1. 概述
论文地址:https://arxiv.org/pdf/2312.05468.pdf
随着人工智能潜力的不断扩大,人工智能(AI)在化学领域的应用也在迅速发展。特别是大规模语言模型的出现,极大地扩展了人工智能在化学研究中的作用。由于这些模型具有支持化学研究中各种任务的超强能力,并且能够轻松地使用自然语言进行 "编程 "或 "教学",因此备受关注。现在,大规模语言模型已从纯文本发展到多模态,可处理多种信息,成为应用广泛的强大而有用的人工智能助手。
GPT-4V 是这一演变的先驱。V "代表了它的视觉能力,它理解视觉和文本信息的能力远远超过了传统模型,能够从科学文献的图表中发现并分析有价值的数据。GPT-4V 的这一能力意味着,即使没有专业编程知识或计算机视觉技能的研究人员也能使用它,而且研究人员还可以通过定制指令来使用它。
本文展示了 GPT-4V 如何应用于网状化学研究。GPT-4V 能够整合和解释科学论文中的文字和图表数据,极大地提高了关键信息的提取和分析能力,尤其是从图表内容中读取物理特性结果的重要性。这种方法并不局限于网状化学,表明自动文献分析可以扩展到其他科学学科。
GPT-4V 的推出表明,人工智能可以进一步加强其在促进科学创新和发现方面的作用,缩小先进计算工具与前沿化学研究之间的差距。
2. 对 GPT-4V 性能的初步评估
在此,我们通过识别和解释网状化学文献中常见的图表来评估 GPT-4V 的性能。我们尤其关注氮等温线、粉末 X 射线衍射 (PXRD) 图样、热重分析 (TGA) 曲线、核磁共振 (NMR) 和红外光谱以及散点图、柱状图、二维和三维分子结构等各种图表,以了解 GPT-4V 是否能充分解释这些图表。该项目基于以下研究。此外,我们还分析了实验图像,包括合成方案、显微镜和扫描电子显微镜(SEM)图像。下图就是一个例子。
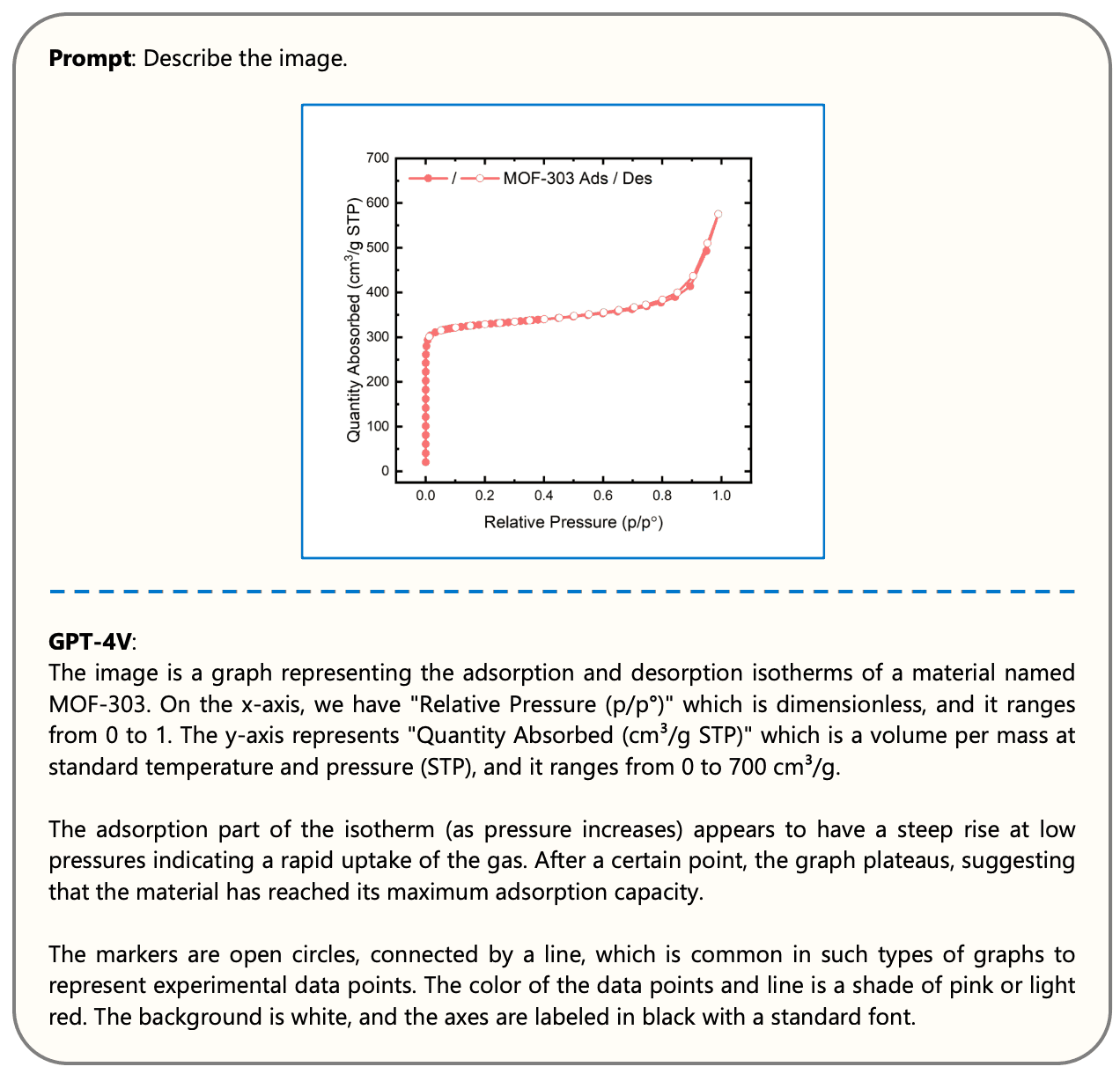
当被要求对每个图表进行详细描述时,GPT-4V 不仅能准确地对图像进行分类,还能深入浅出地讲述具体细节,包括注释、坐标轴范围、颜色编码、符号和线条形状、标签和图例,令人印象深刻。他们还能根据提供的图表说明信息进行推断。这种先进的上下文数据解读和综合分析功能凸显了 GPT-4V 作为强大的人工智能助手在科学文献图像和数据挖掘方面的适用性。
