Hadoop是一个分布式系统基础架构,主要用于大数据的存储和处理。它允许使用简单的编程模型跨集群处理和生成大数据集。Hadoop主要由HDFS(Hadoop Distributed FileSystem,分布式文件系统)和MapReduce编程模型两部分组成。
准备工作
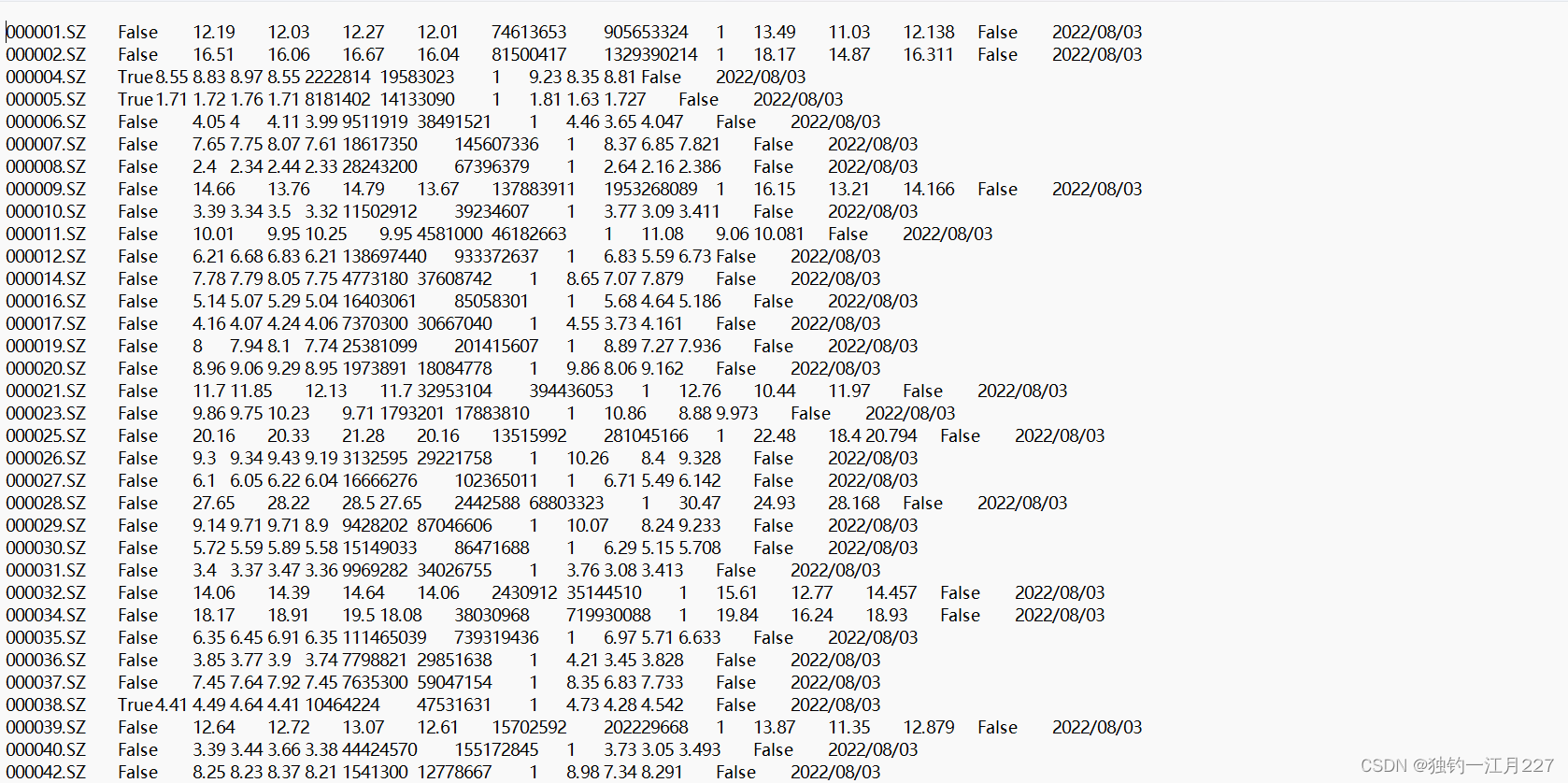
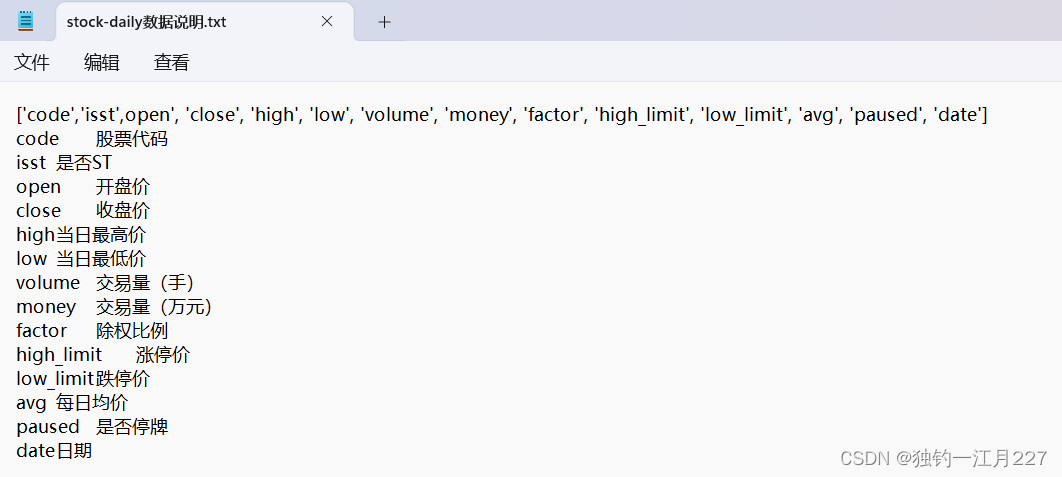
首先查看数据集(一小部分数据和示例)
配置pom文件和建包
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>stock_daily</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.2</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-configuration2</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
</project>
代码
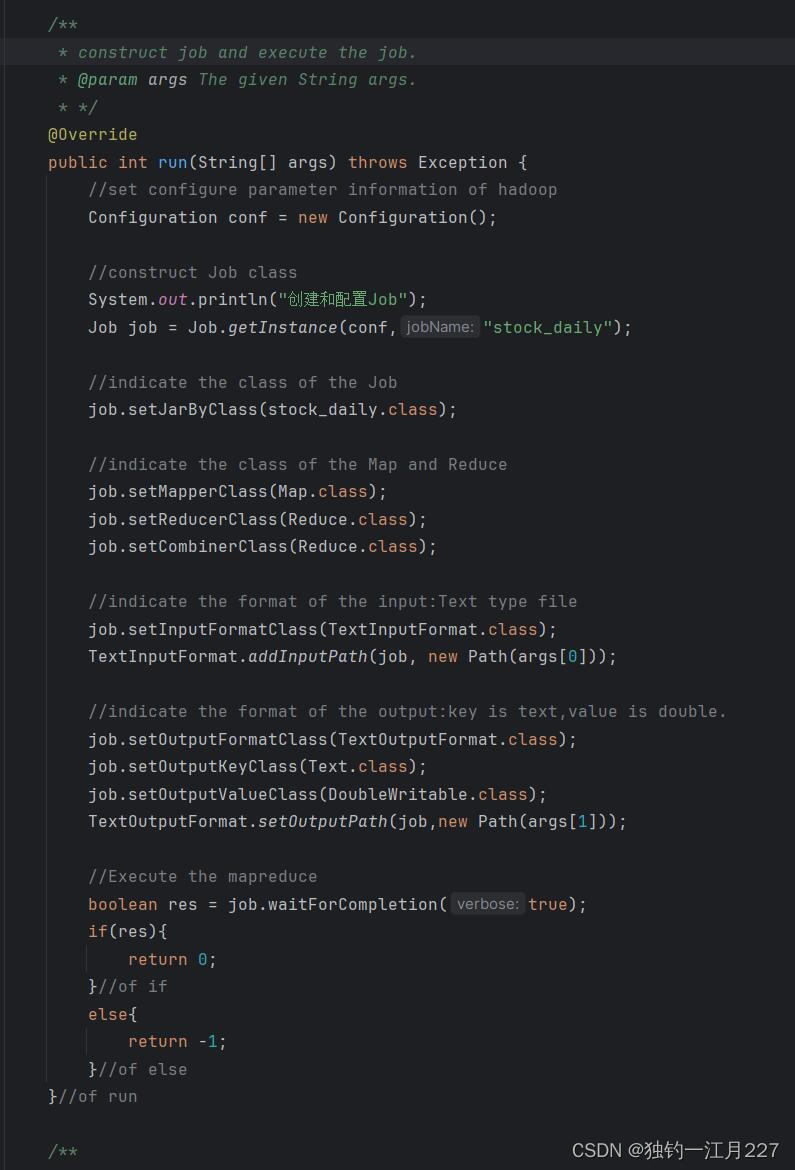
创建一个类继承 Configured 实现 Tool 接口, configured 类可以帮助 hadoop 命令行工具管理配置文件,如 yarn-site.xml 和 mapred-site.xml 。 Tool 接口中的 ToolRunner 是程序的入口点,可以启动 run 方法并把命令行的参数传给 run 。

重写 run 方法,创建 job 和配置 map 和 reduce 类。这个 configurition 就是用来管理 hadoop 的配置文件的类。 args 是命令行输入的参数,虚拟机会把它读进来。
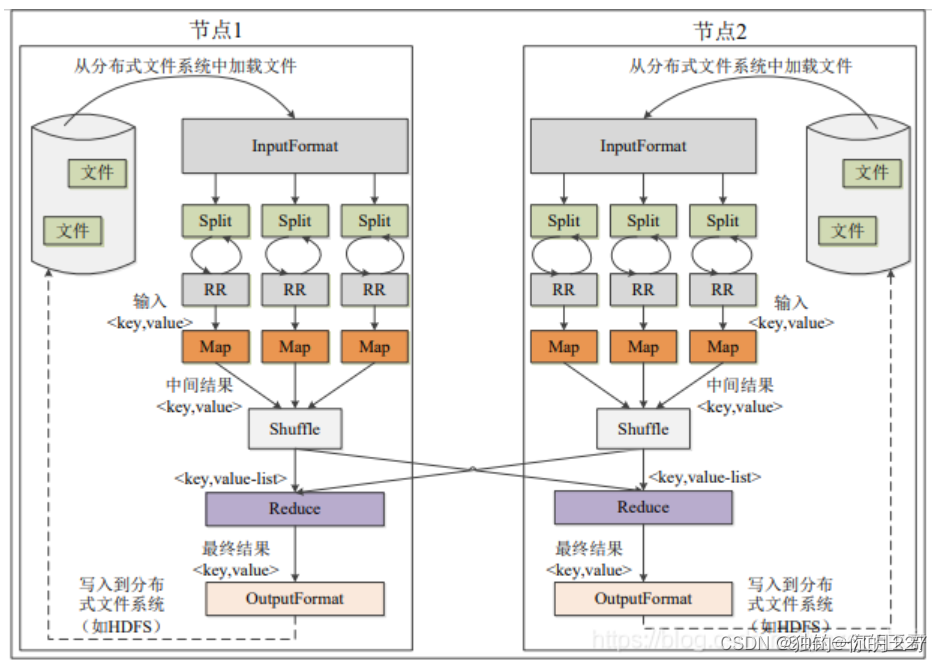
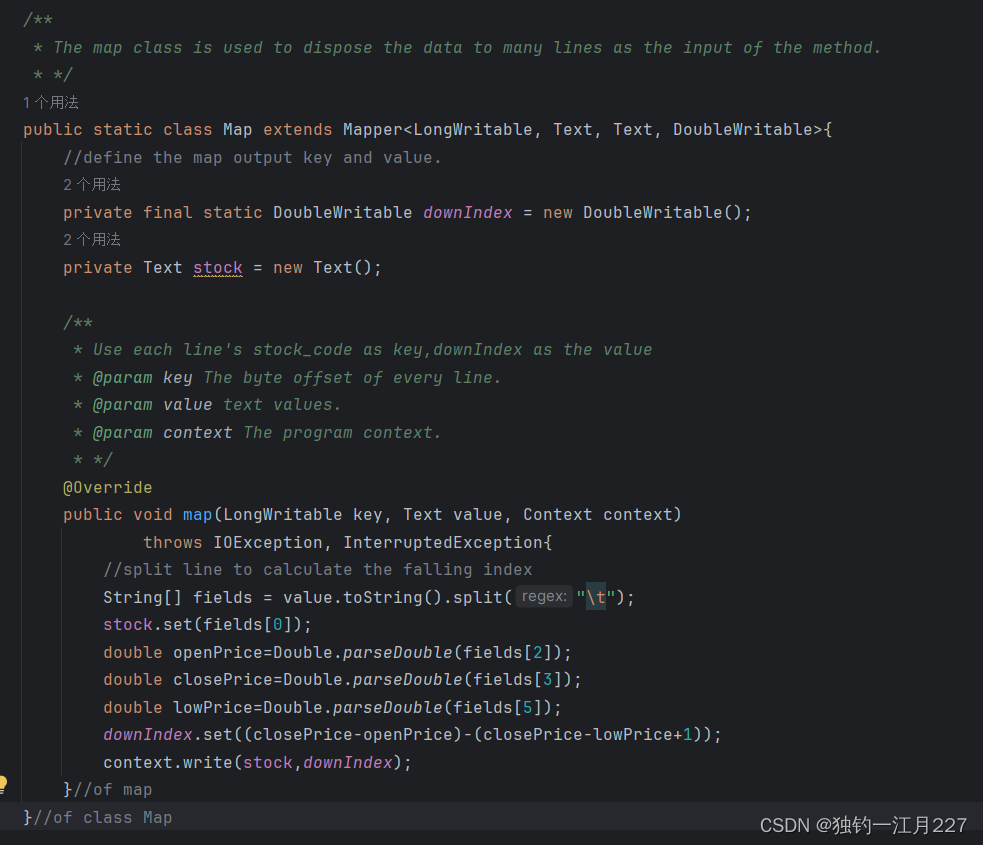
Mapper 类以及 map 方法
Mapper 类会将文件按行切分,然后把每一行的字节偏移量作为建,每一行的数据作为值交给 map 方法。 Map 方法把里面的内容取出来求下行指数,下行指数 = ((收盘价-开盘价) / (收盘价 - 最低价+1)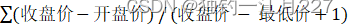 。然后将股票代码作为键,每一行的下行指数作为值写入 context 中,作为后面 reduce 的输出。 context.write 用于写入输出数据。
