
深入分析GPT-4o与其他顶级语言模型ChatGPT、Gemini的性能表现
OpenAI最近发布的GPT-4o标志着AI语言模型互动方式的新纪元。在现场演示中,尽管出现了一些小插曲,但支持与ChatGPT进行实时互动和会话中断的功能令人印象深刻。最重要的是,演示结束后,OpenAI立即开放了GPT-4o的API访问权限。在本文中,我将对GPT-4o、GPT-4以及Google的Gemini和Unicorn模型进行独立的性能分析,测量它们在英语理解方面的分类能力。
GPT-4o的革新之处

GPT-4o作为一种全新的全能模型,能够无缝理解和处理文本、音频和视频。OpenAI的重点似乎转向了将GPT-4级别的智能普及到大众,使即使是免费用户也能获得GPT-4级别的语言模型智能体验。GPT-4o还提升了在超过50种语言中的质量和速度,承诺提供更具包容性和全球化的AI体验,同时价格更低。此外,付费订阅用户将获得比非付费用户多五倍的使用容量。OpenAI还计划推出桌面版ChatGPT,以便大众可以在音频、视觉和文本界面之间进行实时推理。
GPT-4o API的使用方法
新的GPT-4o模型遵循现有的OpenAI聊天完成API,确保向后兼容性和简便使用。用户可以通过API轻松集成和利用GPT-4o的强大功能。
py
from openai import OpenAI
OPENAI_API_KEY = "<your-api-key>"
def openai_chat_resolve(response: dict, strip_tokens = None) -> str:
if strip_tokens is None:
strip_tokens = []
if response and response.choices and len(response.choices) > 0:
content = response.choices[0].message.content.strip()
if content is not None or content != '':
if strip_tokens:
for token in strip_tokens:
content = content.replace(token, '')
return content
raise Exception(f'Cannot resolve response: {response}')
def openai_chat_request(prompt: str, model_name: str, temperature=0.0):
message = {'role': 'user', 'content': prompt}
client = OpenAI(api_key=OPENAI_API_KEY)
return client.chat.completions.create(
model=model_name,
messages=[message],
