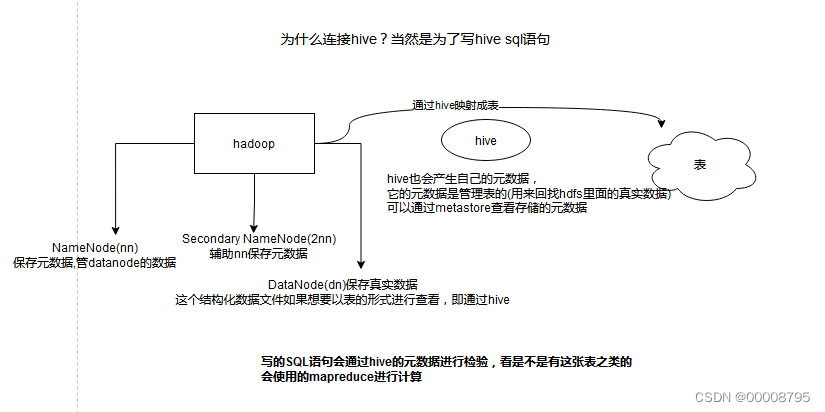
hadoop和hive的关系
hadoop 启动
- cd到指定目录下
powershell
cd /opt/module/hadoop-3.3.0/sbin/- 启动文件
powershell
./start-all.sh- jps一下,查看显示的内容
应该显示以下内容
powershell
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager- 如果缺少namenode,那么执行
powershell
rm -rf /tmp/hadoop-hadoop/dfs/name/*
hadoop namenode -format
cd /opt/module/hadoop-3.3.0/sbin/
./stop-all.sh
./start-all.sh- 如果缺少datanode,那么执行
powershell
rm -rf /tmp/hadoop-hadoop/dfs/data/*
hadoop datanode -format
./stop-all.sh
./start-all.sh
jpshive启动
在hadoop启动的前提下执行
- hive查看下
powershell
hive- 到指定路径下
powershell
cd /opt/module/apache-hive-2.1.1-bin/bin/hive- hive
powershell
hive
- hive\退出;quit或者exit
DBeaver启动
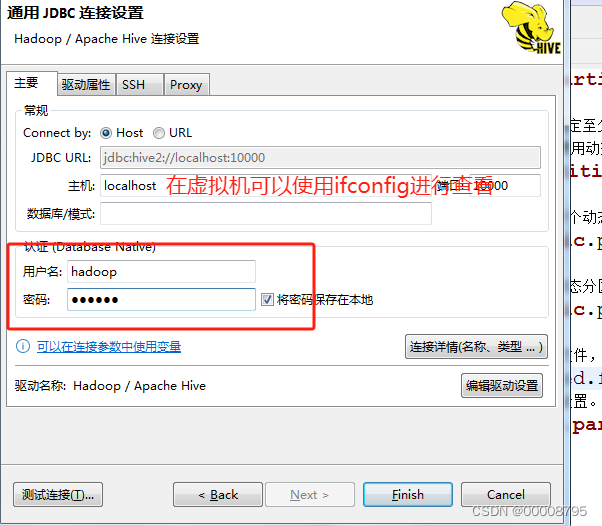
使用JDBC方式连接hive
- 首先启动hiveserver2服务
powershell
screen -S hive --创建一个虚拟屏
hive --service hiveserver2
ctrl+a+d --退出虚拟屏- 打开DBeaver新建一个连接

-
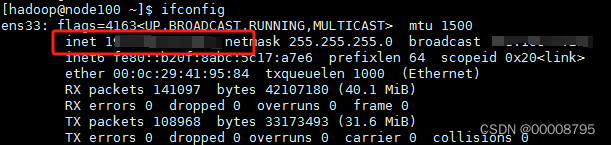
填写主机,填写用户名和密码
-
编辑驱动设置
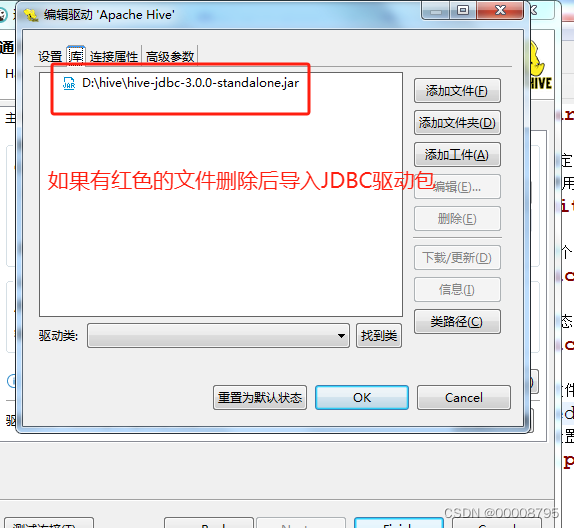
-
导入后测试连