简介
Git 通过子模块来解决复用模块的问题。 submodule允许你将一个 Git 仓库作为另一个 Git 仓库的子目录。 它能让你将另一个仓库克隆到自己的项目中,同时还保持提交的独立。而subtree可以将子模块合并到主模块由主模块完全管理。
git subModule
Git地址:https://www.git-scm.com/docs/git-submodule
1、拉取子模块仓库
- git submodule add <repository_url> <submodule_path>
repository_url:克隆子模块的Url地址:ssh/http的都可以,默认拉取master分支
submodule_path: 位于主模块的那个目录位置,默认和src同级,
执行add指令后,主要是两个步骤:
- 会拉取配置git仓库的默认分支和merged状态的最新commit,并克隆在主模块的指定目录中,(为了保证子模块的可追述性和稳定性,git默认拉取远程仓库的merge状态下最新的commit,不支持直接配置commit hash来获取指定提交,可以在主模块手动chekout到指定commit)
- 添加引用,会将克隆基于的commit hash、URL、Branch等配置信息记录在主模块的.gitmodule文件(新建)中以及主模块的索引.git文件夹中记录当前子模块的 commit hash。
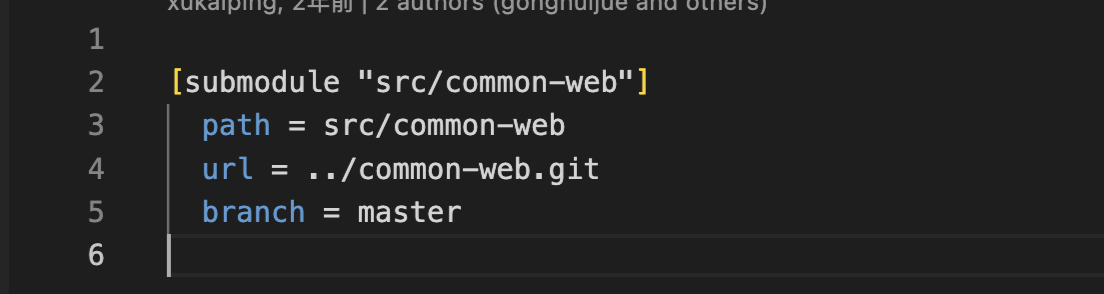
.gitmodule文件:
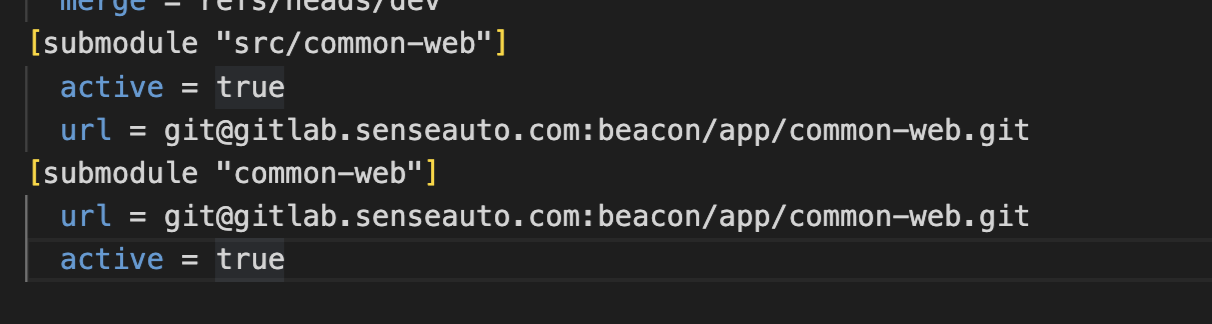
.git/config文件:
这里就有一个疑问,为啥要将子模块信息放在这两个地方:
- .gitmodules: 主要用于描述项目中的子模块信息,并且这个文件是版本化的,会根据主模块提交到远程。因此,当其他人克隆主模块时,他们会得到相同的 .gitmodules 文件内容,可以正确地初始化子模块。
- .git/config: 包含子模块的本地配置,主要用于本地环境的配置。每次你初始化或add更新子模块时,这个文件会被自动更新。
执行git ls-tree HEAD查看克隆的子模块文件夹会显示类似这样的信息:
160000 commit d6032c3e83106319e5410738055071954193724a common-web
- 各部分含义
- 160000 :
- 这个数字是文件模式(file mode),160000 表示这是一个 Git 子模块(submodule)。
- 在 Git 中,常见的文件模式包括:
- 100644:普通文件(非可执行)
- 100755:可执行文件
- 120000:符号链接
- 160000:子模块
- 040000: 文件目录
- commit :
- 这表明后面跟随的是一个 Git commit hash,这个 hash 引用的是子模块 common-web 在主模块中的特定版本。
- 在普通的 git ls-tree 输出中,这个位置可能是 blob(表示文件)或 tree(表示目录)。对于子模块,它是 commit。
- d6032c3e83106319e5410738055071954193724a :
- 这是子模块的 commit hash,它标识了子模块 common-web 的特定版本(提交)。确保当子模块有更新时,主模块能拉取正确的子模块信息。
- common-web :
- 这是文件名。在这里,common-web 是子模块在主模块中的目录名。
2、开发之后提交代码
由于子模块是独立的git仓库,所以每次更新子模块之后要回到主模块,通过git add .来更新主模块对子模块的引用,然后通过commit、push操作,将子模块记录跟着主模块提交到远程,以便其他人拉取主模块时也能获取正确的子模块内容
git add: 如果子模块有更改,会在本地.git配置中更新子模块的应用commit hash...