3. 及时设计页面内容标签
本文的目的是测试 GPT-4V 能否自主浏览科学文章、识别特定信息、将其编译成综合数据集并进行分析。本文特别关注显示金属有机框架(MOFs)物理性质的关键图表--氮等温线、粉末 X 射线衍射(PXRD)图、热重分析(TGA)曲线、晶体结构和拓扑图以及其他气体吸附等温线。这些图表对于阐明化合物的重要特性至关重要,如永久孔隙率、结晶度、热稳定性、拓扑结构和对气体的选择性。从这些图表中有效提取信息,并将其整合到大量文献中,对于提高我们对结构-性质关系的理解和加速新化合物的发现具有巨大潜力。
为实现这一目标,我们使用 GPT-4V 设计了针对上述类别的特定提示。这些提示考虑到了由于科学文献中常见的不同图和表并存的情况,一个页面上可能存在多个选项。此外,如果缺少某个类别,GPT-4V 也会明确指出缺少该类别。因此,GPT-4V 共有六个选项。这些提示的开发遵循文本挖掘提示工程的基本原则。下图为其概览。
4. GPT-4V 的性能评估
在这里,GPT-4V 对所选文献的每一页进行成像和分析。具体来说,GPT-4V 将页面图像与专门设计的文本提示相结合,并收集回复,从而自动对内容进行分类,并识别出包含情节的页面,以便进行深入分析。这一过程允许 GPT-4V 遵循特定的回复格式,并根据内容自动标记每一页。
GPT-4V 可准确识别每一页上所需的情节,无论信息的复杂程度如何、展示标注能力。
为了评估 GPT-4V 的分类准确性,我们将其与地面实况数据集进行了比较,地面实况数据集包含由网状化学专家人工审核和标注的 6,240 张图像。结果显示,除 "其他气体吸附等温线 "外,所有类别的准确率都超过 94%,但准确率、召回率和 F1 分数都在 87% 到 99% 之间。该类别的准确率较低,可能是由于提示说明不充分以及红外光谱和核磁共振光谱偶尔出现标记错误,这表明有机会进一步完善提示的针对性。
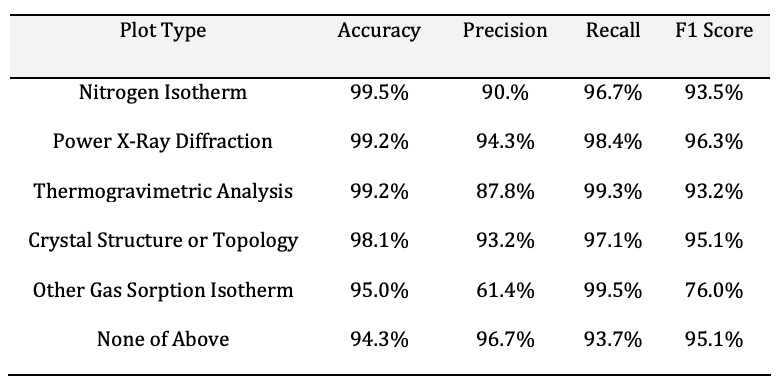
GPT-4V 的性能在网络接口和应用程序接口中也显示出相似的准确率,再次证明了基础模型的一致性。

