文章目录
- [第一章 绪论](#第一章 绪论)
- 安全存储与访问控制技术
- 安全检索技术
- 安全处理技术
- 隐私保护技术
第一章 绪论
大数据概述
大数据的数据源可以分为 结构化数据 、 非结构化数据 、 半结构化数据
大数据生命周期分为 数据采集 、 数据传输 、 数据存储 、 数据分析与使用 四个阶段
物联网 作为大数据量的第一来源,大数据采集的第一步是 数据清洗
大数据安全与加密技术
从 大数据安全 角度考虑,优先使用 访问控制技术 与 加密技术
从 大数据隐私保护 角度考虑,优先使用 隐私保护技术
-
基于大数据的威胁发现技术要求有:
- 分析内容的范围更大
- 分析内容的时间跨度更长
- 对攻击威胁具有预测性
- 对未知威胁的检测
-
基于大数据的认证技术优点有:
- 攻击者很难模拟用户的行为特征来通过认证,安全性更高
- 减小用户负担
- 更好的支持各系统认证机制的统一
- 安全加密模型中存在 明文 、 密文 、 密钥 、 加密算法 等元素
加密技术按类型可以分为 对称加密 和 非对称加密
数字信封 使用 非对称加密 中的 公钥 进行加密 可以保证信息完整性
数字签名 使用 非对称加密 中的 私钥 进行加密 可以防止信息发送方的抵赖行为
安全存储与访问控制技术
访问控制概念
对资源对象的访问者授权、控制的方法及运行机制。
访问主体/访问者:能够发起对资源的访问请求的主动实体,通常为系统的用户或进程
访问客体/资源对象:能够被操作的实体,通常是各类系统和数据资源
授权:访问者可以对资源对象进行访问的方式,如读、写、删除
控制:对访问者使用方式的监测和限制,对是否许可用户访问资源对象作出决策。如允许、禁止等
早期的四种访问控制模型
早期的四种访问控制模型分别是:
- 自主访问控制(DAC)
采用这种方法时,受保护系统、数据或资源的所有者或管理员可以设置相关策略,规定可以访问的人员。 - 强制访问控制(MAC)
这种非自主模型则会根据信息放行来授予访问权限。中央机构根据不同的安全级别来管理访问权限,此模型在政府和军事环境中非常常见。 - 基于角色的访问控制(RBAC)
RBAC 根据定义的业务功能而非个人用户的身份来授予访问权限。这种方法的目标是为用户提供适当的访问权限,使其只能够访问对其在组织内的角色而言有必要的数据。这种方法是基于角色分配、授权和权限的复杂组合,使用非常广泛。 - 基于属性的访问控制(ABAC)
这种动态方法会基于一系列属性和环境条件(例如时间和位置)向用户和资源分配访问权限。
自主访问控制的实现方式有两种,包括 能力表 和 访问控制列表
强制访问控制最经典的有 BLP模型 和 Biba模型
基于角色访问控制 最基本的RBAC0模型定义了 用户 、角色 、会话和访问权限 。
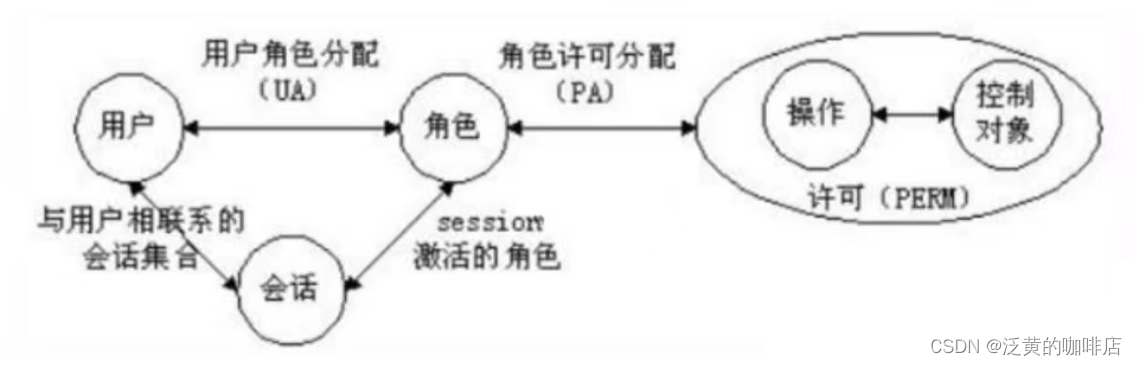
基于角色的访问控制 用户和角色 之间是 多对多 的映射关系
基于角色的访问控制 角色和权限 之间是 多对多 的映射关系
局限性总结
早期访问控制模型和技术在大数据应用场景下主要存在三方面问题:
安全管理员的授权管理难度更大:
大数据规模和增长速度导致安全管理员工作量大;
大数据应用环境,使得安全管理员必须具备更多的领域知识来实施权限管理。
严格的访问控制策略难以适用:
