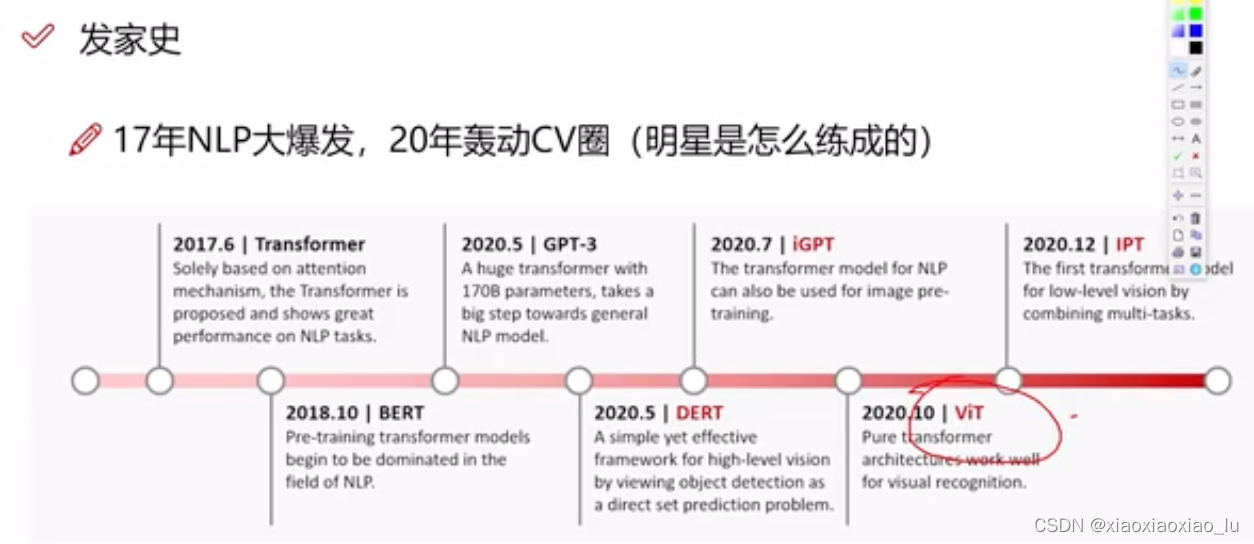
随着人工智能技术的不断发展,AI在前端设计页面中的应用变得越来越普遍。比如:在电商平台上,可以利用对象检测技术实现商品的自动识别和分类;人脸识别;车辆检测;图片识别等等......其中一个显著的应用是在图像识别中,AI算法可以检测和标记图像中的对象,增强用户体验,并在网站或应用程序上实现创新功能。
技术原理
在demo中,我们将使用 JavaScript 和 Transformers 库来实现图像对象检测的功能。图像对象检测是计算机视觉领域中的重要任务,它可以识别图像中的不同对象并标注它们的位置。我们将使用一个预训练的对象检测模型,将其集成到网页中,通过上传图片来进行对象检测,并在图片上绘制边界框以标识检测到的对象。
html
<!--
* 本demo实现的功能:
* 实现了图片上传功能,利用Transformer模型进行对象检测,并在图片上标记检测到的对象
-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>图片识别</title>
<!-- CSS 样式 -->
<style>
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap: 10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top: 20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
</style>
</head>
<body>
<!-- 页面主体内容 -->
<main class="container">
<label for="file-upload" class="custom-file-upload">
<input type="file" accept="image/*" id="file-upload">
上传图片
</label>
<div id="image-container"></div>
<p id="status"></p>
</main>
<!-- JavaScript 代码 -->
<script type="module">
// 导入transformers nlp任务的pipeline和env对象
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
// 是否允许本地模型
env.allowLocalModels = false;
// 获取文件上传和图片容器元素
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
// 监听文件上传事件
fileUpload.addEventListener('change', function (e) {
// FileReader 读取上传的图像
const file = e.target.files[0];
const reader = new FileReader();
reader.onload = function (e2) {
// 显示上传的图像
const image = document.createElement('img');
image.src = e2.target.result;
imageContainer.appendChild(image)
// 启动AI检测
detect(image)
}
reader.readAsDataURL(file)
})
// 获取状态信息元素
const status = document.getElementById('status');
// 检测图片的AI任务
const detect = async (image) => {
status.textContent = "分析中..."
const detector = await pipeline("object-detection", "Xenova/detr-resnet-50")
const output = await detector(image.src, {
threshold: 0.1, //设置了一个阈值,用于决定何时将检测结果识别为一个对象
percentage: true //检测结果的置信度会以百分比的形式返回
})
// 渲染检测到的框
output.forEach(renderBox)
}
// 渲染检测框函数
function renderBox({ box, label }) {
const { xmax, xmin, ymax, ymin } = box
const boxElement = document.createElement("div");
boxElement.className = "bounding-box"
Object.assign(boxElement.style, {
borderColor: '#123123',
borderWidth: '1px',
borderStyle: 'solid',
left: 100 * xmin + '%',
top: 100 * ymin + '%',
width: 100 * (xmax - xmin) + "%",
height: 100 * (ymax - ymin) + "%"
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label"
labelElement.style.backgroundColor = '#000000'
boxElement.appendChild(labelElement);
imageContainer.appendChild(boxElement);
}
</script>
</body>
</html>效果图