SparkCore学习(一)
一 .Spark概述
二.Spark运行模式
文章目录
- SparkCore学习(一)
- 前言
- 一、Spark概述
- 二、Spark运行模式
-
- 1.Spark运行模式
- [2.Spark Standalone架构](#2.Spark Standalone架构)
-
-
- [Spark Standalone的两种提交方式](#Spark Standalone的两种提交方式)
-
- [Spark Standalone模式的搭建](#Spark Standalone模式的搭建)
- [三、Spark On YARN架构](#三、Spark On YARN架构)
-
-
-
- [Spark On YARN的两种提交方式](#Spark On YARN的两种提交方式)
- [Spark On YARN模式的搭建](#Spark On YARN模式的搭建)
-
-
前言
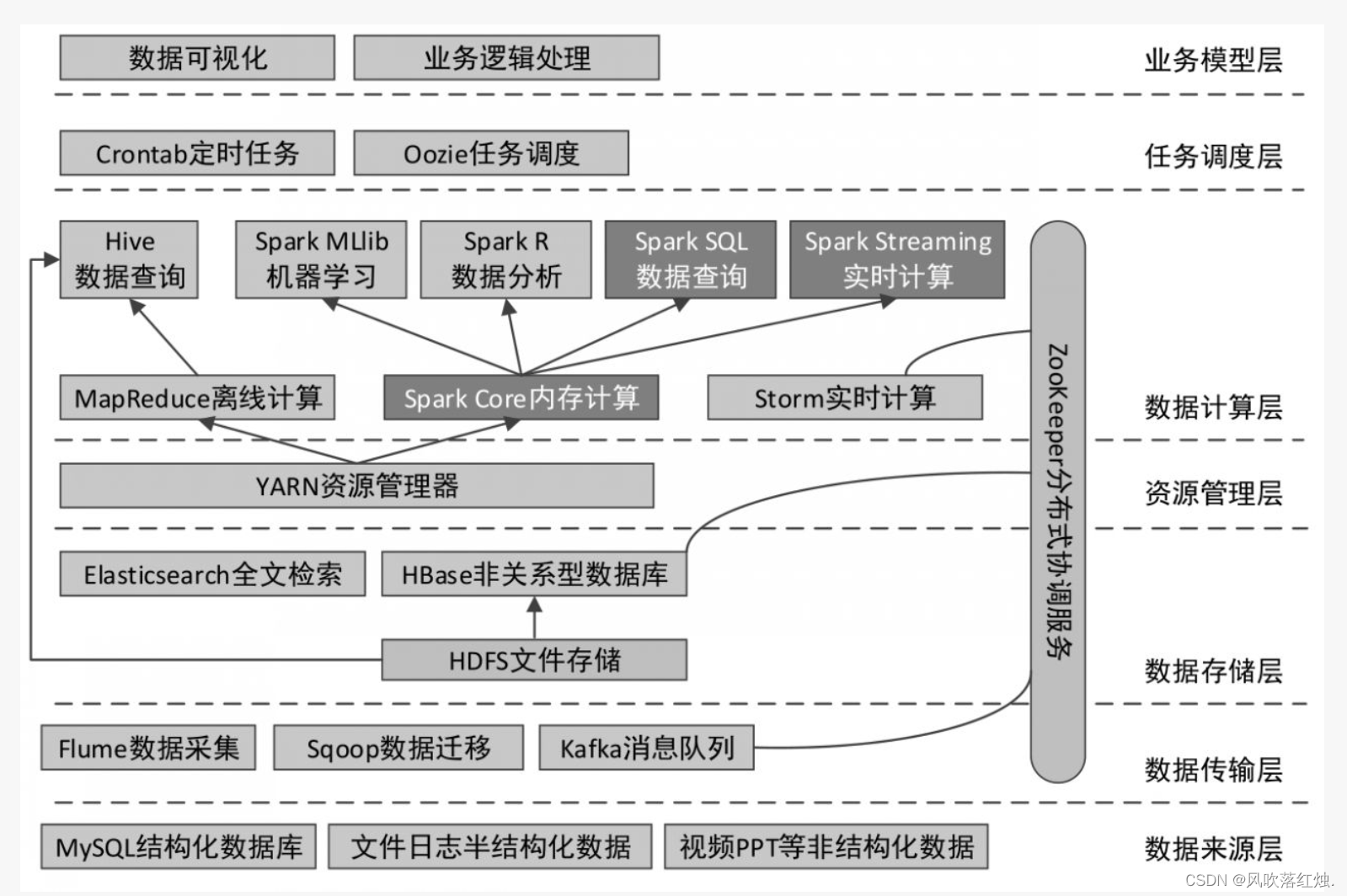
在数据计算层,作为Hadoop核心组成的MapReduce可以结合Hive通过类SQL的方式进行数据的离线计算(当然也可以编写独立的MapReduce应用程序进行计算);而Spark既可以做离线计算(Spark SQL),又可以做实时计算(Spark Streaming),它们底层都使用的是Spark的核心(Spark Core)。
一、Spark概述
Apache Spark是一个快速通用的集群计算系统,是一种与Hadoop相似的开源集群计算环境,但是Spark在一些工作负载方面表现得更加优越。它提供了Java、Scala、Python和R的高级API,以及一个支持通用的执行图计算的优化引擎。它还支持高级工具,包括使用SQL进行结构化数据处理的Spark SQL、用于机器学习的MLlib、用于图处理的GraphX,以及用于实时流处理的Spark Streaming。
Spark的主要特点
- 快速
MapReduce主要包括Map和Reduce两种操作,且将多个任务的中间结果存储于HDFS中。与MapReduce相比,Spark可以支持包括Map和Reduce在内的多种操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph, DAG),各个操作的中间数据会被保存在内存中。因此,Spark处理速度比MapReduce更快。
- 易用
Spark可以使用Java、Scala、Python、R和SQL快速编写应用程序。此外,Spark还提供了超过80个高级算子,使用这些算子可以轻松构建应用程序。
- 通用
Spark拥有一系列库,包括SQL和DataFrame、用于机器学习的MLlib、用于图计算的GraphX、用于实时计算的Spark Streaming,可以在同一个应用程序中无缝地组合这些库。
- 到处运行
Spark可以使用独立集群模式运行(使用自带的独立资源调度器,称为Standalone模式),也可以运行在Hadoop YARN、Mesos(Apache下的一个开源分布式资源管理框架)等集群管理器之上,并且可以访问HDFS、HBase、Hive等数百个数据源中的数据。
Spark的主要组件
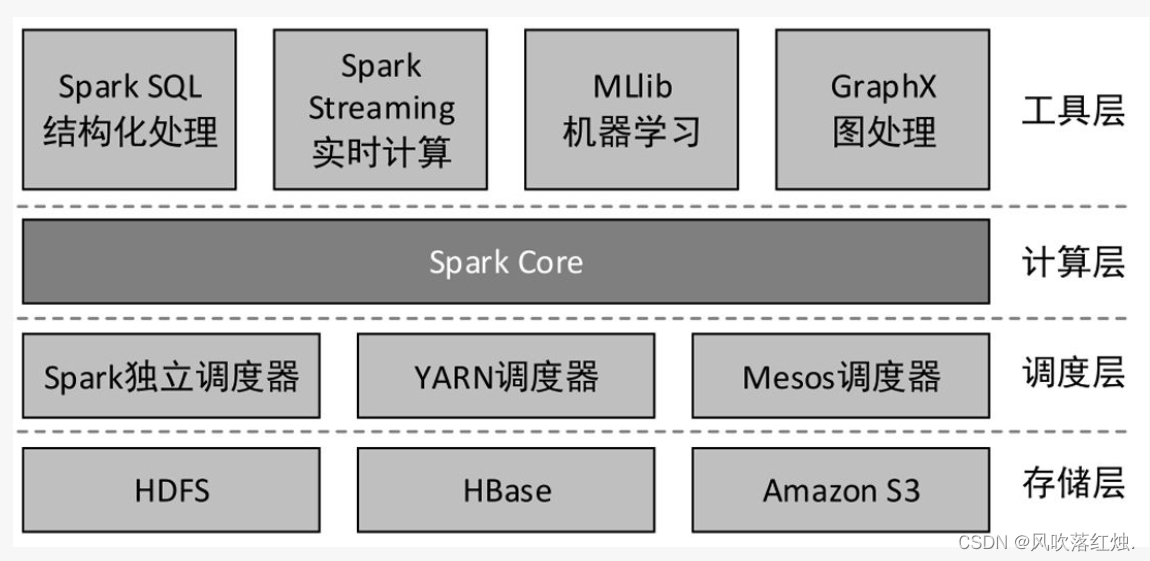
Spark是由多个组件构成的软件栈,Spark 的核心(Spark Core)是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎。
Spark安装
下载解压缩spark-3.3.3-bin-hadoop3.tgz,重命名Spark安装目录为spark,在配置文件/etc/profile中添加:
bash
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin执行/etc/profile脚本,使配置生效
bash
source /etc/profile二、Spark运行模式
1.Spark运行模式
Spark主要有三种运行模式:
- 本地(单机)模式
本地模式通过多线程模拟分布式计算,通常用于对应用程序的简单测试。本地模式在提交应用程序后,将会在本地生成一个名为SparkSubmit的进程,该进程既负责程序的提交,又负责任务的分配、执行和监控等。
- Spark Standalone模式
使用Spark自带的资源调度系统,资源调度是Spark自己实现的。
- Spark On YARN模式
以YARN作为底层资源调度系统以分布式的方式在集群中运行。
2.Spark Standalone架构
Spark Standalone的两种提交方式
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用--deploy-mode参数指定提交方式。
- client提交方式
当提交方式为client时,运行架构如下图所示:
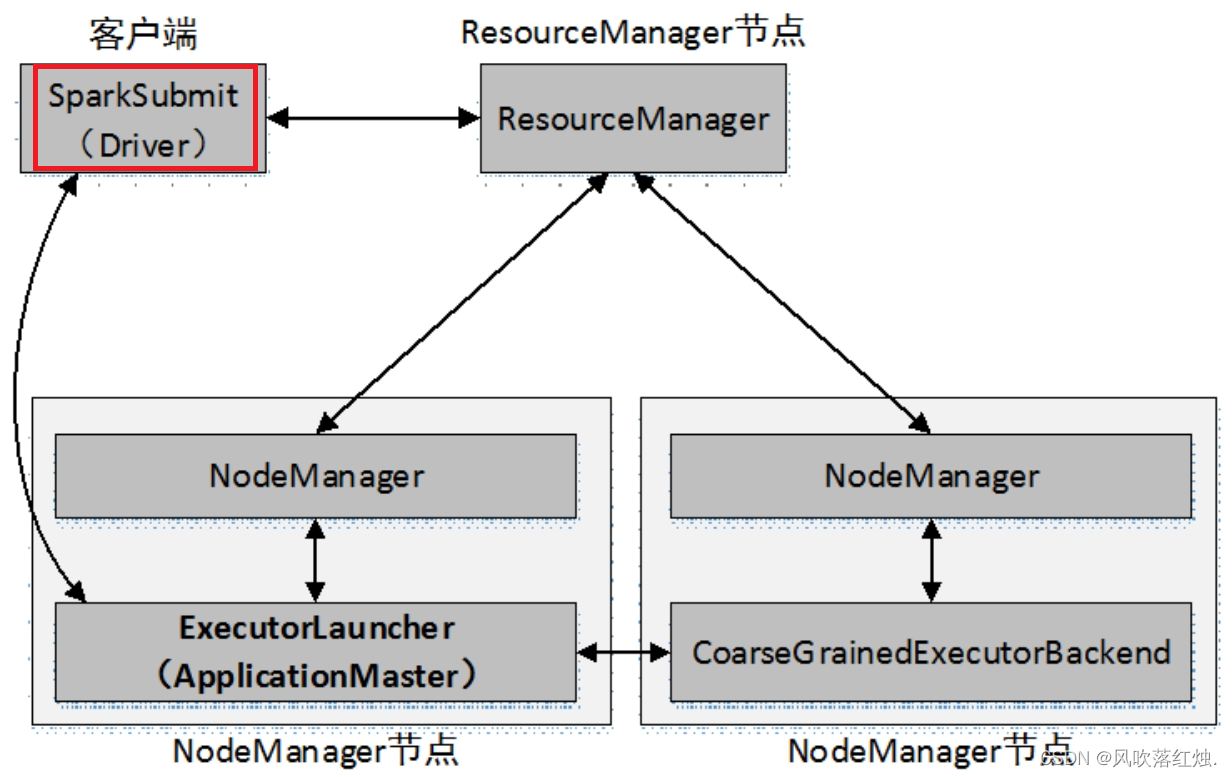
集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程。
Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。如图所示的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。
- cluster提交方式
当提交方式为cluster时,运行架构如下图所示:
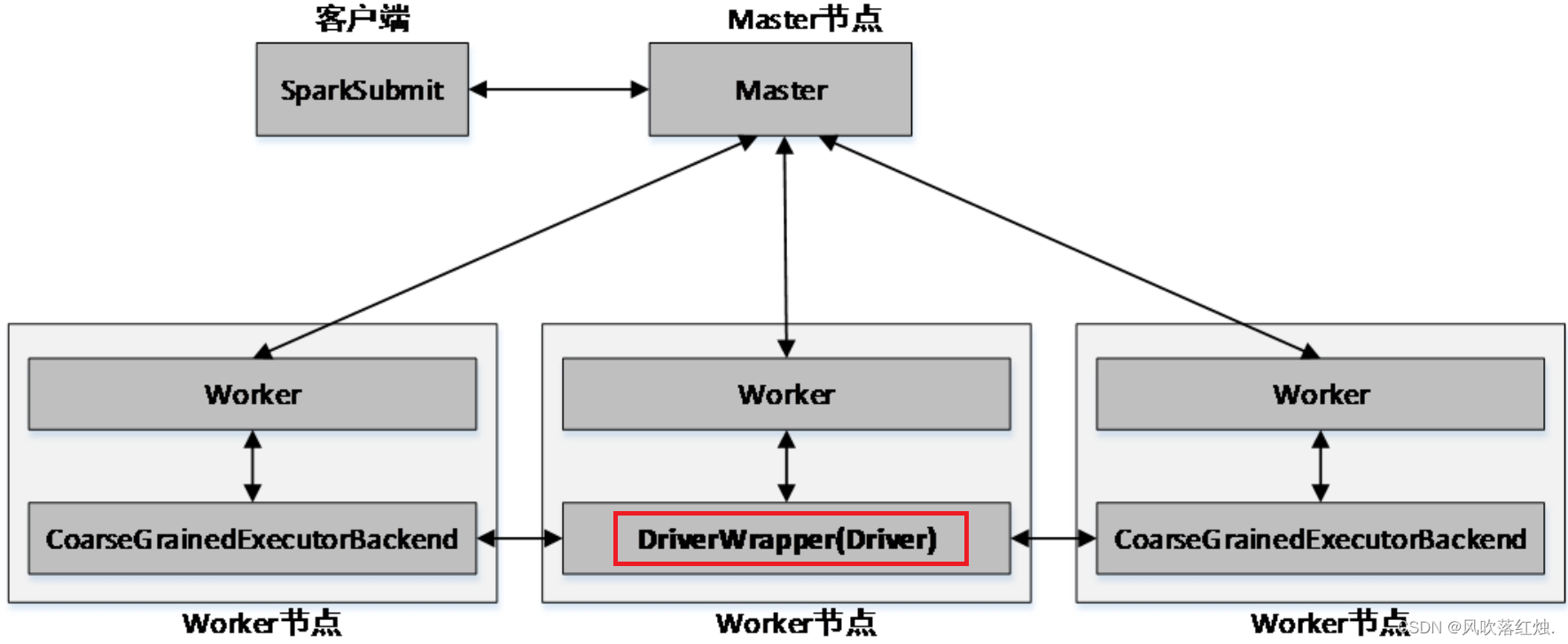
Standalone以cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker启动一个名为DriverWrapper的子进程,该子进程即为Driver进程。
Spark Standalone模式的搭建
进入Spark安装根目录,进入conf目录,执行以下操作:
(1):复制spark-env.sh.template文件为spark-env.sh文件
bash
cp spark-env.sh.template spark-env.sh(2): 修改spark-env.sh文件,添加以下内容:
bash
export JAVA_HOME=/export/servers/jdk1.8.0_161
export SPARK_MASTER_HOST=my2308-host