temperature=temperature,
)
response = openai_chat_request(prompt="Hello!", model_name="gpt-4o-2024-05-13")
answer = openai_chat_resolve(response)
print(answer)在ChatGPT中也可以使用GPT-4o
官方评估
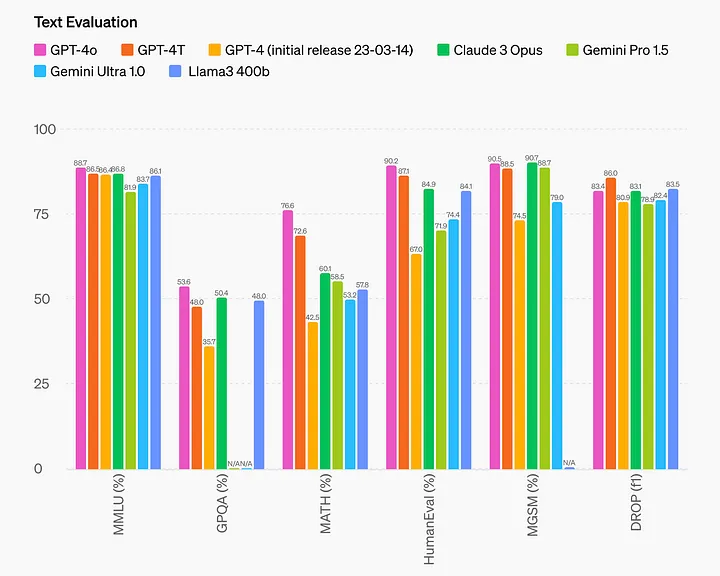
OpenAI的博客文章中包含了已知数据集(如MMLU和HumanEval)的评估分数。根据这些评估,GPT-4o的性能在这一领域可以归类为最先进的,这一表现非常令人期待,尤其考虑到新模型更加便宜和快速。然而,许多模型声称在已知数据集上具有最先进的语言性能,但实际上,这些模型可能在这些公开数据集上进行了部分训练(或过拟合),导致排行榜上的分数不真实。因此,使用不太知名的数据集进行独立分析是非常重要的。
评估的模型
对以下模型进行评估:
- GPT-4o: gpt-4o-2024-05-13
- GPT-4: gpt-4-0613
- GPT-4-Turbo: gpt-4-turbo-2024-04-09
- Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
- Gemini 1.0: gemini-1.0-pro-002
- Palm 2 Unicorn: text-unicorn@001
任务是让这些语言模型将数据集中的每个句子与正确的主题匹配,从而计算每个模型的准确率和错误率。由于模型大多分类正确,我们绘制了各模型的错误率条形图。记住,较低的错误率表明模型性能更好。
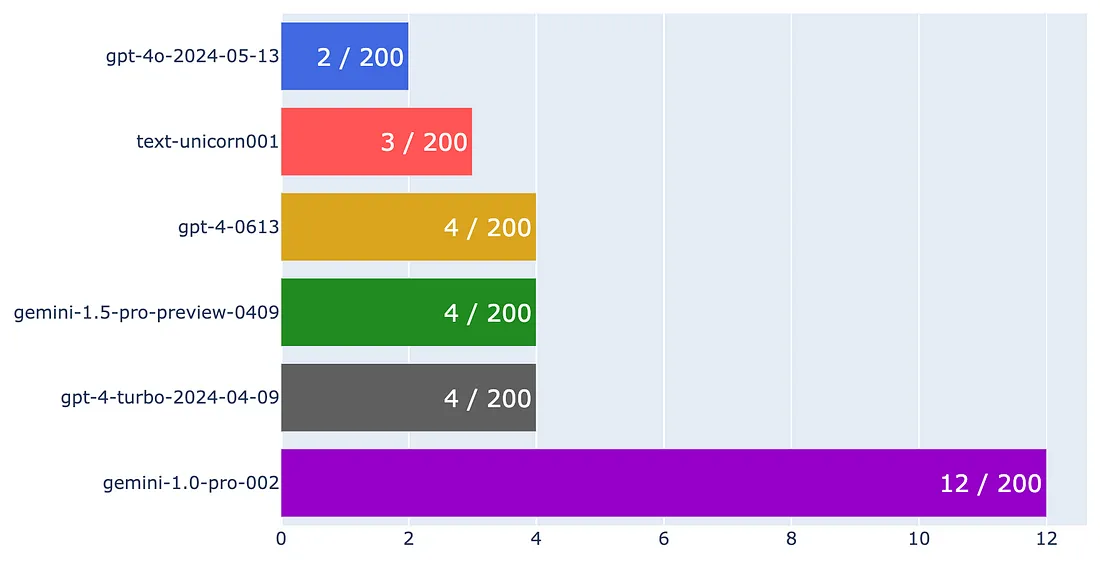
错误率横向条形图
从图表中可以看出,GPT-4o的错误率最低,仅有2个错误。Palm 2 Unicorn、GPT-4和Gemini 1.5紧随其后,展示了它们的强大性能。值得注意的是,GPT-4 Turbo的表现与GPT-4-0613相似。有关更多信息,请查看OpenAI的模型页面。最后,Gemini 1.0的表现落后,这是可以预期的,考虑到其价格范围。
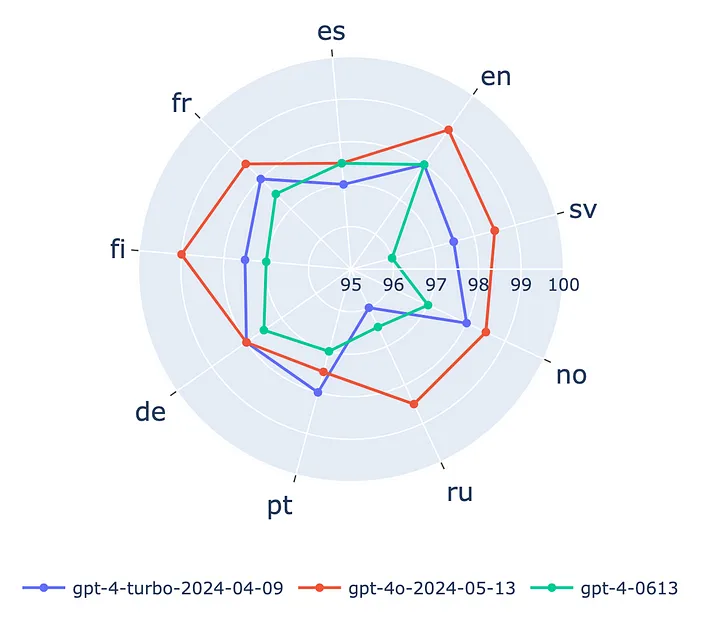
多语言能力
最近的研究成果表明,GPT-4o与其他LLM(如Claude Opus和Gemini 1.5)的多语言能力相比,要更强大。
结论
通过使用独特的英语数据集进行的分析揭示了这些先进语言模型的最先进能力。GPT-4o作为OpenAI最新的产品,以最低的错误率在测试模型中脱颖而出,证实了OpenAI关于其性能的声明。AI社区和用户必须继续使用多样化的数据集进行独立评估,这有助于提供模型实际有效性更清晰的图景,而不仅仅是标准化基准测试所显示的结果。
总的来说,GPT-4o的表现展示了AI语言模型发展的新高度,未来我们期待更多的技术创新和改进。