。然后将股票代码作为键,每一行的下行指数作为值写入 context 中,作为后面 reduce 的输出。 context.write 用于写入输出数据。
Reduce 类和 reduce 方法
Shuffile 会把 map 输出文件下载过来,然后会自动根据键,聚合到一个容器里面,遍历求和并计算平均的下行指数即可。
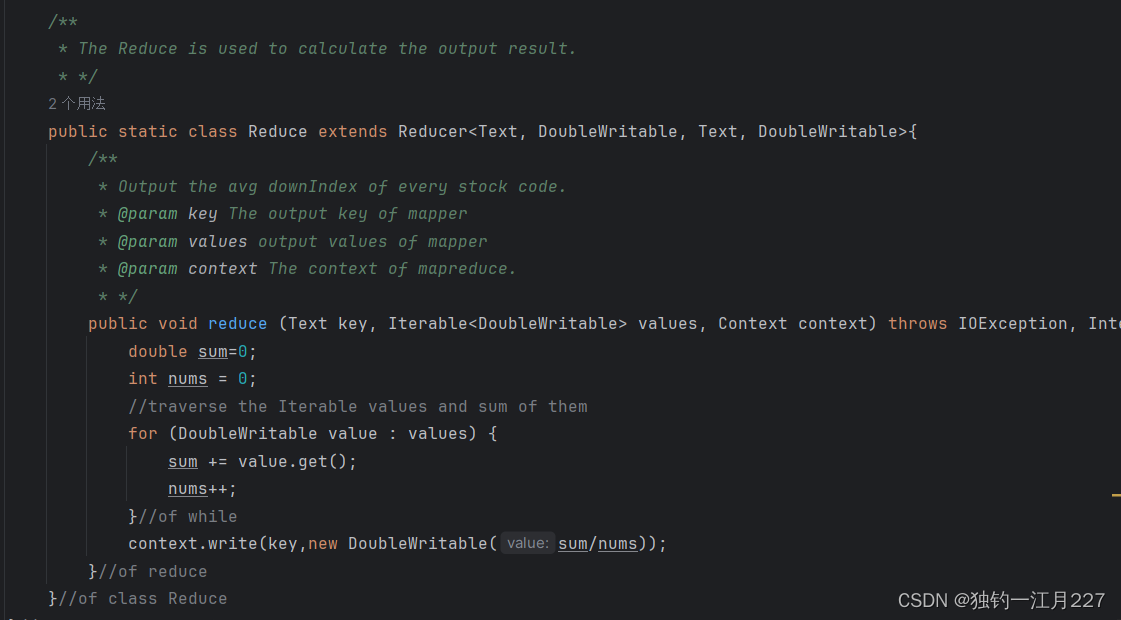
完整代码
java
package com.zlh;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* calculate and output the code and danger values of stock.