export SPARK_MASTER_PORT=7077- JAVA_HOME:指定JAVA_HOME的路径。若节点在/etc/profile文件中配置了JAVA_HOME,则该选项可以省略,Spark启动时会自动读取。为了防止出错,建议此处将该选项配置上。
- SPARK_MASTER_HOST:指定集群主节点(Master)的主机名。
- SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
(3): 启动Spark集群
进入Spark安装目录,执行以下命令,启动Spark集群:
bash
sbin/start-all.sh启动完毕后,分别在各节点执行jps命令,查看启动的Java进程。若存在Master进程和Worker进程,则说明集群启动成功。
三、Spark On YARN架构
Spark On YARN的两种提交方式
Spark On YARN模式遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己决定,因此可能在YARN上同时运行MapReduce程序和Spark程序,YARN对每一个程序很好地实现了资源的隔离。这使得Spark与MapReduce可以运行于同一个集群中,共享集群存储资源与计算资源。
Spark On YARN模式与Standalone模式一样,也分为client和cluster两种提交方式。
Spark On YARN模式的搭建
Spark On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。Spark本身的Master节点和Worker节点不需要启动。
使用此模式需要修改Spark配置文件$SPARK_HOME/conf/spark-env.sh,添加Hadoop相关属性,指定Hadoop与配置文件所在目录,内容如下:
bash
export HADOOP_HOME=/export/servers/hadoop-3.2.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop