resource Manager(RM)只有一个,管理所有资源,相当于yarn的master。Node Manager(NM)每个节点有一个,管理节点的资源。RM管理多个NM,监听他们的心跳。RM存在单点故障,但可以基于zookeeper实现HA(高可用)。
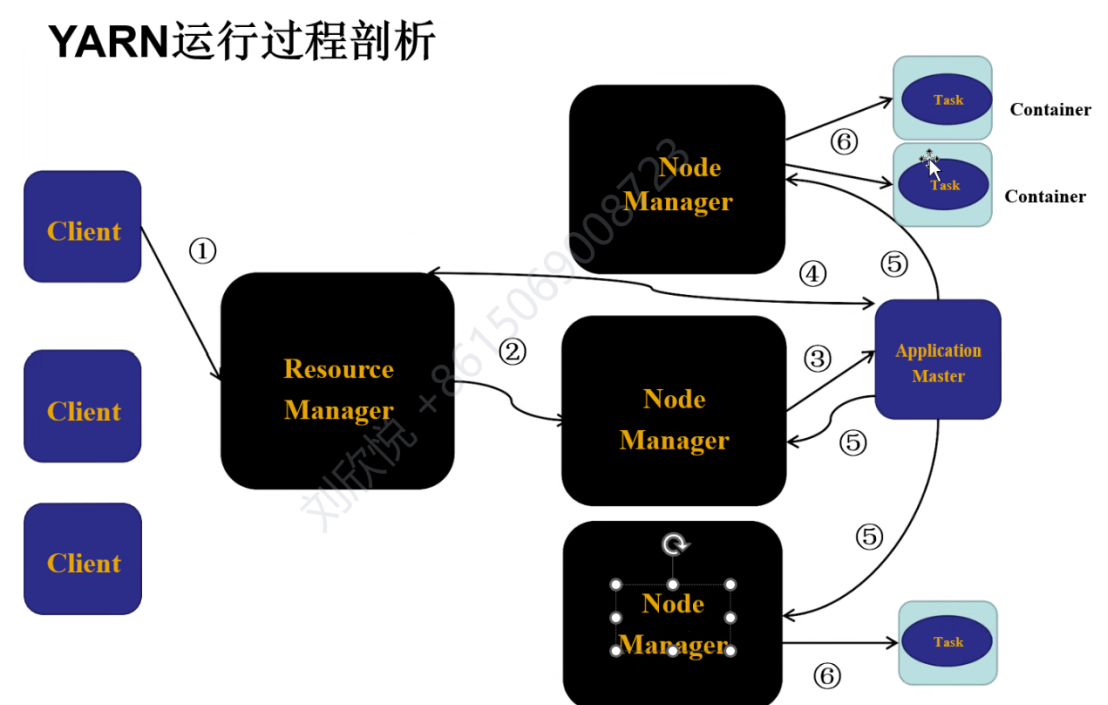
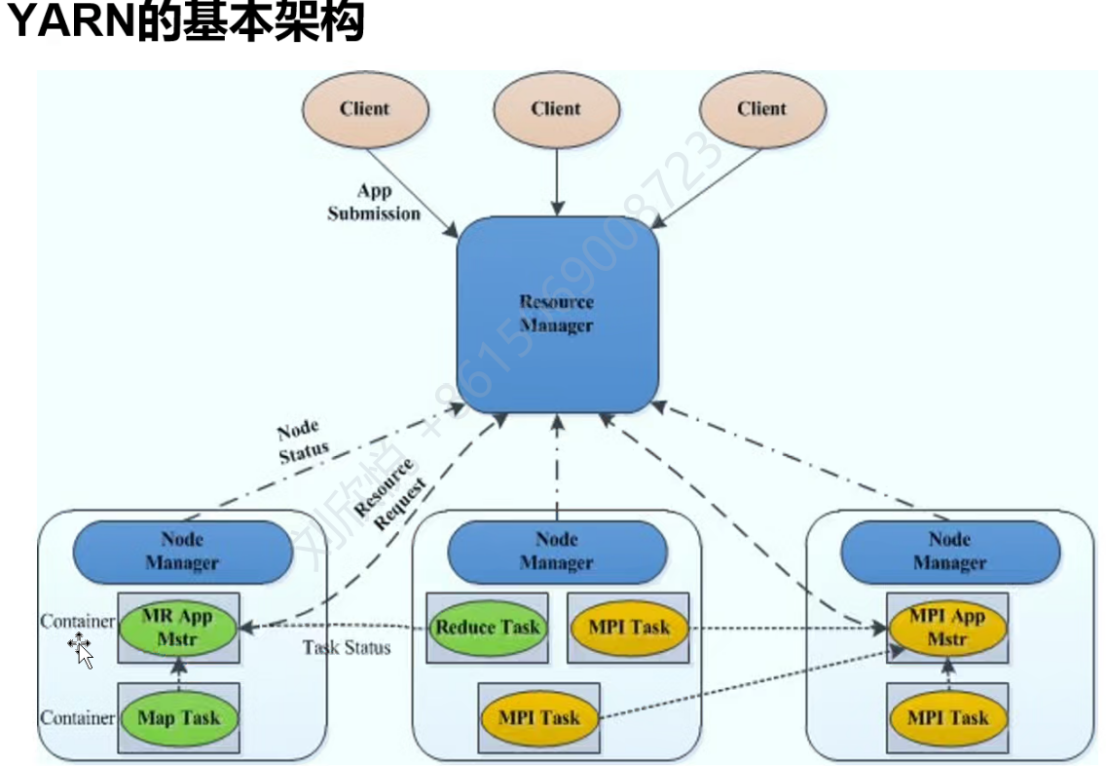
yarn运行过程
client向RM提交ApplicationMaster程序、启动命令以及应用程序本身,RM会根据节点资源使用情况找一个节点运行AM,然后AM将自己的任务和资源请求汇报给RM,RM就会在各个节点创建任务、分配资源,然后AM可以直接与节点上的NM通信,监督资源的完成状况,AM也会定期向RM发送心跳。Client可以在AM或RM获得应用的运行状况。
容错性体现
Task失败后NM会将失败的任务告诉AM,AM决定如何处理失败的任务。
AM失败后,RM负责创建一个新的MR AM。
RM收不到NM的心跳,会像AM报告,AM找新的节点运行失败的任务
离线计算框架MapReduce
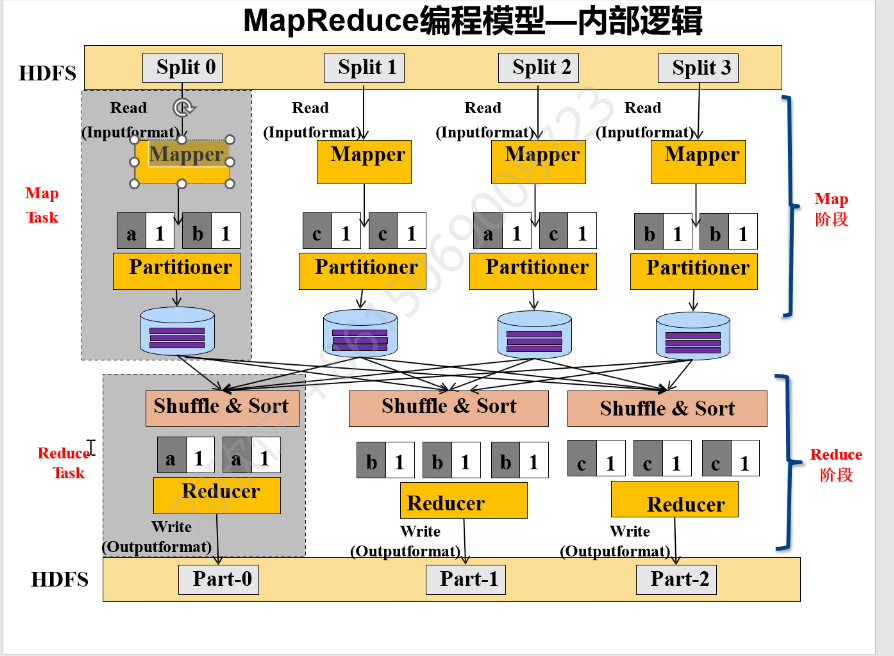
MapReduce工作过程