* */
public class stock_daily extends Configured implements Tool {
/**
* The entrance of the program.
* @param args is used as the parameter of run method.
* */
public static void main(String[] args) throws Exception {
//run the stock_daily as a mapreduce job.
int res = ToolRunner.run(new stock_daily(),args);
//close the JVM
System.exit(res);
}//of main
/**
* construct job and execute the job.
* @param args The given String args.
* */
@Override
public int run(String[] args) throws Exception {
//set configure parameter information of hadoop
Configuration conf = new Configuration();
//construct Job class
System.out.println("创建和配置Job");
Job job = Job.getInstance(conf,"stock_daily");
//indicate the class of the Job
job.setJarByClass(stock_daily.class);
//indicate the class of the Map and Reduce
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setCombinerClass(Reduce.class);
//indicate the format of the input:Text type file
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path(args[0]));
//indicate the format of the output:key is text,value is double.
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
TextOutputFormat.setOutputPath(job,new Path(args[1]));
//Execute the mapreduce
boolean res = job.waitForCompletion(true);
if(res){
return 0;
}//of if
else{
return -1;
}//of else
}//of run
/**
* The map class is used to dispose the data to many lines as the input of the method.
* */
public static class Map extends Mapper<LongWritable, Text, Text, DoubleWritable>{
//define the map output key and value.
private final static DoubleWritable downIndex = new DoubleWritable();
private Text stock = new Text();
/**
* Use each line's stock_code as key,downIndex as the value
* @param key The byte offset of every line.
* @param value text values.
* @param context The program context.
* */
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
//split line to calculate the falling index
String[] fields = value.toString().split("\t");
stock.set(fields[0]);
double openPrice=Double.parseDouble(fields[2]);
double closePrice=Double.parseDouble(fields[3]);
double lowPrice=Double.parseDouble(fields[5]);
downIndex.set((closePrice-openPrice)-(closePrice-lowPrice+1));
context.write(stock,downIndex);
}//of map
}//of class Map
/**
* The Reduce is used to calculate the output result.
* */
public static class Reduce extends Reducer<Text, DoubleWritable, Text, DoubleWritable>{
/**
* Output the avg downIndex of every stock code.
* @param key The output key of mapper
* @param values output values of mapper
* @param context The context of mapreduce.
* */
public void reduce (Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
double sum=0;
int nums = 0;
//traverse the Iterable values and sum of them
for (DoubleWritable value : values) {
sum += value.get();
nums++;
}//of while
context.write(key,new DoubleWritable(sum/nums));
}//of reduce
}//of class Reduce
}//of class stock_daily上传集群并执行
将项目文件打包为 jar 包上传至 hadoop 集群中(打包方式参照Hadoop应用1)
在 windows 的命令提示符里面使用 pscp 命令上传 jar 包(前提是已经安装了 putty )


文件夹也可以通过这个方式传,要在 pscp 后面加个 -r 。
启动集群后使用 hadoop jar 输入文件位置(要在 hdfs 里面,不是在 linux 里面) 输出文件目录,会报找不到类的错,要修改两个配置文件。
XML
1、mapred-site.xml
增加两个配置:
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
2、yarn-site.xml
增加container本地日志查看配置
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>hadoop安装目录/logs/userlogs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>108000</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value> <!--此项小于1536,mapreduce程序会报错-->
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value> <!--防止一级调度器请求资源量过大-->
</property>
设置虚拟内存与内存的倍率,防止VM不足Container被kill
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
以上配置确认无误后,如果仍有报内存错误、AM错误、卡Job、卡0%等问题找不到原因,可以尝试按以下方式解决:
(相应属性的设置为HA模式设置)
(1)mapred-site.xml
将mapreduce.framework.name改为:
------------------------------------
vix.mapreduce.framework.name
yarn
------------------------------------
(2)yarn-site.xml
将yarn.resourcemanager.address改为:
------------------------------------
vix.yarn.resourcemanager.address
主节点地址:18040
------------------------------------
将yarn.resourcemanager.scheduler.address改为:
------------------------------------
vix.yarn.resourcemanager.scheduler.address
主节点地址:18030
------------------------------------文件位置以及路径如下图所示
修改之后把文件传到另外两个节点,然后重新启动集群

然后执行 jar 包(要先把数据上传到hadoop集群中,使用hdfs dfs -put命令)
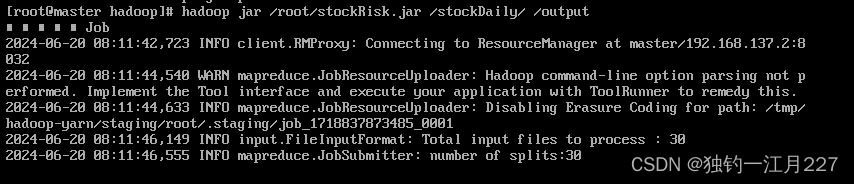
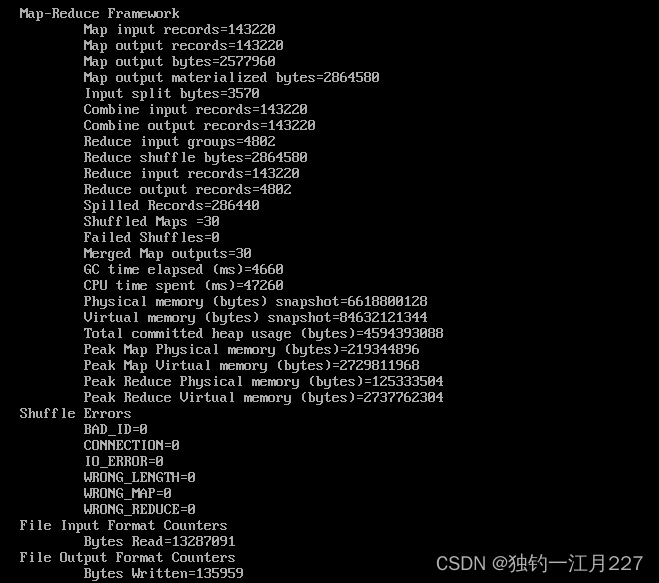
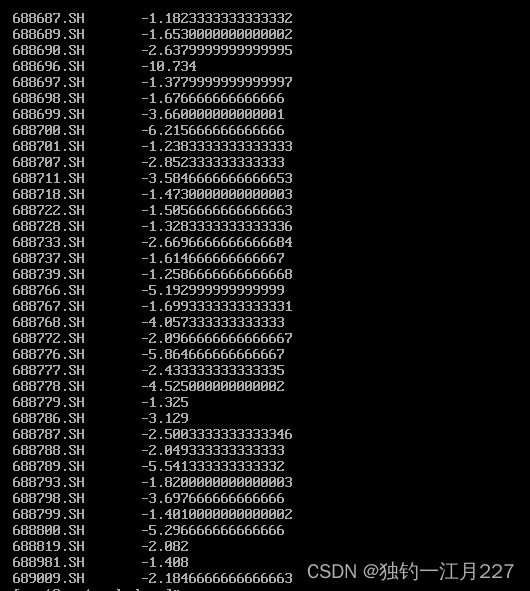
试验运行过程及结果

ps:hadoop执行jar包出现问题可以在日志文件里面找报错。在logs里面的resourcemanager里面。