- 练习基本运算:
v <- c (2,4,6,9)
t <- c (1,4,7,9)
print (v>t)
print (v < t )
print (v == t )
print (v!=t )
print (v>=t )
print (v<=t )
v <- c (3,1,TRUE,2+3i)
t <- c (4,1,FALSE,2+3i)
print (v&t)
print (v|t)
print (!v)
v <- c (3,0,TRUE,2+2i)
t <- c (1,3,TRUE,2+3i)
print (v&&t)
v <- c (0,0,TRUE,2+2i)
t <- c (0,3,TRUE,2+3i)
print (v||t)
v <- c (0,0,TRUE,2+2i)
t <- c (0,3,TRUE,2+3i)
print (v||t)
- 使用转义符,用cat ()在控制台中打印出下列格式的输出
To have a \ you need \\
This is a really
really really
long string
- 创建一个对象,并进行数据类型的转换、判别操作,步骤如下:
- 创建一个对象x,内含元素为序列:1,3,5,6,8
- 判断对象x是否为数值型数据
- 将对象转换为逻辑型数据,记为x1。将对象转换为字符型数据,记为x2
- 判断x1是否为逻辑型数据.
- 分别输出as.character(c(T,0,FALSE))和as.character(c(T,"TRUR",FALSE))的值,并描述两个值出现区别的原因.
- 构建一个数据框:
(1)将下列表格中的数据用数据框表述出来,命名为staff_table
|----|-------|-----|-----|
| 序号 | name | ID | age |
| 1 | jack | 001 | 12 |
| 2 | rose | 002 | 13 |
| 3 | jane | 003 | 14 |
| 4 | james | 006 | NA |
(2)提取staff_table的员工rose的数据
(3)提取rose、jane的ID、age数据
(4)运用数据框提取员工的年龄数据,计算均值
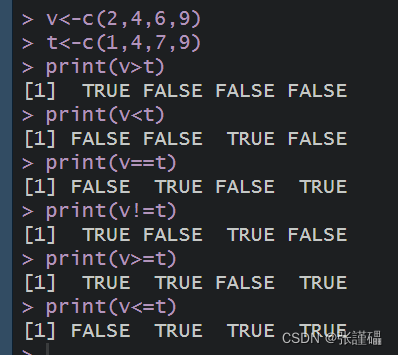
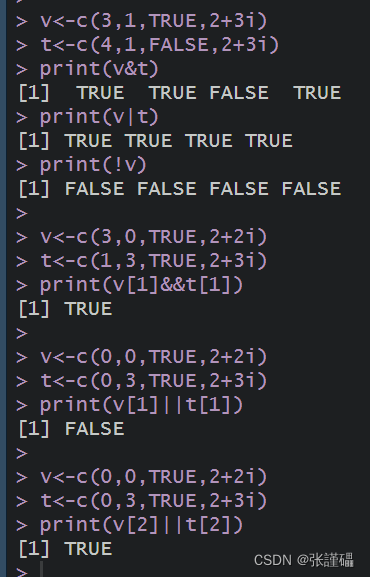
- 练习基本运算:
代码:
R
v<-c(2,4,6,9)
t<-c(1,4,7,9)
print(v>t)
print(v<t)
print(v==t)
print(v!=t)
print(v>=t)
print(v<=t)
v<-c(3,1,TRUE,2+3i)
t<-c(4,1,FALSE,2+3i)
print(v&t)
print(v|t)
print(!v)
v<-c(3,0,TRUE,2+2i)
t<-c(1,3,TRUE,2+3i)
print(v[1]&&t[1])
v<-c(0,0,TRUE,2+2i)
t<-c(0,3,TRUE,2+3i)
print(v[1]||t[1])
v<-c(0,0,TRUE,2+2i)
t<-c(0,3,TRUE,2+3i)
print(v[2]||t[2])结果:
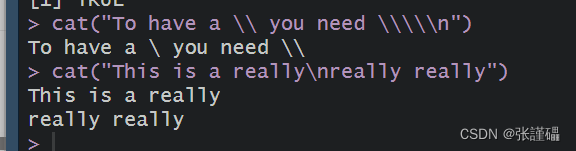
- 使用转义符,用cat ()在控制台中打印出下列格式的输出
代码:
R
cat("To have a \\ you need \\\\\n")
cat("This is a really\nreally really")截图:
- 创建一个对象,并进行数据类型的转换、判别操作,步骤如下:
- 创建一个对象x,内含元素为序列:1,3,5,6,8
代码:
R
x <- c(1, 3, 5, 6, 8)截图:

- 判断对象x是否为数值型数据
代码:
R
is_numeric <- is.numeric(x)
cat("x 是数值型数据吗?", is_numeric, "\n")截图:

- 将对象转换为逻辑型数据,记为x1。将对象转换为字符型数据,记为x2
代码:
R
# 将对象转换为逻辑型数据,记为 x1
x1 <- as.logical(x)
# 将对象转换为字符型数据,记为 x2
x2 <- as.character(x)截图:

- 判断x1是否为逻辑型数据
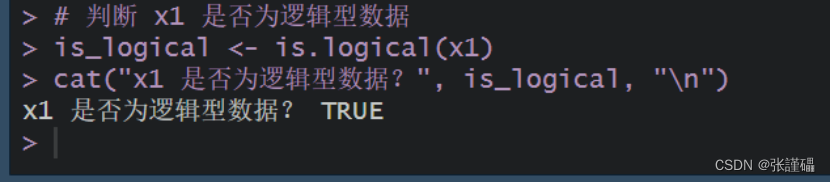
代码:
R
# 判断 x1 是否为逻辑型数据
is_logical <- is.logical(x1)
cat("x1 是否为逻辑型数据?", is_logical, "\n")截图:
- 分别输出as.character(c(T,0,FALSE))和as.character(c(T,"TRUR",FALSE))的值,并描述两个值出现区别的原因.
代码:
R
# 输出 as.character(c(T, 0, FALSE)) 的值
cat("as.character(c(T, 0, FALSE)) 的值:", as.character(c(T, 0, FALSE)), "\n")
# 输出 as.character(c(T, "TRUR", FALSE)) 的值
cat("as.character(c(T, \"TRUR\", FALSE)) 的值:", as.character(c(T, "TRUR", FALSE)), "\n")截图:

原因:
as.character(c(T, 0, FALSE)) 的值为 "TRUE" "0" "FALSE",而 as.character(c(T, "TRUR", FALSE)) 的值为 "TRUE" "TRUR" "FALSE"。这里的区别在于第二个向量中包含了一个字符型元素 "TRUR",而不是整数型元素。
在 R 语言中,逻辑值 TRUE 和 FALSE 会被转换为字符型 "TRUE" 和 "FALSE",而数字 0 会被解释为逻辑值 FALSE,最终被转换为字符型 "FALSE"。因此,在第一个向量中整数型的 0 被转换为字符型 "0",而在第二个向量中字符型的 "TRUR" 保持不变。
- 构建一个数据框:
(1)将下列表格中的数据用数据框表述出来,命名为staff_table
|----|-------|-----|-----|
| 序号 | name | ID | age |
| 1 | jack | 001 | 12 |
| 2 | rose | 002 | 13 |
| 3 | jane | 003 | 14 |
| 4 | james | 006 | NA |
代码:
R
# 创建数据框
staff_table <- data.frame(
序号 = c(1, 2, 3, 4),
name = c("jack", "rose", "jane", "james"),
ID = c("001", "002", "003", "006"),
age = c(12, 13, 14, NA)
)
# 显示数据框
print(staff_table)截图:

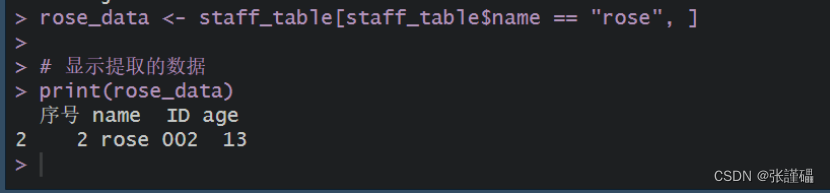
(2)提取staff_table的员工rose的数据
代码:
R
# 提取员工"rose"的数据
rose_data <- staff_table[staff_table$name == "rose", ]
# 显示提取的数据
print(rose_data)截图:
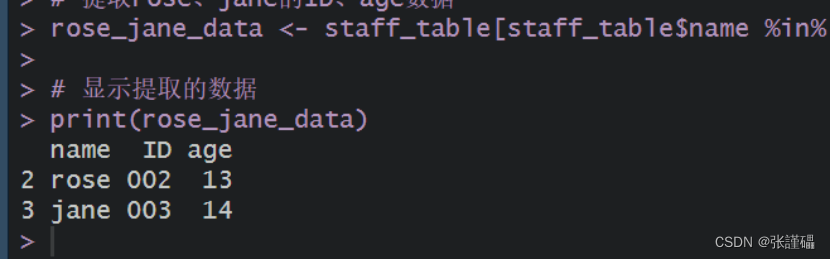
(3)提取rose、jane的ID、age数据
代码:
R
# 提取rose、jane的ID、age数据
rose_jane_data <- staff_table[staff_table$name %in% c("rose", "jane"), c("name", "ID", "age")]
# 显示提取的数据
print(rose_jane_data)截图:
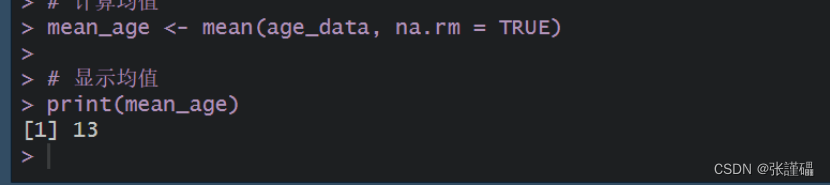
(4)运用数据框提取员工的年龄数据,计算均值
代码:
R
# 提取员工的年龄数据
age_data <- staff_table$age
# 计算均值
mean_age <- mean(age_data, na.rm = TRUE)
# 显示均值
print(mean_age)截图: