打开巨潮资讯的基金招募说明书页面:
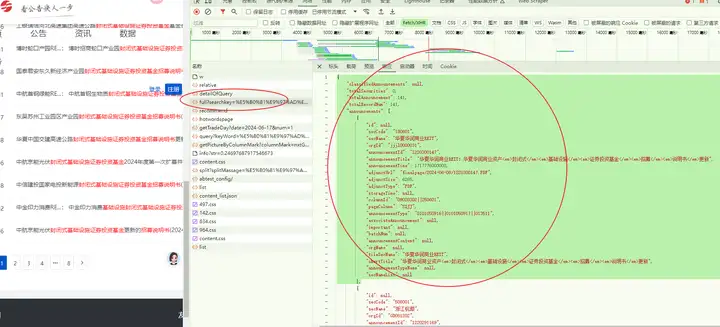
动态网页,返回json数据:
"adjunctUrl": "finalpage/2024-06-08/1220300147.PDF",
{
"classifiedAnnouncements": null,
"totalSecurities": 0,
"totalAnnouncement": 141,
"totalRecordNum": 141,
"announcements": [
{
"id": null,
"secCode": "180601",
"secName": "华夏华润商业REIT",
"orgId": "jjjl0000031",
"announcementId": "1220300147",
"announcementTitle": "华夏华润商业REIT:华夏华润商业资产<em>封闭式</em><em>基础设施</em><em>证券投资基金</em><em>招募</em><em>说明书</em>更新",
"announcementTime": 1717776000000,
"adjunctUrl": "finalpage/2024-06-08/1220300147.PDF",
"adjunctSize": 6265,
"adjunctType": "PDF",
"storageTime": null,
"columnId": "09020302||250601",
"pageColumn": "SZJJ",
"announcementType": "0101050916||0101050917||013511",
"associateAnnouncement": null,
"important": null,
"batchNum": null,
"announcementContent": null,
"orgName": null,
"tileSecName": "华夏华润商业REIT",
"shortTitle": "华夏华润商业资产<em>封闭式</em><em>基础设施</em><em>证券投资基金</em><em>招募</em><em>说明书</em>更新",
"announcementTypeName": null,
"secNameList": null
},
在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个批量下载网页PDF的Python脚本,具体步骤如下;
解析网页:http://www.cninfo.com.cn/new/fulltextSearch/full?searchkey=%E5%B0%81%E9%97%AD%E5%BC%8F%E5%9F%BA%E7%A1%80%E8%AE%BE%E6%96%BD%E8%AF%81%E5%88%B8%E6%8A%95%E8%B5%84%E5%9F%BA%E9%87%91%E6%8B%9B%E5%8B%9F%E8%AF%B4%E6%98%8E%E4%B9%A6&sdate=&edate=&isfulltext=false&sortName=pubdate&sortType=desc&pageNum={pagenumber}&pageSize=20&type=
{pagenumber}的值从1开始,以1递增,到8结束;
获取网站的响应,这是一个json数据;
提取"announcements"键的值,这个值也是一个json数据;
从这个json数据中提取"announcementTitle"键的值,作为PDF文件的标题,写入Excel表格第1列;
从这个json数据中提取"adjunctUrl"键的值,前面加上"http://static.cninfo.com.cn/",作为PDF文件的下载地址,写入Excel表格第2列;
保存Excel文件, Excel文件保存在文件夹:F:\AI自媒体内容\AI炒股\REITs,Excel文件名为:REITspdf.xlsx
注意:
每一步都输出信息到屏幕上,每一步添加调试信息,以便详细检查每一步是否正常工作;
每读取一页,随机暂停3-7秒;
PDF文件名要进行清洗处理,因为其中可能包含不符合windows系统命名规范的字符,处理文件名中的 HTML 实体,去除 <em> 和 </em> 标签,文件名中的特殊字符(如:)和无效字符替换为"_" 避免无效字符导致文件系统错误
设置请求标头:
Accept:
application/json, text/javascript, */*; q=0.01
Accept-Encoding:
gzip, deflate
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Connection:
keep-alive
Host:
Referer:
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
X-Requested-With:
XMLHttpRequest

这样就把所有说明书的名称和下载地址获取到了,然后导入迅雷批量下载。
下载完成后,进行重命名,在chatgpt中输入提示词:
你是一个Python编程专家,要完成一个批量重命名的Python脚本,具体步骤如下;
逐个读取文件夹里面的PDF文件:D:\文档任务组_20240617_1112,获取PDF文件主文件名,设为变量{pdfname1};
读取Excel文件:"F:\AI自媒体内容\AI炒股\REITs\REITspdf.xlsx"第2列全部内容,提取第三个"/"和".PDF"之间的内容,设为变量{pdfname2},比如:http://static.cninfo.com.cn/finalpage/2022-08-02/1214190987.PDF,应该提取的内容是"1214190987";
将{pdfname1}与所有的{pdfname2}进行比较,如果两者一致,那么用{pdfname2}所对应的第1列单元格内容作为新的PDF主文件名,重命名这个PDF文件;
注意:
每一步都输出信息到屏幕上,每一步添加调试信息,以便详细检查每一步是否正常工作;