这一自动化流程提供了多种操作选项,并能高效地从文献中收集信息。混淆矩阵分析显示了 GPT-4V 在大量文献中识别出氮等温线、PXRD 图样和 TGA 曲线的页数。

此外,许多页面被归类为缺乏感兴趣的情节,这可能有助于研究人员今后简化某些类型文献情节的审查过程。
5. 利用 GPT-4V 解释氮等温线数据
本节将探讨在成功标注页面内容后,如何使用 GPT-4V 对以氮等温线图为特色的页面进行详细解读和分析。对提示策略进行了改进,加入了更多特定语言,指导 GPT-4V 识别氮等温线,并从每个图中提取和报告关键信息。

其中包括图号、化合物名称、表面积和孔体积值、吸附-解吸曲线是否存在滞后现象、等温线的饱和高原以及对图周围边框的估计。

这种方法的关键在于指示 GPT-4V 只使用页面图像上的可用信息,而 "N/A "则表示数据不可用。因此,GPT-4V 通过分析等温线及其相关坐标轴、图例和文本内容,显示出高效提取这些细节的能力,令人印象深刻。
为了确认 GPT-4V 分析的准确性,我们对所选论文中超过 200 页的反应(包括氮等温线)进行了人工审核。特别是在图号、化合物名称和孔隙度分析方面,观察到了很高的准确性。这表明,GPT-4V 在图像处理功能中可能使用了光学字符识别 (OCR) 工具。此外,GPT-4V 对文本的高熟练度似乎对与可直接从图像中读取的文本信息相关的任务产生了积极影响。
然而,对于其他三个描述符,如是否存在滞后、饱和高原和边界框估计,其性能总体上令人满意,从 76.25% 到 84.58%不等。这些任务是更高级、更微妙的挑战,需要对所有图像元素进行全面分析。尽管如此,总体性能还是特别令人印象深刻,而且研究人员可以用自然语言对 GPT-4V 进行简单的指导,这进一步凸显了该技术的强大功能。
6. 加速网状化学数字数据库
在此,我们探讨了使用 GPT-4V 简化网状化合物详细数据库构建的可能性。特别是,我们根据科学界发表的文献中的实验结果,识别出具有独特氮等温线图的网页,并使用 WebPlotDigitizer 等工具仔细提取这些通常为非数字格式的数据。通过这一过程,提取的数据被系统地编译并存储到数据库中。这种方法提供了一个收集氮等温线数据点的实际例子,显示了各种等温线类型和孔隙度特征。

此外,还利用 CoRE MOF 数据库来匹配论文中讨论的化合物的计算结果和实验结果,从而对理论值和实验值进行比较。在这项分析中,将每种化合物的理论值与实验得出的表面积和孔隙率绘制成散点图,从而揭示化合物之间的一般趋势。
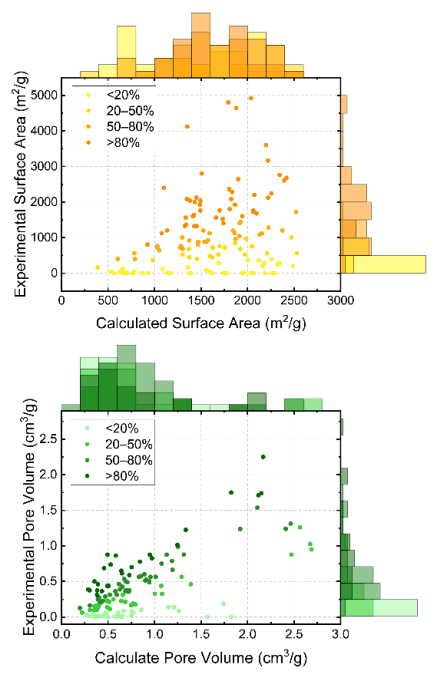
比较结果表明,即使是在实验确定的结构基础上,理论预测和实验结果之间也存在差异。这凸显了在选择材料时完全依赖计算结果的风险。
这项研究的启示表明,GPT-4V 不仅适用于网状化学,还适用于广泛的科学学科。娴熟的提示设计对于有效的数据库建设至关重要,而 DSPy 等创新工具的引入则有可能进一步改进研究过程,加快自然语言处理工具的发展。这一进步有望扩大文献数据挖掘的范围,并进一步增加人工智能工具在科学研究中的应用。
7. 总结
本文展示了GPT-4V 在网状化学领域的文本、图像和数据挖掘方面的作用。它重点介绍了 GPT-4V 使用独特设计的提示处理页面图像的能力,并成功识别和分类了包含所需信息的准确页面。值得注意的是,它表明这种方法可能不仅适用于网状化学,也适用于其他科学领域。
GPT-4V 等大型语言模型可以使用通常使用的自然语言进行 "编程",消除了编码技术和特殊模型学习识别特定图表和图形的障碍。这种灵活性强调了一个事实,即只需对提示进行简单修改,就可以将分析从 TGA 曲线等转移到水等温线等完全不同的数据类型 。
此外,还建议整合 DSPy 等先进平台,使 GPT-4V 的使用更加有效。预计这将为科学数据挖掘开辟新的可能性,并使人工智能成为开发科学知识过程中更容易获取和使用的工具。这种方法有望大大提高科学研究领域的工作效率,并为从文献中提取更多数据提供机会。