一、同步需求背景
在实际企业应用中,常遇到需要将MySQL数据库中的数据实时同步到SQL Server的场景。这种需求可能源于业务系统整合、数据仓库构建、报表系统升级或特定应用对SQL Server的依赖。实时同步要求数据在源数据库发生变化后,能在较短时间内(通常秒级)反映到目标数据库中。
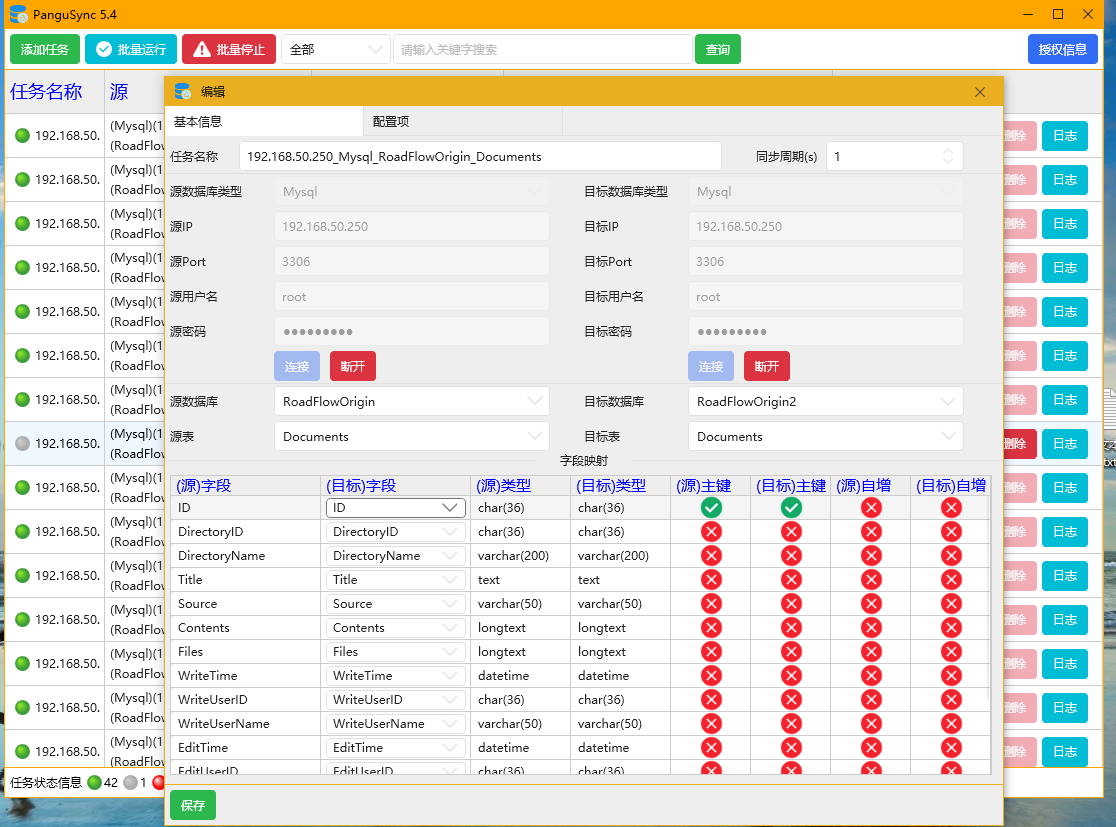
二、主流技术方案
1. 基于数据库日志的变更数据捕获(CDC)
通过解析MySQL的二进制日志(binlog)来捕获数据变更,然后将这些变更应用到SQL Server。这是实现实时同步最直接有效的方法:
-
MySQL端配置:确保binlog格式为ROW模式,这是捕获行级变更的必要条件
-
日志解析工具:使用开源工具如Debezium、Maxwell或Canal解析binlog
-
数据转换层:处理数据类型映射、字符集转换等差异
-
SQL Server写入:将转换后的数据应用到目标数据库
2. 基于触发器的中间表方案
在MySQL中创建触发器,将变更写入中间表或消息队列,然后由同步程序处理:
-- MySQL端示例触发器
CREATE TRIGGER sync_trigger AFTER INSERT ON source_table
FOR EACH ROW
BEGIN
INSERT INTO change_log(table_name, operation, data, timestamp)
VALUES ('source_table', 'INSERT', JSON_OBJECT('id', NEW.id, ...), NOW());
END;3. 使用ETL工具实现
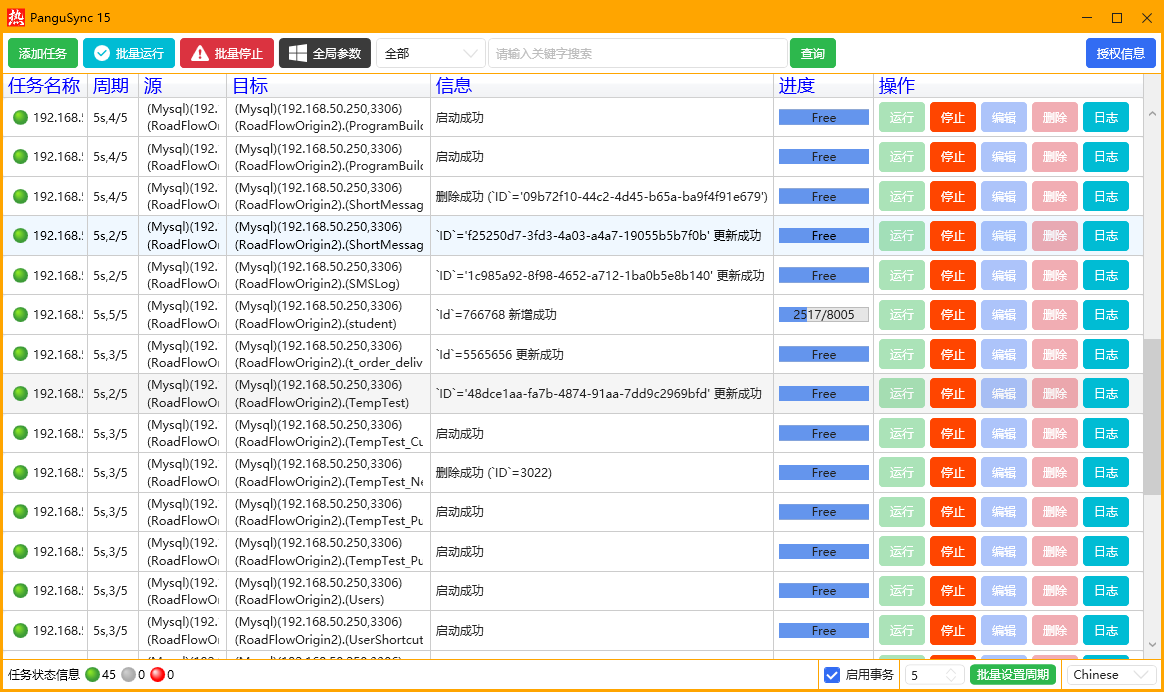
成熟的ETL工具提供了可视化配置界面和稳定的同步机制:
-
Apache NiFi:提供数据库连接处理器和可配置的数据流
-
Talend:商业ETL工具,支持多种数据库的实时同步
-
Kettle (Pentaho Data Integration):开源ETL解决方案
三、具体实现步骤
第一阶段:环境准备与配置
-
MySQL配置
-
启用二进制日志:
log-bin=mysql-bin -
设置binlog格式:
binlog_format=ROW -
配置server-id保证唯一性
-
-
SQL Server准备
-
创建目标数据库和表结构
-
考虑字符集兼容性(UTF-8到SQL Server的NVARCHAR)
-
建立适当的索引以优化写入性能
-
第二阶段:同步架构搭建