访问需求无法预知;
访问需求动态变化。
外包存储环境(即数据所有者和数据存储服务提供者是不同的)下无法使用:
数据所有者不具备海量存储能力;
数据所有者不具备构建可信引用监控机的能力。
大数据场景下的访问控制技术
- 大数据场景下的角色挖掘技术实现方式有两种:
- 基于层次聚类的角色挖掘方法
- 生成式角色挖掘方法
风险量化:是将访问行为对系统造成的风险进行数值评估,并且以组织过程资产文件作为量化标准
风险自适应的访问控制方案实施:以静态规则优先 、 风险控制之后控制的结果更多的结论是允许访问
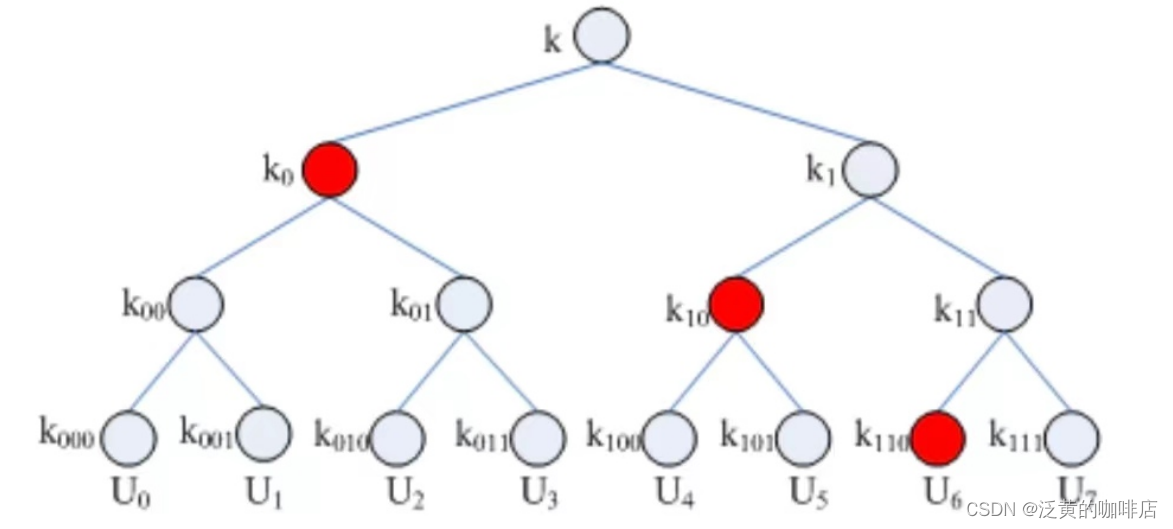
基于单发送者广播加密的访问控制如图所示:红点代表解密文件,则U7将无法解密数据
安全检索技术
云存储是云计算衍生的概念,它将数据的 所有权 和 管理权 分离,导致用户数据将面临多方面威胁。
密文检索基础
密文检索主要涉及 数据所有者、数据检索者、服务器 3种角色
- 密文检索流程大致分为以下4个步骤:
- 构造索引
- 生成陷门 陷门(我愿称之为后门🚪)是在某个系统或某个文件中设置的"机关",使得在提供特定的输入数据时,允许违反安全策略。例如,一个登录处理子系统允许处理一个特定的用户识别码,以绕过通常的口令检查。
- 服务器使用陷门和索引进行运算,检索符合条件的密文
- 数据检索者获得匹配的密文(需要时可在本地进行二次检索)
对称密文检索的特点:检索者和数据所有者为同一人。适合 单用户场景 ,高效。
非对称密文检索:适用于多用户场景,相对低效
根据数据类型的不同,密文检索技术可以分为 关键词检索 和 区间检索
PIR(隐私信息获取)指用户在不向远端服务器暴露查询意图的前提下对服务器的数据进行查询并获得指定数据的方法;
ORAM(不经意RAM或健忘RAM)在读写过程中向服务器隐藏访问模式等;
前者关注用户访问模式,后者关注数据机密性。
SPIR技术将保护的范围扩大到了服务器
- 对称密文检索方案包括如下算法:
- Setup(初始化)
- Buildindex(建立索引)
- GenTrapDoor(生成陷门)
- Search(搜索)
布隆过滤器(Bloom)算法类似一个HashSet, 用来判断某个元素是否在某个集合中。Bloom不需要存储元素的值, 而是对于每个元素用k个比特位来存储其标志,用来判断元素是否在集合中。它可以判断出某个元素肯定不在集合里或者可能在集合里,即它不会漏报,但可能会误报。
语义安全:表示为攻击者即使已知某个消息的密文,也得不出该消息的任何部分信息,即使是1比特的信息。
查询历史:指的是文档以及查询关键词列表
模糊检索:允许检索关键词出现拼写错误或包含通配符的情况
-
非对称密文检索方案:
- BDOP-PEKS拥有较低的通信量
- KR-Peks方案检索效率最优
- DS-PEKS检索加密效率最高
-
密文区间检索的几种技术优缺点分别是:
- 基于桶式索引的方案:安全程度难以证明,检索结果包含大量冗余数据
- 基于加密的方案:安全性较高,但是需要和服务器进行多轮交互,效率相对较低
- 基于谓词的加密方案:安全性较高但是操作为双线性映射,检索效率低,不适合高精度数据
- 基于矩阵加密方案:检索效率较高,适合处理高精度数据
- 基于等值检索方案:灵活性较大,容易将区间检索和关键词检索相结合