git commit: 会将子模块的引入和主模块一起commit,即占位的空白文件夹。
3、克隆主模块
克隆主模块之后,子模块是一个空白文件夹,commit类型的引用链接。需要init、update拉取子模块代码
- git submodule init: 读取commit hash和.gitmodule文件信息,更新主模块中.git配置文件,以便知道在哪里拉取子模块代码
- git submodule update:根据本地.git配置拉取子模块的特定commit。
4、总结
不管在主模块还是在子模块,只要子模块有更新,主模块都要更新子模块的引用才能获取到最新的代码,所以使用git submodule来进行多模块开发进行子模块更新时,一般需要两步:
- 在子模块 B 中进行更改和提交:
- 进入子模块 B 的目录。
- 进行代码更改、添加文件到暂存区,并提交到子模块 B 的仓库。
- 这些提交只会影响子模块 B 自身,不会自动更新主项目 A 中的子模块引用。
- 在主项目 A 中更新子模块 B 的引用:
- 进入主项目 A 的根目录。
- 更新子模块的引用,使其指向子模块 B 的最新提交。
- 将这个子模块引用的更改提交到主项目 A 的仓库。
整体流程图:
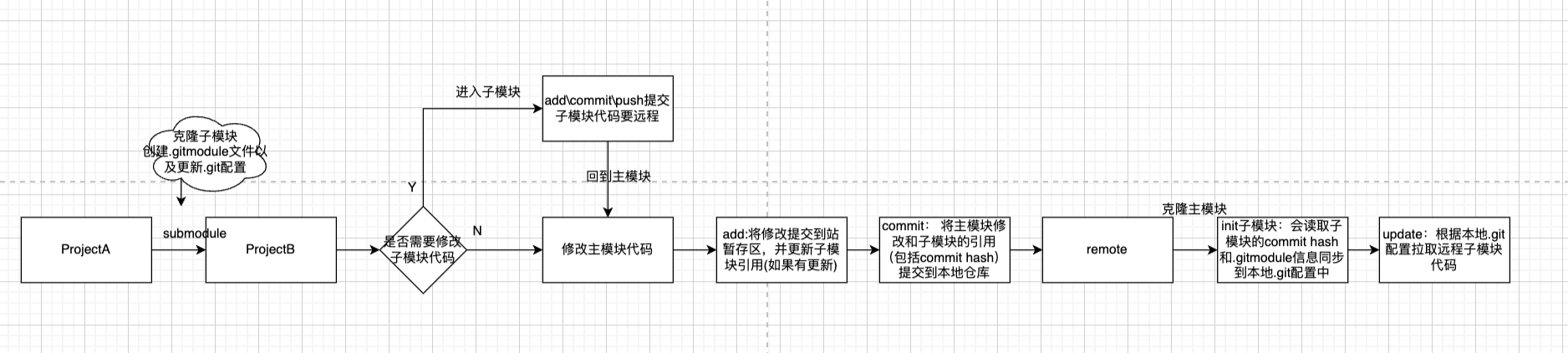
PS: 每次更新子模块都要进入子模块,然后回到主模块在更新引用,很麻烦。
5、常用指令合集
// 子模块初始化
git submodule init
// 子模块更新
git submodule update
// 更新某个子模块代码
git submodule update --remote path/to/submodule
// 更新主模块下所有子模块代码
git submodule update --remote
// 子模块更新之后,同步主模块更新子模块的引用commit hash
git add .
