
1. 前言
MySQL 作为最最常用的数据库,了解 Mysql 的分布式策略对于掌握 MySQL 的高性能使用方法和更安全的储存方式有非常重要的作用。
它同时也是面试中最最常问的考点,我们这里就简单总结下 Mysq 的常用分布式策略。
2. 复制
复制主要有主主复制和主从复制两种
mysql 的复制功能都是基于 bin-log 实现的
2.1. 经典主从复制
这里使用 docker 实验,生产环境尽量不要使用 docker
我这里使用默认网络,即
网桥模式测试就足够了
准备主从复制 my.cnf
powershell
mkdir /volume1/docker/mysql-master
mkdir /volume1/docker/mysql-master/data
mkdir /volume1/docker/mysql-slave
mkdir /volume1/docker/mysql-slave/data
powershell
# /volume1/docker/mysql-master/my.cnf 主mysql配置
[mysqld]
server-id=1
log-bin=mysql-bin
# /volume1/docker/mysql-slave/my.cnf 从mysql配置
[mysqld]
server-id=2
log-bin=mysql-bin- 搭建主从MySQL
powershell
# volume1/docker/mysql-master 是你的数据存储卷
# 这里密码设置为123456
docker run -d \
--name mysql-master \
-v /volume1/docker/mysql-master/data:/var/lib/mysql \
-v /volume1/docker/mysql-master/my.cnf:/etc/mysql/conf.d/my.cnf \
-e MYSQL_ROOT_PASSWORD=123456 \
mysql:8.0.11
docker run -d \
--name mysql-slave \
-v /volume1/docker/mysql-slave/data:/var/lib/mysql \
-v /volume1/docker/mysql-slave/my.cnf:/etc/mysql/conf.d/my.cnf \
-e MYSQL_ROOT_PASSWORD=123456 \
mysql:8.0.11- 主 MySQL 配置
powershell
docker exec -it mysql-master /bin/bash
mysql -u root -p
SHOW MASTER STATUS;

然后创建同步用户
powershell
CREATE USER 'repluser'@'%' IDENTIFIED WITH mysql_native_password BY 'replpassword';
GRANT REPLICATION SLAVE ON *.* TO 'repluser'@'%';
FLUSH PRIVILEGES;
- 获取主Mysql ip
powershell