首先,将数据切片(片的大小跟数据块大小相同),分发到HDFS的不同节点。每个片有一个map task任务来处理,这个任务会调用map()函数,生成一系列中间键值对。为确保同样key(键)的数据到同一个reduce task,会将数据进行分区并排序。reduce task会主动询问哪个map任务完成了,并拉取自己想要的键值对应的分区的数据并归并(shuffle过程)。全部拉取完成后,reduce task会调用reduce()函数计算结果,最后将结果保存到HDFS。
shuffle阶段涉及大量网络I/O操作(从不同节点拉取数据),和磁盘I/O操作(边拉取边处理,会进行数据的归并以及溢写到磁盘),所以优化mapreduce主要是优化shuffle阶段。
MapReduce容错机制
Task失败后NM会将失败的任务告诉AM,AM决定如何处理失败的任务。
AM失败后,RM负责创建一个新的MR AM。
RM收不到NM的心跳,会像AM报告,AM找新的节点运行失败的任务
推测执行机制
作业完成时间取决于最慢完成时间,某个任务慢于其他,启动一个备份任务,同时运行。不能启用推测执行机制时机:负载倾斜严重,特殊任务(向数据库写数据)
Hive
Hive:数据分析工具,解决海量结构化数据分析。离线分析,自动生成map-reduce作业。是hql>map-reduce的解释器。可以用类sql语句进行对表的查询。
你只要知道,它的存在是为了简化我们的操作,毕竟sql语句我们都比较熟悉。