- 保序加密方案:密文泄露了明文的排序特征安全性较低,适合安全性不高的场景
安全处理技术
- 安全处理技术包括:
- 同态加密技术
- 可验证计算技术
- 安全多方计算技术
- 函数加密技术
- 外包计算技术
同态加密
- 同态加密方案通常由四个算法组成:
- Keygen(密钥生成算法,产生公钥私钥)
- Encrypt (加密算法)
- Decrypt (解密算法)
- Evaluate(同态加密计算)
比特承诺(Bit Commitment,BC)是指 数据发送者和数据接收者收发信息,数据接收者会无条件的相信发送者的 承诺数据 ,并在数据接收完整后验证信息,比特承诺有 隐藏性 和 绑定性 。
- 发送者 Alice 向接收者 Bob 承诺一个比特b (如果是多个比特,即比特串t ,则称为比特串承诺),要求:
- 在第 1 阶段即承诺阶段 Alice 向 Bob 承诺这 个比特b ,但是 Bob 无法知道b 的信息;
- 在第 2 阶段即揭示阶段 Alice 向 Bob 证实她在第 1 阶段承诺的确实是b ,但是 Alice 无法欺骗 Bob(即不能在第 2 阶段篡改b 的值)。
零知识证明:指的是证明者能够在不向验证者提供任何有用的信息的情况下,使验证者相信某个论断是正确的。需要以 比特承诺(BC) 作为基础协议。
隐私保护技术
- 隐私保护数据发布方案的构建包含四个参与方:
- 个人用户
- 数据采集/发布者
- 数据使用者
- 攻击者
在实际场景中,数据采集/发布者隐私保护方案可选择 在线模式 或 离线模式 。
-
用户隐私保护需求可以分为:
- 身份隐私
- 属性隐私
- 社交关系隐私
- 位置轨迹隐私
-
隐私保护技术分为:
- 抑制 通过将数据置空的方式限制数据发布
- 泛化 通过降低数据精度提供匿名的方法
- 置换 不改变数据内容,但改变数据的属主
- 扰动 数据发布时添加一定的噪声,对攻击者造成干扰
- 裁剪 将数据分开发布
链接攻击:是指通过背景知识迅速确定被隐藏身份ID标识性信息的记录
同质攻击:是指根据数据联想将目标信息去匿名化
在社交网络图中节点通常指的是 个人 或 组织
节点连接的 边数 称为节点的 度数
节点匿名方案常见的有 基于节点度数的K匿名模型 和 基于子图的K匿名模型
- 边匿名方案常见的有:
- 基于超级节点的边匿名方案
存在信息损失 结构损失描述信息损失 - 基于扰动的边匿名方案
LBS(Location-Based Service)是指服务提供商根据用户位置,提供相应的服务
在LBS隐私保护方案中,典型的两类方案是 mix-zone在网络中的应用 和 pir在近邻查询中的应用
- 基于超级节点的边匿名方案
马尔科夫模型:是指描述了一类随机过程,该过程的输出状态随时间变化,这些状态不是相互独立的,适用于基于用户活动规律的攻击
高斯模型:指的是数据的分布基本符合正态分布。
贝叶斯模型:指的是有条件的概率模型,依靠不确定事件的相关发生概率,来推测事件的概率。
差分隐私:是将数据通过算法进行匿名化。即使攻击者拥有一定背景知识(先验知识),攻击者查询公开数据库,只能获得全局统计信息(可能存在一定误差),无法精确到某一个具体的记录("自然人"的记录)。
将上面的段落按markdown格式总结