docker inspct mysql-master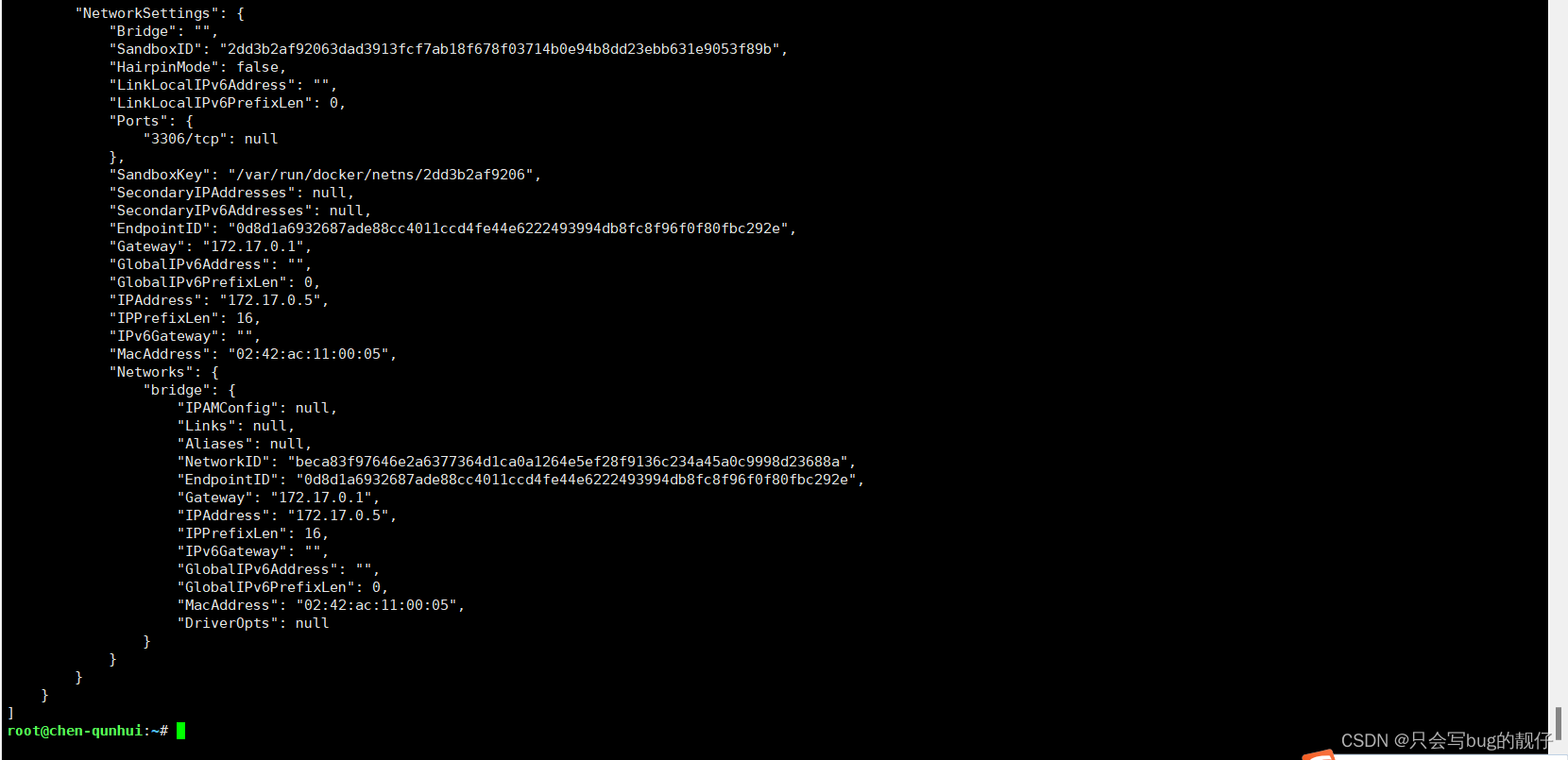
我这里看到的是172.17.0.5
- 配置从 MySQL
这里主要是配置主 Mysql 的账号密码,主服务器的偏移量和 bin 位置
powershell
docker exec -it mysql-slave /bin/bash
mysql -u root -p
CHANGE MASTER TO
MASTER_HOST='172.17.0.5',
MASTER_USER='repluser',
MASTER_PASSWORD='replpassword',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=852;
START SLAVE;- 查询链接状态
这里主要看有没有报错,没报错就可以了
powershell
SHOW SLAVE STATUS\G;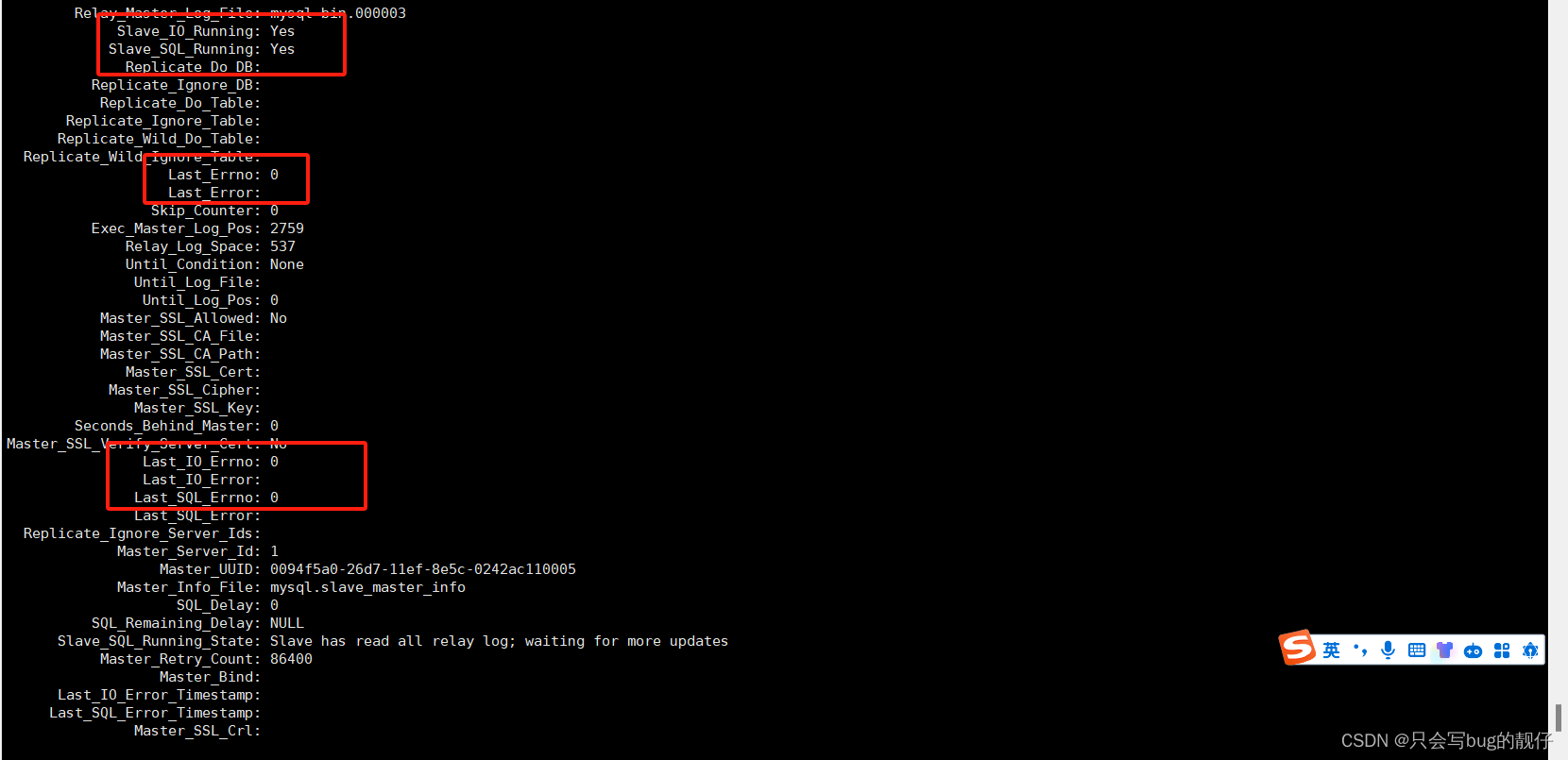
- 测试同步
我们首先在master mysql 随便创建一个test数据库
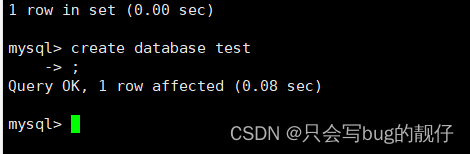
然后我们发现在从数据库。就可以发现 test 数据库了。

2.2. 主主复制
主主同步相对来说使用少一点,因为保证一致性更加困难,增加了维护成本
前提条件
- 安装两个MySQL实例,并确保它们可以相互连接。
- 每个MySQL实例有一个唯一的
server-id。 - 启用二进制日志(binlog)。
步骤
配置第一台服务器(Server A)
- 编辑配置文件
my.cnf:
ini
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-do-db=your_database # 需要复制的数据库`- 重启MySQL服务:
shell
service mysql restart- 创建复制用户:
sql
CREATE USER 'repl'@'%' IDENTIFIED WITH 'mysql_native_password' BY 'replpassword'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; FLUSH PRIVILEGES;- 获取二进制日志文件名和位置:
SQL
SHOW MASTER STATUS;记录下File和Position,如mysql-bin.000001和154。
配置第二台服务器(Server B)
- 编辑配置文件
my.cnf:
ini
[mysqld]
server-id=2
log-bin=mysql-bin
binlog-do-db=your_database
# 需要复制的数据库- 重启MySQL服务:
shell
service mysql restart- 创建复制用户:
SQL
CREATE USER 'repl'@'%' IDENTIFIED WITH 'mysql_native_password' BY 'replpassword'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; FLUSH PRIVILEGES;- 获取二进制日志文件名和位置:
sql
SHOW MASTER STATUS;记录下File和Position,如mysql-bin.000001和154。
配置双向复制
- 在第一台服务器(Server A)上配置从服务器(Server B):
sql
sql
CHANGE MASTER TO MASTER_HOST='ServerB_IP', MASTER_USER='repl', MASTER_PASSWORD='replpassword', MASTER_LOG_FILE='mysql-bin.000001', -- Server B的binlog文件名 MASTER_LOG_POS=154; -- Server B的binlog位置 START SLAVE;- 在第二台服务器(Server B)上配置从服务器(Server A):
sql
CHANGE MASTER TO MASTER_HOST='ServerA_IP', MASTER_USER='repl', MASTER_PASSWORD='replpassword', MASTER_LOG_FILE='mysql-bin.000001', -- Server A的binlog文件名 MASTER_LOG_POS=154; -- Server A的binlog位置 START SLAVE;验证配置
- 在第一台服务器(Server A)上检查复制状态:
sql
复制代码
SHOW SLAVE STATUS\G;
- 在第二台服务器(Server B)上检查复制状态:
sql
`SHOW SLAVE STATUS\G;`确保Slave_IO_Running和Slave_SQL_Running均为Yes,并且Last_IO_Error为空。
整体思路和主从一直,不过要互相复制,且容易出现问题,未还难度大
3. 其他方案
如MySQL InnoDB Cluster,MySQL InnoDB Cluster,Keepalived 和 MHA,Galera
Cluster 很多分布式方案。
3.1. innoDB Cluster
MySQL InnoDB Cluster 是一个官方提供的高可用性和可扩展性解决方案,基于MySQL组复制(Group Replication)、MySQL Shell和MySQL Router。
优点:
高可用性和自动故障切换。
易于配置和管理,官方支持。
读写分离和负载均衡。
3.2. ProxySQL
使用场景:读写分离、负载均衡、高可用性。
优点:高性能代理,支持动态配置和多个后端数据库。
缺点:需要额外的代理层,配置复杂。
3.3. Galera Cluster
使用场景:多主同步复制、高可用性。
优点:数据同步、强一致性、高可用性。
缺点:网络要求高,延迟敏感。
3.4. Sharding(分片)
使用场景:大规模数据处理和存储,水平扩展。
优点:没有单点瓶颈,扩展性好。
缺点:应用层处理复杂,跨分片查询困难。
3.5 NDB Cluster
使用场景:高性能、高可用性、高可扩展性。
优点:数据分片、负载均衡、高可用性。
缺点:配置复杂,硬件要求高。