推荐使用Debezium + Kafka + 自定义连接器的架构:
-
Debezium MySQL连接器:监控MySQL的binlog变化
-
Apache Kafka:作为消息中间件,缓冲数据变更
-
自定义SQL Server连接器:消费Kafka消息并写入SQL Server
第三阶段:数据类型映射处理
MySQL与SQL Server的数据类型差异需要特别注意:
-
数值类型:BIGINT → BIGINT,DECIMAL → DECIMAL
-
字符串类型:VARCHAR → NVARCHAR,TEXT → NVARCHAR(MAX)
-
时间类型:DATETIME → DATETIME2,TIMESTAMP → DATETIME2
-
布尔类型:TINYINT(1) → BIT
四、工具对比与选择
| 工具/方案 | 实时性 | 复杂度 | 资源消耗 | 适用场景 |
|---|---|---|---|---|
| Debezium+Kafka | 秒级 | 高 | 中高 | 大规模、高并发 |
| Canal+客户端 | 秒级 | 中 | 中 | 中小规模同步 |
| 存储过程+链接服务器 | 分钟级 | 低 | 低 | 小数据量、低频同步 |
| 商业ETL工具 | 可配置 | 低 | 中 | 企业级、多数据源 |
五、注意事项与优化建议
-
网络与性能考量
-
确保MySQL和SQL Server之间的网络延迟可控
-
批量写入SQL Server以提高效率
-
合理设置事务提交频率
-
-
错误处理机制
-
实现重试逻辑和死信队列
-
记录详细同步日志便于排查
-
设计数据校验和修复机制
-
-
数据一致性保证
-
定期全量校验数据一致性
-
实现断点续传,避免数据丢失
-
考虑使用幂等性写入操作
-
-
监控与告警
-
监控同步延迟指标
-
设置数据积压告警阈值
-
监控系统资源使用情况
-
六、实际部署案例
某中型电商平台需要将订单数据从MySQL实时同步到SQL Server报表系统,采用以下方案:
-
使用Debezium捕获MySQL订单表变更
-
通过Kafka传输变更事件
-
自定义.NET Core服务消费Kafka消息
-
使用Dapper将数据批量写入SQL Server
-
实现延迟监控面板,保证99.9%的同步在3秒内完成
结语
MySQL到SQL Server的实时同步是一个典型的异构数据库同步场景,需要综合考虑数据一致性、系统性能和技术复杂度。选择合适的工具架构并做好异常处理,可以构建稳定可靠的同步系统。随着技术的发展,现在有更多的开源工具和云服务可以简化这一过程,但基本原理和注意事项仍然值得深入理解。