// 递归克隆整个项目submodule
// --recursive表示递归地克隆git_parent依赖的所有子版本库。
git clone https://github.com/demo.git assets --recursive
// 递归更新整个项目submodule
git submodule foreach git pullgit subtree
因为submodule有着每次更新子模块都要进入子模块然后回到主模块并同步主模块更新子模块引用,并且克隆主模块时需要依赖.gitmodule等配置拉取子模块,比较麻烦。为了避免这个,第三方基于Git底层开发了git subtree工具脚步来解决,Git在1.7.11版本后包含在发行版中。
git subtree采用合并的方式,将子模块代码作为普通文件夹直接合并到主模块的目录,这样就提供了主模块完全控制子模块的能力,可以直接在主模块对子模块进行修改更新,然后推送到子模块B的仓库,其他引入模块B的主模块通过更新即可获取最新的模块B代码。然后本地子模块的更新会随着主模块一起上传到远程。
1、问题以及解决
由于是合并的方式,所以主模块会随着引入子模块的增多,而导致主模块代码变得冗余,并且合并子模块也会将子模块所有的历史记录合并到主模块中,会导致主模块历史记录混乱。
随着引入子模块导致主模块代码增多,合理配置目录结构,将子模块和主模块结构清晰划分,更好的管理文件。
子模块合并历史记录导致主模块历史记录混乱:
- 使用工具过滤历史记录: 可以使用 Git 提供的工具(如 git log --submodule 或者 git log --grep=)来过滤和查看主模块与子模块的提交记录,避免混淆。
- 分支和标签的策略性使用: 在主模块中,可以使用分支和标签来标识子模块合并的时间点和版本。以便于更好地追踪和管理子模块的合并历史。
2、指令合集
// 主模块引入子模块
// --prefix 指定了子项目 B 应该放在主项目 A 中的哪个子目录。
// --squash 将子项目 B 的所有历史记录合并为一个提交,以减少主项目 A 的历史记录复杂性。
git subtree add --prefix=path/to/moduleB https://example.com/repoB.git main --squash
// 提交子模块代码
git subtree push --prefix=path/to/moduleB <remote-url> <branch>
// 拉取子模块代码
git subtree pull --prefix=path/to/moduleB <remote-url> <branch>
// 更新主模块下所有子模块代码
git submodule update --remotegit submodule和git subtree的区别
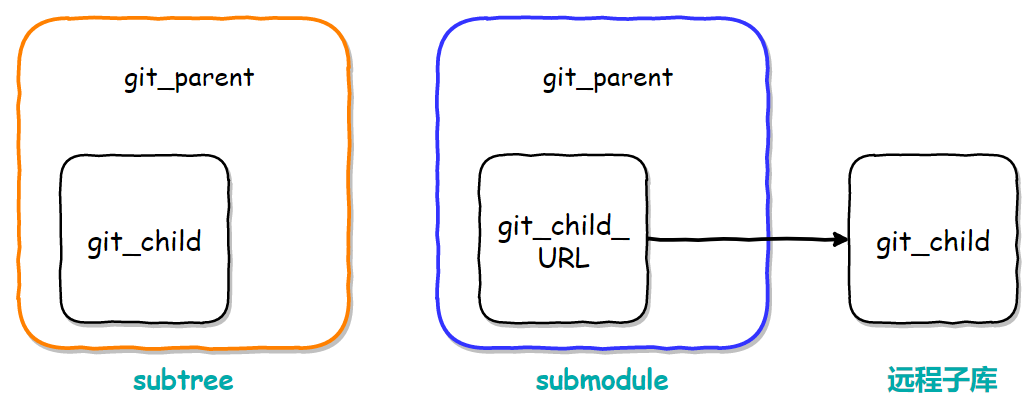
上图可知,主要区别:
1、subtree是将子模块合并到主模块中,完全属于主模块,会和主模块一起提交到远程。而submodule是将子模块作为独立仓库通过.gitmodule配置链接到主模块的,主模块提交的是子模块的引用。
2、使用上subtree可以完全受主模块控制,而submodule需要进入子模块然后进行更新,之后再回到主模块同步更新引用。
- Git Submodule :
- 子模块的代码独立存在,主模块只记录子模块的特定版本(commit hash)。
- 推送主模块时,不包含子模块的实际代码,只推送子模块的引用更新。
- 子模块的实际代码变动需要单独推送到子模块的远程仓库。
- Git Subtree :
- 子模块的代码整合到主模块中,成为主模块代码的一部分。
- 推送主模块时,子模块的代码和主模块的代码一起推送到远程仓库。
- 子模块的历史记录和变动直接体现在主模块的提交中。
简单理解为:submodule is link(commit hash), subtree is copy